一种基于gan的hevc压缩视频视觉感知提升方法
技术领域
1.本发明涉及视频编码领域中的视频质量提升方法的研究,尤其是涉及一种基于gan的hevc压缩视频视觉感知提升方法的方法。
背景技术:
2.hevc作为主流视频编码标准,虽然能取得很好的压缩效率,但在压缩和传输过程中不可避免会造成视频质量损失,这种损失既指客观质量上的失真,也包含主观视觉效果的模糊。图像恢复算法通常通过一些失真来度量,例如:psnr、ssim、ifc、vif,这些失真度量因为要使用原图进行评估称为全参考指标。但在实际传输任务中,原图像并不一定可获得,只能通过需要处理的降质图像进行重建效果评估,这种评估失真的方式称为无参考指标,例如量化视觉感知质量的人类意见评分。实际客观失真度量和视觉感知质量并不是一一对应的,具体来说,随着平均失真的减少,能正确区分是图像恢复算法的输出或者真实图像输出的最佳概率反而会增加(表明是为更差的视觉感知质量),这个结果对于任何失真度量都是满足的,不仅仅是常用压缩性能评价标准指标psnr和ssim,gan网络还提供了一种接近感知质量和失真度量平衡的原则。
3.gan网络的对抗性损失能很好地学习图像分布间的映射,提高视觉效果,基于gan网络进行的图像超分辨率重建工作取得了较好的视觉效果。同时在压缩伪影去除的工作中,gan被证明具有减少伪影的强大能力。现今有学者提出了使用生成对抗框架训练的前馈全卷积残差网络模型,并可以通过优化结构相似度来进行训练,所提gan能够生成具有更多真实感细节的图像。还有通过gan进行帧内编码的后处理学习,提出了一种多层递进细化网络mprnet,该网络可以在一次前馈中预测多级残差,这种从粗到精的细化方式使mprnet可以在细化的质量和计算复杂度之间进行权衡,这有利于在资源感知型背景下应用。同时有学者提出了一种具有递归框架的对抗学习方法,称为视频伪影去除生成对抗网络vrgan,vrgan包含一个生成器,该生成器具有可提高视频一致性的循环框架,一个可增强大型转换单元接收场的密集块,以及一个相对论鉴别器,可评估生成的帧与原始高质量帧之间的关系,所提网络能够生成更逼真的视频。还有学者提出采用ga进行图像超分辨率工作的srgan,srgan中采用一种感知损失函数,它包含对抗损失和内容损失,使用对抗损失将失真图像逼近自然图像。在srgan的基础上,通过分析超分图像的细节常常伴随着令人不愉快的伪影,为提高视觉质量,提出esrgan,引入残差密集块,将其不进行批量归一化,这样的结构作为基本的网络构建单元,并使用激活前的特征来改善感观损失,从而可以对亮度一致性和纹理恢复提供更强的监督。
4.在控制重建图像与真实图像间差异的前提下,gan生成的图像更加符合自然图像的分布,能重建出更好的视觉效果。随着4g时代的普及以及5g时代的到来,人们对图像视频的质量和分辨率要求越来越高,也更加追求解码视频感知效果的舒适性,因此需对压缩视频提升主观视觉感知质量。
5.经过hevc压缩解码后的视频帧能通过gan的生成网络学习从已编码帧到原始帧的
映射,并通过gan的判别网络来不断逼近这种映射,实现视频帧主观视觉感知的提升,最终有效去压缩。因此,本发明将提出一种基于gan的hevc压缩视频视觉感知提升方法网络结构,结合gan的感知及失真平衡特性有效提高hevc压缩视频的感知质量。
技术实现要素:
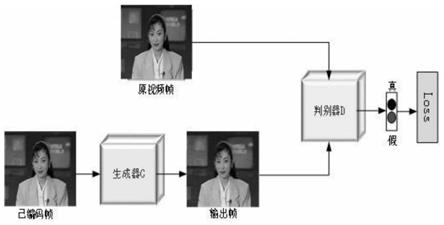
6.随着大数据分析及人工智能的迅速发展,人们对视频的要求不仅是客观质量的保真,也需要满足人眼观察。因此本发明将提出一种对压缩视频主观视觉感知质量进行提升的方法-基于gan的hevc压缩视频视觉感知提升方法研究。所提深度网络中经过hevc压缩后的视频帧通过gan生成器输出重建图像,该输出图像可以有效指导gan的判别器逼近已编码帧与原始帧之间的映射,再通过生成器的对抗性损失来不断学习这种映射,提高压缩视频序列的视觉感知质量,最终有效去除压缩效应。
7.本发明提出一种基于gan的hevc压缩视频视觉感知提升方法研究。首先设计了基于convolution-batchnorm-relu结构的9层残差网络作为生成器g,一方面用于增强特征映射,提取更能表达重建视频帧信息的特征,另一方面引入残差学习可加快网络收敛。并在残差网络前进行下采,旨在实现空间分辨率的下采,减少网络参数,避免网络参数过多造成过拟合现象。最后为保证输入视频帧和重建帧尺寸一致,采用逆卷积层恢复到原始尺寸。其次判别器d设计为patchgan结构,该结构判别器以图像中每个n
×
n块为单位进行真假分类,整幅图像的输出为图像中所有块判别的平均结果。这种结构假设像素之间的独立性大于一个块的尺寸,其优点是避免以整幅图像判别作为输出时的极端结果。gan的对抗性损失可以最小化生成器g生成图像与训练数据集中图像分布之间的距离,通过利用对抗性损失来实现视频帧的感知质量恢复。经过hevc压缩后的视频帧能通过gan的生成网络学习从已编码帧到原始帧的映射,并通过gan的判别网络来不断逼近这种映射,得到高视觉感知质量的重建帧,最终有效去除干扰视觉观察的伪影。具体包括以下过程步骤:
8.(1)生成图像残差网络;
9.(2)将残差块个数n分别设置为5、7、9、11、13,其中9个残差块为生成器所选残差结构;
10.(3)判别器不变并且生成器中其余层结构不变,分别将生成器中残差块设置为以上5个深度并训练,用5个残差深度下gan的最佳模型重建压缩视频序列foreman_352
×
288并计算感知指数pi值(在本发明基于gan的hevc压缩视频视觉感知提升方法研究中,所提gan框架生成器中的残差块设置为9层时,网络能获得更加丰富的纹理信息,能较好地去除视觉感知上的压缩伪影);
11.(4)本改进gan框架中生成器g采用9层残差网络,能提取更能表达重建视频帧信息的特征并加快网络收敛;在残差网络前进行下采,convolution-batchnorm-relu结构的下采层可以表示为公式(1),
↓2表示该层卷积步长为2,旨在实现空间分辨率的下采,减少网络参数,并结合在残差网络中使用dropout层按照概率丢掉部分神经元,避免网络参数过多造成过拟合;最后为保证输入视频帧和重建帧尺寸一致,采用逆卷积层恢复到原始尺寸。同理,convolution-batchnorm-relu结构的逆卷积层可以表示为(2)式,其中
↑2表示该层逆卷积步长为2。
12.[0013][0014]
本发明所提生成器g的配置如表1所列,结构层公式表示为:
[0015]
f0(y)=y
ꢀꢀ
(3)
[0016][0017][0018][0019][0020]f15
=w
15
·f14
(y) b
15
ꢀꢀ
(8)
[0021]f16
=tanh(f
15
(y))
ꢀꢀ
(9)
[0022]
其中,y为已编码视频帧,wi和bi分别为第i层的权重和偏置。
[0023]
本发明所提判别器d的配置如表2所列,结构层公式表示为:
[0024]
f0(y)=y
ꢀꢀ
(10)
[0025]
f1(y)=leakyrelu(w1·
f0(y) b1)
ꢀꢀ
(11)
[0026]fi
(y)=f
normleaky
(y),i={2,3,4}
ꢀꢀ
(12)
[0027]
f5=w5·
f4(y) b5ꢀꢀ
(13)
[0028]
其中,y为已编码视频帧,wi和bi分别为第i层的权重和偏置;
[0029]
(5)本发明训练算法生成对抗网络gan的目标函数可以表示为:
[0030]
l
gan
(g,d)=e
x,y
[log d(x,y)] e
x,z
[log(1-d(x,g(x,z)))]
ꢀꢀ
(14)
[0031]
本发明网络采用l1作为辅助损失函数:
[0032]
l
l1
(g)=e
x,y,z
[||y-g(x,z)||1]
ꢀꢀ
(15)
[0033]
因此,结合gan目标函数与l1损失的最终目标函数为:
[0034][0035]
(6)训练网络时,训练集样本选用bsds500database,将bsds500里的训练图库和测试图库共同用于本发明的训练图库。为了准备训练数据,将400张原始训练图在hevc基于ai的标准帧内编码配置文件encoder_intra_main.cfg和基于ldp的ippp标准帧间编码配置文件encoder_lowdelay_p_main.cfg下,设置qp=22、27、32、37时分别进行编码,以此得到帧内和帧间各四个qp,共八个降质的图像库。为扩大样本数和更加准确地恢复图像结构特征,将原始图库和八个降质图库进行四个方向地旋转和五个尺度地缩放,再把扩展的原始图库和降质图库进行分割生成训练样本,考虑到hevc编码变换单元ctu的大小为64、32和16,但是学习64
×
64大小的标签没有成功,因此本发明中以步长32将图库切割成32
×
32的块,每次训练时,随机选取切割样本数据中的16个样本进行参数优化,即训练时batchsize=16。
[0036]
本发明与现有技术相比所具有的优点及有益技术效果:
[0037]
(1)本发明提出一种基于gan的hevc压缩视频视觉感知提升后处理算法,生成器g生成图像分布与训练数据集中图像分布间有一个距离,gan的对抗性损失可以最小化这个距离,通过利用对抗性损失可以实现视频帧视觉质量恢复。
[0038]
(2)经过hevc压缩后的视频帧能有效指导gan的生成网络学习从已编码帧到原始
帧的映射,并通过gan的判别网络不断逼近这种映射,得到高视觉感知质量重建帧,最终有效去除视觉感知上的压缩伪影。
[0039]
(3)实验结果表明,该算法可以获得更好的重建视觉效果,选择基于ai的标准编码模式,在qp=22、27、32、37时所提gan网络pi分别平均比标准hevc低1.27、1.59、1.43、2.23;选择基于ldp的ippp标准编码模式,在qp=22、27、32、37时所提gan网络pi分别平均比标准hevc低1.18、1.42、1.33、2.09。并且与hevc标准和相关gan网络相比,本发明后处理技术能获得更好的视觉感知效果时,还能将客观失真控制在更小的范围内。
附图说明
[0040]
图1为基于gan的hevc压缩视频视觉感知提升方法网络流程图。
[0041]
图2为基于gan的hevc压缩视频视觉感知提升方法网络生成器、判别器结构。
[0042]
图3为采用本发明所提gan在不同残差深度下重建foreman_352
×
288序列的性能。
[0043]
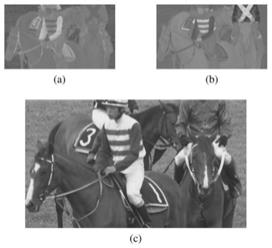
图4为本发明算法和hm16.0标准方法视觉感知质量对比。
具体实施方式
[0044]
下面结合实施例对本发明作进一步的详细说明,有必要指出的是,以下的实施例只用于对本发明做进一步的说明,不能理解为对本发明保护范围的限制,所属领域技术熟悉人员根据上述发明内容,对本发明做出一些非本质的改进和调整进行具体实施,应仍属于本发明的保护范围。
[0045]
(1)本发明提出一种基于gan的hevc压缩视频视觉感知提升后处理算法,为验证所提算法的有效性,将所提算法用于hevc标准hm16.0测试模型压缩后的视频。本发明实验选择基于ai的标准帧内编码配置文件encoder_intra_main.cfg和基于ldp的ippp标准帧间编码配置文件encoder_lowdelay_p_main.cfg。标准测试视频序列从352
×
288、416
×
240、832
×
480、1280
×
720、1920
×
1080五个分辨率大小视频中各选择两个,量化qp分别为22、27、32、37。本发明所有的实验均使用matlabr2014a和visualstudio2013工具在cpu为i5-2320@3.00ghz和gpunvidiageforcegtx2080环境上运行。
[0046]
(2)采用所提训练算法,训练出帧内和帧间各四个qp,共八个最佳模型,将各最佳模型用于重建对应qp下hevc标准压缩后的视频,改善hevc编码带来的视觉感知失真。测试时,由于是对视频序列进行重建,不同于训练时的按块处理,将以帧为单位进行感知质量提升,即batchsize=1。实验结果通过主观视觉感知评价指标pi验证,选择基于ai的标准编码模式,采用所提方法帧内四个qp下的最佳模型对应重建压缩视频,实验结果与hevc标准实验结果如表3所示;选择基于ldp的ippp标准帧间编码模式,采用所提方法帧间四个qp下的最佳模型对应重建压缩视频,实验结果与hevc标准实验结果如表4所示。pi感知指标表示重建视频帧分布与训练数据集中图像分布之间的距离,因此,数值越小越好。并且为了直观表示所提算法在pi指标上的性能效果,实验结果中采用δpi代表本发明后处理算法与hevc标准在pi上的差值:
[0047]
δpi=pi
proposed-pi
hevc
[0048]
由于感知指标pi的数值是越小越好,因此当δpi为负时,代表本发明算法pi数值小于hevc压缩视频所得pi数值,也就是本发明算法能改善压缩视频的视觉感知质量。
[0049]
表1中卷积层用conv表示,逆卷积层用convtrans表示,卷积层、残差层和逆卷积层的滤波器大小、滤波器数量和步长对应如表中所示。每一个残差层的配置均相同,因此表1中仅给出第一个残差层和最后一个残差层配置参数,用
“…”
省略了第二个至第八个残差层的配置参数。
[0050]
表1 本发明算法生成器g的配置
[0051][0052]
表2中卷积层用conv表示,卷积层的滤波器大小、滤波器数量和步长对应如表中所示。
[0053]
表2 本发明算法判别器d的配置
[0054]
层滤波器大小滤波器数量步长conv14
×
4642conv24
×
41282conv34
×
42562conv44
×
45121conv54
×
411
[0055]
表3 采用hm16.0标准和本发明算法在帧内编码时的实验结果
[0056][0057]
表续3 采用hm16.0标准和本发明算法在帧内编码时的实验结果
[0058][0059]
表4 采用hm16.0标准和本发明算法在帧间编码时的实验结果
[0060][0061]
表续4 采用hm16.0标准和本发明算法在帧间编码时的实验结果
[0062]
为进一步探索所提gan网络的视觉感知提升效果,将本发明所提算法与相关gan网络srgan和esrgan进行对比。将srgan和esrgan的上采因子设置为1,并采用与本发明所提gan网络相同的数据库进行训练,训练得到的最佳模型用于压缩视频重建。由于srgan和esrgan网络参数较多、重建图像空间分辨率有限,在本发明运行环境gpunvidiageforcegtx2080上仅能重建到832
×
480尺寸的视频帧,因此表5和表6给出了标准测试视频序列foreman_352
×
288、stefan_352
×
288、keiba_416
×
240、bqsquare_416
×
240和racehorses_832
×
480在hevc标准、srgan、esrgan和本发明所提算法重建下的感知-失真结果。表中感知-失真指标采用esrgan中所提pi-rmse指标,并结合感知失真平面进行对比,其中,均方根误差(rootmeansquarderror,rmse)代表客观质量失真,是失真视频与原始视频在像素域的差异表示。表5和表6分别为视频序列在帧内和帧间编码时的实验结果。
[0063]
表5 hevc标准、srgan及esrgan和本发明算法在帧内编码时性能对比
[0064][0065]
表续5 hevc标准、srgan及esrgan和本发明算法在帧内编码时性能对比
[0066][0067]
表6 hevc标准、srgan及esrgan和本发明算法在帧间编码时性能对比
[0068]
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。