1.本发明涉及分布式流式数据计算领域,并特别涉及一种基于列存数据的流式数据处理方法及系统。
背景技术:
2.流式数据计算引擎正在逐渐兴起,并渗透至各个行业。目前,几乎所有的云服务商都提供流式数据计算引擎,可用于数据聚合、数据关联、数据监控、以及数据分析等场景。当前主流的流式数据计算引擎以apache flink、apache spark streaming、及storm等系统为代表,使用有向无环图表示用户作业,其编程模型较mapreduce更加灵活。当代流式数据计算引擎通过窗口技术实现时间维度的数据聚合,并通过事件消息实现乱序消息处理支持。
3.窗口技术简介。流式数据计算引擎使用窗口技术对数据进行时间维度聚合操作,常见的窗口包括滚动和滑动窗口。滚动时间窗口也称为固定时间窗口,以固定的时间间隔聚合数据,比如每天对数据进行汇总处理;滑动时间窗口也叫跳跃窗口,其定义一个具有固定大小,并以固定时间间隔滑动的窗口,比如可用于每天生成最近一周的统计数据表。当时间窗口大小和滑动间隔相等时,滑动时间窗口退化为滚动时间窗口,当滑动间隔小于时间窗口大小时,滑动窗口出现重叠,此时一条记录可能属于多个不同窗口;窗口操作的本质是数据在时间维度上的聚合操作。
4.时间语义简介。流式数据计算引擎以时间维度对数据进行处理,通常支持处理时间和事件时间两类时间语义。处理时间是消息进入计算引擎的时间,数据按照进入系统的顺序绑定递增的时间戳,由于处理时间语义下使用机器物理时间,因此窗口按照机器时间触发即可,该模式下数据处理较为简单。事件时间是指数据真实发生的时间,但数据产生后可能由于网络不稳定等原因导致乱序到达服务器,也可能由于网络故障导致无法到达服务器。因此,事件时间处理模式下,系统无法使用机器时间判断窗口的数据是否全部到齐。当前主流的一种做法是使用水位线机制判断数据是否到齐,水位线是系统使用特定算法估算出的一个标志位,用于标记该时刻某窗口数据已全部到齐,通常使用启发式算法得出。但由于数据是未知的,系统无法预测准确的水位线位置,因此水位线之后仍可能有迟到数据到达,这部分数据被单独处理。由于数据可能延迟几小时甚至几天才能到达,而在金融等一些领域又无法接受数据丢弃,因此迟到数据处理场景下如何缓存大量窗口数据是流式数据计算系统的一大挑战。
5.存储和计算模式简介。流式计算引擎的存储和计算模式分为基于行存和基于列存两类,行存模式是指系统以数据表的行为单位存储数据及进行计算,如图1所示。基于行存的存储模式是一种非常直观的存储模式,其存储模式与人类所习惯的表格存储模式类似。其优点是可以高效的操作同一记录的各个数据属性,并且对事务操作友好。但由于行存存储模式在读取数据时需要按行读取每个记录的全部数据,如果一个查询只需要使用数据记录中的部分属性,则此模式会造成无关的读写开销,当数据记录属性特别多时此开销可能严重影响系统性能。此外,在需要对整个数据集按照某属性进行数据聚合的场景,由于行存
模式需要读取数据记录全部的数据,对内存不友好,造成性能较差。主流的流式数据计算引擎如apache flink、apache spark streaming等,使用行存存储模式,该模式在数据清洗、过滤、转换等场景下给系统带来较低的延迟。
6.列存模式是指系统按照数据表的列来维护数据记录并进行计算,数据表每一列代表数据记录的一个属性,并将所有数据记录按属性排序存储在内存中,如图2所示。其存储模式没有行存模式直观。基于列存的存储模式是为解决数据分析场景而诞生的。由于其每条数据记录各属性存储不连续,因此对单个数据记录的操作速度要慢于行存存储模式,且对事务操作不友好。但由于列存模式可以只检索指定的数据属性而无需读取全部数据,因此在需要数据过滤的场景可极大减少数据读写开销,同时在数据聚合场景对内存友好,故列存存储模式在数据分析场景下有其独到优势。基于列存的存储模式广泛应用于数据分析引擎中,如hbase,clickhouse等。
7.(1)内存缓存无法存储超大窗口数据
8.流式数据计算场景中,数据可能由于如网络故障或设备离线等不可预测的原因造成延迟到达,造成数据分析任务在数据生成和处理之间存在很大的延迟,该延迟可能是几个小时或是几天。例如,用户在飞机起飞前生成一条日志,该日志可能在几小时或一天后才会到达服务器。当前主流的流式数据计算引擎使用窗口技术缓存数据,用户往往需要设置一个比较大的窗口汇总所有迟到数据,但较大的窗口间隔同时也增加系统处理延迟。诸如google millwheel、apache flink、或spark streaming等现代流式数据计算引擎使用水位线机制定义时间窗口的下界,到达水位线意味着当前时间窗口的所有数据均已到达系统。不幸的是,对于一个真实的应用场景,由于数据流是未知的,系统不可能有足够的知识以建立百分之百准确的水位线,水位线之后到达的数据仍然面临丢失风险。此外,较大的窗口间隔也带来更大的内存压力。主流的流式数据计算引擎采用内存缓存窗口数据,有限的内存无法缓存无限的数据流。
技术实现要素:
9.本发明的目的是提高流式数据计算系统的计算效率以及窗口数据缓存能力,提出了一种基于列存存储的流式数据专用存储引擎设计方法。
10.具体来说,本发明提出了一种基于列存数据的流式数据处理方法,其中包括:
11.步骤1、获取待处理的流式数据及其对应的处理任务,基于时间维度将该流式数据切分为批式数据块,该批式数据块中每条数据均包含各自所属窗口的时间戳;
12.步骤2、根据该时间戳的时间类型,压缩该时间戳,根据压缩结果为该批式数据块中每条数据分配窗口序号,将该批式数据块切分为多个中间数据块,每个中间数据块仅包含窗口序号相同的数据,根据处理任务对每个中间数据块的数据进行预聚合计算,产生预聚合中间状态;
13.步骤3、根据预设的流式数据时间处理模式,从内部存储提取相应窗口序号的预聚合中间状态并执行与其对应的处理任务,输出各窗口序号的任务处理结果,作为流式数据处理结果。
14.所述的基于列存数据的流式数据处理方法,其中该步骤2包括:
15.判断该时间戳的时间类型是否为秒,若是,则以t/w作为该压缩结果;
16.否则判断该时间戳的时间类型是否为分,若是,则以t/60/w作为该压缩结果;
17.否则判断该时间戳的时间类型是否为小时,若是,则以t/3600/w作为该压缩结果;
18.否则判断该时间戳的时间类型是否为天,若是,则以(t 28800)/86400/w作为该压缩结果;
19.否则判断该时间戳的时间类型是否为周,若是,则以(d
–
4)/7/w作为该压缩结果;
20.否则判断该时间戳的时间类型是否为月,若是,则以to_month(d)/w作为该压缩结果;
21.否则判断该时间戳的时间类型是否为季度,若是,则以to_month(d)/3/w作为该压缩结果;
22.否则该时间戳的时间类型是否为年,以to_yead(d)/w作为该压缩结果;
23.其中t为窗口时间戳,w为窗口大小,d为窗口时间戳所在日期距1970-01-01的天数。
24.所述的基于列存数据的流式数据处理方法,其中该步骤2包括:当该中间数据块的窗口序号大于水位线时,该中间数据块属于未触发的活跃数据,以内存存储该中间数据块,过程包括:
25.步骤21、遍历内存链表,判断窗口序号是否具有对应的链表节点,若是,则执行步骤22,否则在链表尾部依次增加链表节点,每个节点序号比上一个节点序号大一,直到链表序号等于该窗口序号,执行步骤22;
26.步骤22、使用树结构存储具有相同窗口序号的预聚合中间状态,以窗口序号对应的链表节点作为根节点,将预聚合中间状态追加到树的叶子节点;
27.步骤23、定期对该树结构进行合并,每次合并时查找深度最大的叶子节点,并将其与所有兄弟节点及父节点合并;
28.步骤24、重复进行步骤23,直到树结构除根节点外只剩一个节点,根节点表示树的窗口序号,其他节点为预聚合中间状态。
29.所述的基于列存数据的流式数据处理方法,其中该步骤2包括:当该中间数据块的窗口序号小于水位线,但大于该水位线减最大迟到允许间隔时,该中间数据块属于已触发的迟到数据,以磁盘存储该中间数据块,过程包括:
30.步骤25、从磁盘中查找迟到数据对应窗口序号的预聚合中间状态并加载到内存,在磁盘中将对应中间状态数据标记为待删除状态;
31.步骤26、将步骤25获取的预聚合中间状态与迟到数据合并,生成新的预聚合中间状态;
32.步骤27、删除磁盘中标记为待删除状态的预聚合中间状态删除,将步骤26生成的新的预聚合中间状态追加到磁盘。
33.所述的基于列存数据的流式数据处理方法,其中该流式数据为传感器实时采集的生理数据、图像数据或日志文本数据;流式数据对应的处理任务为数据库统计任务。
34.本发明还提出了一种基于列存数据的流式数据处理系统,其中包括:
35.切分模块,用于获取待处理的流式数据及其对应的处理任务,基于时间维度将该流式数据切分为批式数据块,该批式数据块中每条数据均包含各自所属窗口的时间戳;
36.压缩模块,用于根据该时间戳的时间类型,压缩该时间戳,根据压缩结果为该批式
数据块中每条数据分配窗口序号,将该批式数据块切分为多个中间数据块,每个中间数据块仅包含窗口序号相同的数据,根据处理任务对每个中间数据块的数据进行预聚合计算,产生预聚合中间状态;
37.输出模块,用于根据预设的流式数据时间处理模式,从内部存储提取相应窗口序号的预聚合中间状态并执行与其对应的处理任务,输出各窗口序号的任务处理结果,作为流式数据处理结果。
38.所述的基于列存数据的流式数据处理系统,其中该压缩模块用于,
39.判断该时间戳的时间类型是否为秒,若是,则以t/w作为该压缩结果;
40.否则判断该时间戳的时间类型是否为分,若是,则以t/60/w作为该压缩结果;
41.否则判断该时间戳的时间类型是否为小时,若是,则以t/3600/w作为该压缩结果;
42.否则判断该时间戳的时间类型是否为天,若是,则以(t 28800)/86400/w作为该压缩结果;
43.否则判断该时间戳的时间类型是否为周,若是,则以(d
–
4)/7/w作为该压缩结果;
44.否则判断该时间戳的时间类型是否为月,若是,则以to_month(d)/w作为该压缩结果;
45.否则判断该时间戳的时间类型是否为季度,若是,则以to_month(d)/3/w作为该压缩结果;
46.否则该时间戳的时间类型是否为年,以to_yead(d)/w作为该压缩结果;
47.其中t为窗口时间戳,w为窗口大小,d为窗口时间戳所在日期距1970-01-01的天数。
48.所述的基于列存数据的流式数据处理系统,其中该压缩模块用于当该中间数据块的窗口序号大于水位线时,该中间数据块属于未触发的活跃数据,以内存存储该中间数据块;
49.该压缩模块包括:
50.模块21,用于遍历内存链表,判断窗口序号是否具有对应的链表节点,若是,则执行模块22,否则在链表尾部依次增加链表节点,每个节点序号比上一个节点序号大一,直到链表序号等于该窗口序号,调用模块22;
51.模块22,用于使用树结构存储具有相同窗口序号的预聚合中间状态,以窗口序号对应的链表节点作为根节点,将预聚合中间状态追加到树的叶子节点;
52.模块23,用于定期对该树结构进行合并,每次合并时查找深度最大的叶子节点,并将其与所有兄弟节点及父节点合并;
53.模块24,用于重复调用模块23,直到树结构除根节点外只剩一个节点,根节点表示树的窗口序号,其他节点为预聚合中间状态。
54.所述的基于列存数据的流式数据处理系统,其中该压缩模块用于当该中间数据块的窗口序号小于水位线,但大于该水位线减最大迟到允许间隔时,该中间数据块属于已触发的迟到数据,以磁盘存储该中间数据块;
55.该压缩模块包括:
56.模块25,用于从磁盘中查找迟到数据对应窗口序号的预聚合中间状态并加载到内存,在磁盘中将对应中间状态数据标记为待删除状态;
57.模块26,用于将模块25获取的预聚合中间状态与迟到数据合并,生成新的预聚合中间状态;
58.模块27,用于删除磁盘中标记为待删除状态的预聚合中间状态删除,将模块26生成的新的预聚合中间状态追加到磁盘。
59.所述的基于列存数据的流式数据处理系统,其中该流式数据为传感器实时采集的生理数据、图像数据或日志文本数据;流式数据对应的处理任务为数据库统计任务。
60.由以上方案可知,本发明的优点在于:
61.该发明提出了一种列存流式数据存储引擎设计方法。与现有技术相比,该引擎通过内存 磁盘二级存储结构解决了传统内存存储容量有限及磁盘存储延迟高的矛盾,支持缓存超大窗口。该引擎通过在内存中存储预聚合中间状态,并使用后台任务定期进行合并,降低了窗口计算输出延迟。此外,通过使用窗口id压缩技术提升了窗口操作数据聚合性能。
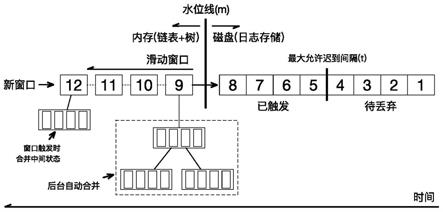
附图说明
62.图1为行存存储模式示意图;
63.图2为列存存储模式示意图;
64.图3为二级存储结构示意;
65.图4为存储引擎数据结构示意;
66.图5为windowview磁盘存储引擎状态更新。
具体实施方式
67.发明人在进行流式计算引擎研究时,发现很多事件时间处理场景下,用户消息迟到现象严重,如金融、广告等很多数据价值较高的场景下,窗口大小往往设置为数天以应对迟到消息,主流流式数据计算系统以内存存储为主,缓存较大的时间窗口数据对内存造成很大压力。此外,主流的流式数据计算系统均为行存计算及存储模式,行存模式以单个数据为单位进行处理,延迟较低,但窗口操作为数据聚合操作,行存模式数据聚合操作性能不如列存模式。窗口计算模式下,窗口数据必须全部到齐才可进行计算输出,因此行存模式并不能完全发挥低延迟优势。发明人经过对现有技术的研究,发现传统存储引擎操作模式不固定,需要应对随机增删改查,但流式数据操作模式是固定的,如窗口大小、滑动间隔等在流式查询创建时即固定。因此,发明人针对流式数据计算特性,提出了列存流式数据专用存储引擎,该引擎使用内存 磁盘二级存储结构,在保证低延迟处理的基础上解决了传统内存存储引擎难以缓存超大窗口数据的问题,通过使用列存存储结构,提高了窗口聚合计算性能,此外,还通过窗口id压缩、窗口计算状态预聚合等技术进一步降低列存引擎的处理延迟。
68.为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
69.由于流式数据处理中,无论是事件时间还是处理时间模式,滚动窗口和滑动窗口都是按顺序触发的,因此,存储引擎采用磁盘 内存二级存储结构,如图3所示,内存负责存储尚未触发的窗口数据,此部分数据更新频繁,要求更高的io性能。待窗口触发后,窗口数据更新频率变的很低,因此,系统将触发后的窗口数据保存在磁盘,已应对迟到数据处理,待磁盘缓存数据超过最大允许迟到时间后,超过最大允许迟到时间的缓存数据会被标记为
待丢弃数据,并被系统定期清理。存储引擎数据结构如图4所示。
70.过程一:数据进入存储引擎后,首先存储引擎过滤掉时间戳小于水位线(m)-最大允许迟到间隔(t)的数据,例如图4中的1234,这部分数据所在的窗口已经超时,因此处理这部分数据没有意义。
71.过程二:进入存储引擎的每条数据均包含一个用于标记窗口的时间戳(例如unix时间戳,是一个表示具体日期时间的数字),系统将该时间戳压缩,生成连续的窗口序号,如表1所示,其中,t为窗口时间戳,w为窗口大小,d为窗口时间戳所在日期距1970-01-01的天数。
72.例如使用窗口开始时间作为时间戳,窗口大小为2s,三个窗口unix时间戳分别为:1636012243、1636012245、1636012247,通过本发明的压缩,可以将其转换为连续的窗口序号1、2、3。
73.此步骤可带来两大性能提升。首先,窗口序号相比窗口时间戳的32位无符号整数占用更少的比特位,意味着对cache更加友好,可带来更高效的聚合性能。当窗口序号比特位小于16时,存储引擎使用查找表代替哈希表进行索引,可进一步提升聚合性能;其次,连续的窗口序号对存储引擎更加友好,可减少窗口触发时存储引擎查找数据的次数。
74.表1窗口序号生成方法
75.时间类型压缩后大小(bit)窗口时间戳(s)second32t/wminute27t/60/whour21t/3600/wday16(t 28800)/86400/wweek14(d
–
4)/7/wmonth12to_month(d)/wquarter10to_month(d)/3/wyear08to_yead(d)/w
76.过程三:系统以过程二分配的窗口序号为单位将数据进行分类,并对每个分类下的数据进行预聚合计算,产生预聚合中间状态。多个预聚合中间状态可通过合并操作合并为一个预聚合中间状态,也可通过计算输出操作计算为最终计算结果。通过预聚合操作可减少窗口触发时的计算量。此步骤每个预聚合中间状态对应一个窗口序号。
77.过程四:过程三生成的数据中,对于窗口序号大于水位线(m)的数据该部分数据属于尚未触发的活跃窗口,处理过程如下。其中,水位线是系统观测到的最大时间,例如到达数据序列1,2,5,3,4,6,则其对应的当前水位线即为1,2,5,5,5,6。
78.过程4.1:系统在内存中使用链表结构对数据进行索引,链表由连续递增节点组成,节点的值代表窗口序号。系统遍历该链表,查找窗口序号对应的节点,如节点最大序号小于窗口序号,则在链表尾部依次增加链表节点,每个节点序号比上一个节点序号大一,直到链表序号等于窗口序号为止。
79.过程4.2:系统使用树结构存储具有相同窗口序号的预聚合中间状态,以过程4.1查找到的链表节点为树的根节点,将预聚合中间状态追加到树的叶子节点。
80.过程4.3:系统定期对过程4.2所产生的树结构进行合并,每次合并时查找深度最
大的叶子节点,并将其与所有兄弟节点及父节点合并。
81.过程4.4:重复进行过程4.3,直到树结构除根节点外只剩一个节点。
82.过程五:过程三生成的数据中,对于窗口序号小于等于水位线(m),但大于w-t的数据,该部分数据属于迟到数据,处理过程如下:
83.过程5.1:从磁盘(日志存储)中查找对应窗口序号的预聚合中间状态并加载到内存,并在磁盘中将对应中间状态数据标记为“待删除”状态。
84.过程5.2:将过程5.1获取的预聚合中间状态与新插入的数据合并,生成新的预聚合中间状态,如图5所示。
85.过程5.3:将过程5.2生成的预聚合中间状态追加到磁盘(日志存储)队尾。
86.过程5.4:将过程5.2生成的预聚合中间状态计算为最终计算状态并进行输出。
87.过程六:过程三生成的数据中,对于窗口序号小于等于w-t的数据,该部分数据已超过最大允许迟到间隔,故直接丢弃。
88.过程七:系统提供“窗口触发(窗口序号)”操作,操作的参数为“窗口序号”wid,操作调用时,系统自动对尚未触发且窗口序号小于wid的所有窗口进行触发计算。窗口触发操作由计算引擎在需要触发时调用,其过程描述如下:
89.过程7.1:由于处理时间及事件事件下的滚动窗口和滑动窗口触发均以窗口序号增量计算。因此,系统在内存链表上使用滑动窗口对数据进行提取,每次提取一个窗口序号的预聚合中间状态树,假设当前滑动窗口所对应的窗口序号为wid_now。
90.过程7.2:使用过程4.3、4.4描述的方法将过程7.1提取的预聚合中间状态树合并为一个节点。
91.过程7.3:将过程7.3生成的预聚合中间状态计算为最终计算状态并进行输出。
92.过程7.4:将过程7.3生成的预聚合中间状态写入磁盘(日志存储)队尾。
93.过程7.5:使用临时变量n指向滑动窗口所在位置。
94.过程7.6:将滑动窗口向窗口序号增大方向滑动一个单位。
95.过程7.7:删除过程7.5所描述的临时变量n所指向的链表节点,以及链表节点所指向的树结构的内存。
96.过程7.8:将磁盘(日志存储)中窗口序号小于wid_now-t的数据块标记为“待删除”。
97.过程7.8:重复过程7.1-过程7.7,直到滑动窗口所指向的窗口序号大于wid。
98.过程八:系统定期对磁盘(日志存储)进行扫描,删除被标记为“待删除”状态的数据块。
99.以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
100.本发明还提出了一种基于列存数据的流式数据处理系统,其中包括:
101.切分模块,用于获取待处理的流式数据及其对应的处理任务,基于时间维度将该流式数据切分为批式数据块,该批式数据块中每条数据均包含各自所属窗口的时间戳;
102.压缩模块,用于根据该时间戳的时间类型,压缩该时间戳,根据压缩结果为该批式数据块中每条数据分配窗口序号,将该批式数据块切分为多个中间数据块,每个中间数据
块仅包含窗口序号相同的数据,根据处理任务对每个中间数据块的数据进行预聚合计算,产生预聚合中间状态;
103.输出模块,用于根据预设的流式数据时间处理模式,从内部存储提取相应窗口序号的预聚合中间状态并执行与其对应的处理任务,输出各窗口序号的任务处理结果,作为流式数据处理结果。
104.所述的基于列存数据的流式数据处理系统,其中该压缩模块用于,
105.判断该时间戳的时间类型是否为秒,若是,则以t/w作为该压缩结果;
106.否则判断该时间戳的时间类型是否为分,若是,则以t/60/w作为该压缩结果;
107.否则判断该时间戳的时间类型是否为小时,若是,则以t/3600/w作为该压缩结果;
108.否则判断该时间戳的时间类型是否为天,若是,则以(t 28800)/86400/w作为该压缩结果;
109.否则判断该时间戳的时间类型是否为周,若是,则以(d
–
4)/7/w作为该压缩结果;
110.否则判断该时间戳的时间类型是否为月,若是,则以to_month(d)/w作为该压缩结果;
111.否则判断该时间戳的时间类型是否为季度,若是,则以to_month(d)/3/w作为该压缩结果;
112.否则该时间戳的时间类型是否为年,以to_yead(d)/w作为该压缩结果;
113.其中t为窗口时间戳,w为窗口大小,d为窗口时间戳所在日期距1970-01-01的天数。
114.所述的基于列存数据的流式数据处理系统,其中该压缩模块用于当该中间数据块的窗口序号大于水位线时,该中间数据块属于未触发的活跃数据,以内存存储该中间数据块;
115.该压缩模块包括:
116.模块21,用于遍历内存链表,判断窗口序号是否具有对应的链表节点,若是,则执行模块22,否则在链表尾部依次增加链表节点,每个节点序号比上一个节点序号大一,直到链表序号等于该窗口序号,调用模块22;
117.模块22,用于使用树结构存储具有相同窗口序号的预聚合中间状态,以窗口序号对应的链表节点作为根节点,将预聚合中间状态追加到树的叶子节点;
118.模块23,用于定期对该树结构进行合并,每次合并时查找深度最大的叶子节点,并将其与所有兄弟节点及父节点合并;
119.模块24,用于重复调用模块23,直到树结构除根节点外只剩一个节点,根节点表示树的窗口序号,其他节点为预聚合中间状态。
120.所述的基于列存数据的流式数据处理系统,其中该压缩模块用于当该中间数据块的窗口序号小于水位线,但大于该水位线减最大迟到允许间隔时,该中间数据块属于已触发的迟到数据,以磁盘存储该中间数据块;
121.该压缩模块包括:
122.模块25,用于从磁盘中查找迟到数据对应窗口序号的预聚合中间状态并加载到内存,在磁盘中将对应中间状态数据标记为待删除状态;
123.模块26,用于将模块25获取的预聚合中间状态与迟到数据合并,生成新的预聚合
中间状态;
124.模块27,用于删除磁盘中标记为待删除状态的预聚合中间状态删除,将模块26生成的新的预聚合中间状态追加到磁盘。
125.所述的基于列存数据的流式数据处理系统,其中该流式数据为传感器实时采集的生理数据、图像数据或日志文本数据;流式数据对应的处理任务为数据库统计任务。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
