用于处理文本数据的机器学习系统的自适应训练的系统和方法
1.相关申请的交叉引用
2.本技术要求于2019年4月3日提交的题为“systems and methods for adaptive training of a machine learning system processing textual data(用于处理文本数据的机器学习系统的自适应训练的系统和方法)”的美国临时专利申请第62/828,872号的优先权,其通过引用整体并入本文。
背景技术:
3.本发明的某些实施例涉及处理文本数据的机器学习系统。更具体地,本发明的一些实施例提供了用于处理文本数据的机器学习系统的自适应训练的系统和方法。
4.随着对文本和自然语言数据处理需求的不断增加,机器学习系统通常用于对文本和自然语言数据以及被包括在大量文档和文件中的其他信息分析和分类。机器学习(ml)系统包括预测模块,通常基于当前已知的真实答案对预测模块进行训练直到某个时间点。然而,外部因素可能影响由基于训练模型的常规ml系统所预测的答案的准确度。因此,例如,预测答案的实际准确度随着时间的推移而降低,尽管由常规ml系统所计算的每个预测答案的置信度仍然很高。因此,常规ml系统通常需要在连续的基础上识别预测结果的不准确性,收集用于训练模型的附加数据,以及重新训练模型。常规ml系统的连续训练是劳动密集型的、耗时的,并且随着训练数据量的增加而变得更加复杂。
5.因此,非常期望提供和/或改进用于处理文本数据的机器学习系统的自适应训练的技术。
技术实现要素:
6.本发明的某些实施例涉及处理文本数据的机器学习系统。更具体地,本发明的一些实施例提供了用于处理文本数据的机器学习系统的自适应训练的系统和方法。
7.根据一些实施例,一种用于被配置为预测对与文本数据相关联的问题的答案的机器学习系统的自适应训练的方法包括接收与文本数据相关联的问题的预测答案。预测答案至少部分基于机器学习系统的一个或多个第一模型生成。一个或多个第一模型与第一准确度分数相关联。该方法进一步包括至少地基于质量控制参数确定是否需要由一个或多个外部实体对问题进行评估。响应于至少部分地基于质量控制参数确定需要由一个或多个外部实体对问题进行评估,将文本数据和与文本数据相关联的问题发送到一个或多个外部实体进行评估。该方法进一步包括从一个或多个外部实体接收问题的真实答案以及至少部分地基于真实答案和预测答案确定一个或多个准确度参数。响应于一个或多个准确度参数小于预定最小阈值,识别准确度降低事件,并且增加质量控制参数。响应于至少一个问题的真实计数大于第一预定真实阈值,生成一个或多个第二模型,并且确定与该一个或多个第二模型相关联的第二准确度分数。响应于第二准确度分数大于与一个或多个第一模型相关联的第一准确度分数,在机器学习系统处利用一个或多个第二模型替换一个或多个第一模型。
8.根据某些实施例,一种用于被配置为预测与文本数据相关联的问题的答案的机器学习系统的自适应训练的系统,包括一个或多个处理器和包括指令的存储器。当由一个或多个处理器执行时,指令使得系统接收对与文本数据相关联的问题的预测答案。预测答案至少部分基于机器学习系统的一个或多个第一模型生成。一个或多个第一模型与第一准确度分数相关联。当由一个或多个处理器执行指令时,使得系统进一步执行至少部分地基于质量控制参数确定是否需要由一个或多个外部实体对问题进行评估。响应于至少部分地基于质量控制参数确定需要由一个或多个外部实体对问题进行评估,将文本数据和与文本数据相关联的问题发送到一个或多个外部实体进行评估。当由一个或多个处理器执行指令时,使得系统进一步执行从一个或多个外部实体接收问题的真实答案,以及至少部分地基于真实答案和预测答案确定一个或多个准确度参数。响应于一个或多个准确度参数小于预定最小阈值,识别准确度降低事件,并且增加质量控制参数。响应于至少一个问题的真实计数大于第一预定真实阈值,生成一个或多个第二模型,并且确定与该一个或多个第二模型相关联的第二准确度分数。响应于第二准确度分数大于与一个或多个第一模型相关联的第一准确度分数,在机器学习系统处利用一个或多个第二模型替换一个或多个第一模型。
9.根据一些实施例,一种存储一个或多个程序的非瞬态计算机可读存储介质。一个或多个程序包括指令,当由一个或多个处理器执行时,指令使得用于被配置为预测与文本数据相关联的问题的答案的机器学习系统的自适应训练的系统执行接收与文本数据相关联的问题的预测答案。预测答案至少部分基于机器学习系统的一个或多个第一模型生成。一个或多个第一模型与第一准确度分数相关联。当由一个或多个处理器执行指令时,使得系统进一步执行至少部分地基于质量控制参数确定是否需要由一个或多个外部实体对问题进行评估。响应于至少部分地基于质量控制参数确定需要由一个或多个外部实体对问题进行评估,将文本数据和与文本数据相关联的问题发送到一个或多个外部实体进行评估。当由一个或多个处理器执行指令时,使得系统进一步执行从一个或多个外部实体接收问题的真实答案,以及至少部分地基于真实答案和预测答案确定一个或多个准确度参数。响应于一个或多个准确度参数小于预定最小阈值,识别准确度降低事件,并且增加质量控制参数。响应于至少一个问题的真实计数大于第一预定真实阈值,生成一个或多个第二模型,并且确定与该一个或多个第二模型相关联的第二准确度分数。响应于第二准确度分数大于与一个或多个第一模型相关联的第一准确度分数,在机器学习系统处利用一个或多个第二模型替换一个或多个第一模型。
10.取决于实施例,可以实现一个或多个优点。参考下文的具体实施方式和附图,可以充分理解本发明的这些优点和各种附加目的、特征和优点。
附图说明
11.图1是示出了根据本发明一个实施例的用于处理文本数据的机器学习系统的自适应训练的系统的简化图。
12.图2是示出了根据本发明的一个实施例的作为如图1所示的系统的一部分的机器学习部件的简化图。
13.图3是根据本发明的一个实施例的如图2所示的结果评估部件的简化时序图。
14.图4a是示出了根据本发明的一个实施例的用于处理文本数据的机器学习系统的
自适应训练的方法的简化图。
15.图4b是示出了根据本发明的一个实施例的用于处理文本数据的机器学习系统的自适应训练的方法的简化图。
16.图5是示出了根据本发明一个实施例的用于实现用于处理文本数据的机器学习系统的自适应训练系统的计算系统的简化图。
具体实施方式
17.常规的系统和方法通常不能有效地适应影响由机器学习(ml)系统所预测的结果的准确度的外部因素的变化。常规的系统和方法通常需要进行连续训练,以应对此类变化。特别地,常规ml系统基于历史事实进行训练。例如,历史事实包括由ml系统外部的实体确认为真实的实际结果。因此,当新的历史事实变得可用时,常规的ml系统会连续地被重新训练,以针对外部因素的变化进行校正。
18.本发明的某些实施例涉及处理文本数据的机器学习系统。更具体地,本发明的一些实施例提供了用于处理文本数据的机器学习系统的自适应训练的系统和方法。
19.在一些实施例中,系统和方法提供了一种机器学习系统,该机器学习系统自动适应可以影响由ml系统所预测的结果的准确度的外部因素的变化。例如,预测结果包括对以自然语言编写的合同文档的内容的预测。例如,常规的自然语言处理算法在遇到算法以前没有见过或对其训练过的文档中的语言时,通常容易不准确。
20.在某些实施例中,通过收集附加的真实样本并重新训练ml系统来改进预测结果中的不准确性,而无需创建新的预测算法。例如,真实样本包括由外部评估实体(例如,人类专家)验证和/或校正的预测结果。在一些示例中,系统和方法能够发现预测结果中的不准确。例如,响应于发现预测结果中的不准确,通过从外部评估实体动态收集附加的真实样本来降低不准确性。例如,响应于接收附加的真实样本,ml系统在预定真实间隔之后被自动重新训练。在一个示例中,预定真实间隔表示从外部评估实体接收真实样本时的预定时间量。在一些示例中,如果新模型性能优于ml系统的当前预测模型,则通过重新训练ml系统生成的新预测模型是被提升的。例如,如果新模型的准确度与基于历史真实样本和/或附加真实样本的当前模型的准确度相比有所增加,则新模型的性能优于当前模型。在某些示例中,系统和方法包括至少部分地基于当前模型的准确度动态调整所请求的附加真实样本的数量。
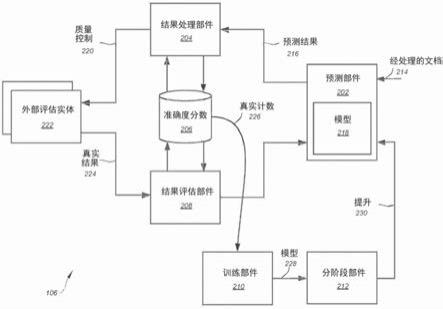
21.某些实施例的益处包括:以预定真实间隔重新训练ml系统的自动性质提高了关于变化的外部因素的适应速度,并减少了外部评估的数量。在一些实施例中,其他益处包括关于雇用人类专家来评估预测结果的成本降低。在某些实施例中,附加益处包括雇用专业软件工程师和/或数据科学家修改ml算法以提高准确度的需求和成本降低。
22.在某些实施例中,起源于计算机技术的一个或多个解决方案克服了计算机技术领域中具体出现的一个或多个问题。其他实施例包括监视ml系统的准确度确定,并且如果满足某些标准,则发出警报以进行ml系统的干预和/或改进。又一实施例包括至少部分地基于以预定频率间隔请求的新真实样本连续训练和生成新预测模型。
23.图1是示出了根据本发明的一个实施例的用于处理文本数据的机器学习系统的自适应训练的系统100的简化图。此图仅为示例,不应过度限制权利要求的范围。本领域的普通技术人员将认识到许多变型、替代物和修改。系统100包括文档组织器部件102、文档处理
部件104、机器学习部件106、提取用户界面(ui)部件108、储存库api部件110和储存库112。例如,文档组织器部件102包括前端ui部件114,并且被配置为组织、分类和选择文档116以存储在储存库112中,和/或由系统100进一步管理和分析文档116。例如,文档处理部件104被包括在储存库api部件110中。
24.在一些实施例中,文档116包括以自然语言编写的文本数据和/或内容。文件116的示例包括合同、专利许可证、商标许可证、版权许可证、技术许可证、合资企业协议、保密协议、研究协议、材料供应协议、制造协议、工作说明以及上述文档的修订和附录。在某些示例中,储存库api部件110被配置为从文档组织器部件102、文档处理部件104、机器学习部件106和/或提取ui部件108接收数据,并将接收到的数据存储在储存库112中。在其他示例中,提取ui部件提供用户界面,用户界面被配置用于使用户与从文档组织器部件102、文档处理部件104、机器学习部件106和/或储存库api部件110接收的数据和文档交互。在一些示例中,提取ui部件的用户界面被配置为允许用户与存储在储存库112中的数据和文档交互。
25.在某些实施例中,文档处理部件104被配置为从文档组织器部件102接收与文档116相关联的数据以进行进一步处理。在一些示例中,由文档处理部件104的处理包括例如,对接收到的文档116的数据应用光学字符识别技术。作为示例,文档处理部件104被配置为解析接收到的数据以识别、分类和标记文档116内的特定部分。在某些示例中,文档处理部件104被配置为至少部分地基于文档116的处理向文档116添加元数据。在其他示例中,文档处理部件104被配置为在与文档116相关联的数据的格式和/或呈现样式之间转换,并且例如,生成所转换的数据的格式化文档。在又其他示例中,文档处理部件104被配置为生成经处理的文档116的报告、注释和/或文档。
26.图2是示出了根据本发明的一个实施例的作为系统100的一部分的机器学习部件106的简化图。此图仅为示例,不应不适当地限制权利要求的范围。本领域的普通技术人员将认识到许多变型、替代物和修改。机器学习部件106包括预测部件202、结果处理部件204、准确度存储器206、结果评估部件208、训练部件210和分阶段部件212。在一些示例中,预测部件202被配置为接收由系统100处理的文档214。例如,经处理的文档214包括文本数据。
27.在一些实施例中,预测部件202被配置为至少部分地基于机器学习系统的一个或多个模型218生成预测结果216。例如,预测结果包括对与经处理的文档214的文本数据相关联的问题的预测答案。在一些示例中,预测部件202被配置为生成对与经处理的文档214的文本数据相关联的问题的预测答案。在某些示例中,预测部件202被配置为至少部分地基于机器学习系统的一个或多个模型218生成与预测答案相关联的优度、预测性误差、稳健性值和/或置信度分数。例如,一个或多个模型218与准确度分数相关联。例如,通过使用有监督、半监督和/或无监督机器学习技术生成一个或多个模型218。在一些示例中,机器学习技术包括神经网络、特征选择和分类、基于规则的学习和/或相似性度量技术。
28.在某些实施例中,结果处理部件204被配置为接收预测结果216。例如,预测结果216包括对与经处理的文档214的文本数据相关联的问题的预测答案。例如,由结果处理部件204响应于请求或推送事件接收对与文本数据相关联的问题的预测答案。
29.根据一些实施例,结果处理部件204被配置为至少部分地基于质量控制参数来确定是否需要由一个或多个外部实体222对预测结果进行评估。在一些示例中,结果处理部件204被配置为如果质量控制参数等于或小于预定质量阈值,则确定需要对预测结果进行评
估。例如,预定质量阈值为10%、20%、30%、40%或50%。
30.根据某些实施例,质量控制参数包括需要由一个或多个外部实体222执行的评估的数量。在一些示例中,结果处理部件204被配置为不确定是否需要由一个或多个外部实体222进行评估直到接收到真实样本的预定最小数量。例如,预定最小数量是基于经处理的文档214的类型、加载和/或集合。例如,预定最小数量等于100、200、300、400或500个真实样本。
31.在一些实施例中,结果处理部件204被配置成至少部分地基于一个或多个因素来生成质量控制参数。一个或多个因素的示例包括与文本数据相关联的一个或多个静态配置参数、与文本数据相关联的当前环境、与请求相关联的请求者的身份、与预测答案相关联的置信度,和/或请求频率。在一些示例中,质量控制参数包括布尔参数。例如,布尔参数(例如,requiresevaluation)的确定如下:
32.requiresevaluation=fieldbase environmentconfig identityscore (datasetsamplecount《datasetminsample)
·
100 (confidence《datasetminconf)
·
100) (hasactiveevent
·
accuracyscalesetting)《random,(等式1)
33.其中fieldbase表示预测评估的最小值,environmentconfig表示基于环境参数(例如,地区、日期、当日时间)的加权值,identityscore表示基于请求者标识(例如,上传者、客户、项目)的加权值,datasetsamplecount表示针对给定客户采集的样本数量,datasetminsample表示在ml系统的训练和为新客户生成预测结果之前需要收集的最小样本数量,confidence表示与由预测部件202生成的预测结果相关联的置信度,datasetminconf表示预测结果避开一个或多个外部实体222的评估所需的最小置信度,hasactiveevent表示活动准确度降低事件的布尔值,accuracyscalesetting表示自动缩放事件所需的评估百分比数,并且random表示0到1范围内的随机数。
34.在某些实施例中,结果处理部件204被配置为响应于至少部分地基于质量控制参数确定需要一个或多个外部实体的评估,将经处理的文档214的文本数据和与文本数据相关联的问题发送到外部评估实体222以进行评估。
35.根据一些实施例,外部评估实体222被配置为评估经处理的文档214的文本数据和与文本数据相关联的问题。在一些示例中,外部实体222被配置为至少部分地基于经处理的文档214的文本数据生成真实结果224。在某些示例中,外部实体222被配置为至少部分地基于经处理的文档214的文本数据生成对问题的真实答案。例如,外部实体222被配置为基于文本数据,通过机械评估、虚拟评估和/或自然评估来评估问题。在一个示例中,外部实体222包括审查问题并基于经处理的文档214的文本数据提供对所审查的问题的真实答案的人类。在其他示例中,外部实体222包括虚拟评估系统,该虚拟评估系统被配置为至少部分地基于经处理的文档214的文本数据的标准和/或特征来生成对特定问题的真实答案。在一些示例中,外部实体222被配置为在不知道由预测部件202生成的预测答案下,基于经处理的文档214的文本数据来评估问题。
36.根据某些实施例,结果评估部件208被配置为从外部评估实体222接收真实结果224。在一些示例中,结果评估部件208被配置为接收由外部评估实体220生成的真实答案。在某些示例中,结果评估部件208被配置为至少部分地基于由外部评估实体222生成的真实答案和由预测部件202生成的预测答案来确定一个或多个准确度参数。在一些示例中,结果
处理部件204被配置为至少部分地基于由结果评估部件208确定的一个或多个准确度参数来增加所需评估的数量。在其他示例中,结果评估部件208被配置为将所确定的一个或多个准确度参数存储在准确度存储器206中以供机器学习系统检取。例如,结果评估部件208被配置为将准确度偏差存储在准确度存储器206中以供机器学习系统检取。例如,准确度偏差等于一个或多个准确度参数和预定最小阈值的差。
37.在一些实施例中,结果评估部件208被配置为响应于一个或多个准确度参数小于预定最小阈值,识别准确度降低事件。例如,预定最小阈值表示准确度阈值。在一些示例中,如果一个或多个准确度参数低于预定最小阈值,则触发准确度降低事件。例如,预定最小阈值表示用户指定的最小准确度值。在某些示例中,结果评估部件208被配置为响应于模型218的准确度分数随着时间的推移增加而增加预定最小阈值。
38.图3是根据本发明的一个实施例的结果评估部件208的简化时序图。此图仅为示例,不应不适当地限制权利要求的范围。本领域的普通技术人员将认识到许多变型、替代物和修改。在一些示例中,结果评估部件208在采样点302
1-n
处从外部评估实体222接收真实结果。例如,在采样点302
1-n
处,结果评估部件208确定准确度参数304。例如,结果评估部件208确定采样点302
1-4
处(例如,采样点1-4处)的准确度参数304大于准确度阈值306。在另一示例中,结果评估部件208确定采样点3025处(例如,采样点5处)的准确度参数304小于准确度阈值306。在又一示例中,结果评估部件208确定在采样点3024和采样点3025之间(例如,在采样点4和采样点5之间),准确度参数从大于准确度阈值306的值变为小于准确度阈值306的值。在某些示例中,结果评估部件208确定时间t0处的准确度参数304等于准确度阈值306。例如,结果评估部件208确定准确度参数从时间t0之前的大于准确度阈值306的值变为时间t0之后的小于准确度阈值306的值。例如,响应于准确度参数304小于准确度阈值306,结果评估部件208识别准确度降低事件308。在一个示例中,准确度降低事件308在时间t0处开始。在一些示例中,结果评估部件208确定时刻t1处的准确度参数304等于准确度阈值306。例如,结果评估部件208确定准确度参数从时间t1之前的小于准确度阈值306的值变为时间t1之后的大于准确度阈值306的值。例如,响应于准确度参数304大于准确度阈值306,结果评估部件208清除准确度降低事件308。在一个示例中,准确度降低事件308在时间t1处结束。在另一示例中,响应于准确度参数304在滚动准确度窗口内(例如,在预定数量的样本或预定持续时间内)大于准确度阈值306,结果评估部件208清除准确度降低事件308。
39.在一些实施例中,结果评估部件208被配置为响应于一个或多个准确度参数等于或大于预定最小阈值,清除识别的准确度降低事件。在一些示例中,响应于准确度降低事件308被清除,结果评估部件208被配置为确定指示由外部评估实体222执行的评估的数量的评估数量。例如,评估数量等于在准确度降低事件308的持续时间内的采样点302的数量。例如,结果评估部件208被配置为将评估数量和真实计数226(truth counter)存储在准确度存储器206中以供机器学习系统检取。在一个示例中,结果评估部件208被配置为如果准确度降低事件308被清除,则存储真实计数226。例如,结果评估部件208被配置为如果准确度降低事件308被清除,则将等式1中的hasactiveevent的值设置为零。在一些示例中,结果评估部件208被配置为响应于识别准确度降低事件308而将真实计数226存储在准确度存储器206中。
40.在某些实施例中,准确度降低事件308的持续时间内的采样点302的数量等于在时
间t0之后并且在时间t1之前的采样点302处从外部评估实体222接收的结果的数量。在一些示例中,响应于结果评估部件208识别准确度降低事件308,结果处理部件204被配置为改变质量控制参数,使得所需外部评估实体222的评估的频率增加。例如,响应于增加所需评估的频率,在准确度降低事件308的持续时间内,采样点302的数量在量上增加。在某些示例中,响应于准确度降低事件308被结果评估部件208清除,结果处理部件204被配置为改变质量控制参数,使得所需外部评估实体222的评估的频率降低。例如,响应于降低所需评估的频率,在准确度降低事件308之外的采样点302的数量在量上降低。
41.参考图2,在某些实施例中,结果评估部件208被配置为响应于一个或多个准确度参数小于预定最小阈值,增加真实计数226。例如,结果评估部件208被配置为增加与经处理的文档214的文本数据相关联的每个问题的真实计数226。例如,结果评估部件208被配置为响应于识别准确度降低事件206将真实计数226存储在准确度存储器206中。在一些示例中,结果评估部件208被配置为至少部分地基于质量控制参数来确定是否需要外部评估实体222对问题进行评估,直到准确度降低事件被清除。例如,结果评估部件208被配置为如果一个或多个准确度参数等于或大于预定最小阈值,则清除准确度降低事件。在某些实施例中,结果处理部件204被配置为增加质量控制参数。
42.根据一些实施例,训练部件210被配置为响应于至少一个问题的真实计数224大于预定真实阈值,生成机器学习系统的一个或多个模型228。例如,预定真实阈值等于500、1000、1500或2000。在一些示例中,训练部件210被配置为通过使用训练数据和与训练数据相关联的已知真实答案的训练模型228来生成机器学习系统的模型228。例如,预测部件202被配置为响应于至少部分地基于训练数据和与训练数据相关联的已知真实答案来训练模型,而使用该经训练的模型来预测对关于非训练数据的问题的答案。例如,训练部件210被配置为通过至少部分地基于真实数据的一个或多个组合训练一个或多个模型228来生成一个或多个模型228。在一个示例中,真实数据包括真实答案和与真实答案相关联的文本数据。在某些示例中,真实数据的一个或多个组合包括在结果评估部件208识别准确度降低事件308之后生成的真实数据。在其他示例中,真实数据的一个或多个组合包括在识别准确度降低事件308之前和之后生成的真实数据。在其他示例中,训练部件210被配置为将一个或多个模型228发送到分阶段部件212。例如,分阶段部件212被配置为从训练部件210接收一个或多个模型228,以确定一个或多个模型228的准确度分数。
43.根据某些实施例,分阶段部件212被配置为确定与一个或多个模型228相关联的准确度分数。例如,分阶段部件212被配置为基于真实数据确定一个或多个模型228中的每个模型的准确度分数。在一些示例中,分阶段部件212被配置为响应于模型228的准确度分数大于与模型218相关联的准确度分数,在机器学习系统的预测部件202处利用一个或多个模型228替换一个或多个模型218。例如,如果模型228中的每个模型的准确度分数大于模型218中的每个模型的准确度分数,则模型228的准确度分数大于模型218的准确度分数。在某些示例中,如果模型228的准确度分数大于模型218的准确度分数,则分阶段部件212被配置为将模型228提升到预测部件202。根据一些示例,分阶段部件212被配置为响应于模型228的准确度分数小于或等于模型218的准确度分数,等待真实计数进一步增加。例如,分阶段部件212被配置为响应于真实计数大于预定真实阈值,生成一个或多个模型228,并确定与该一个或多个模型228相关联的准确度分数。
44.图4a是示出了根据本发明的一个实施例的用于处理文本数据的机器学习系统的自适应训练的方法的简化图。此图仅为示例,不应不适当地限制权利要求的范围。本领域的普通技术人员将认识到许多变型、替代物和修改。方法400包括使用一个或多个处理器执行的过程402-420。尽上文已经使用该方法的一组选定过程示出,但是可以有许多替代物、修改和变型。例如,过程中的一些可以被扩展和/或组合。其他过程可插入上述过程。取决于实施例,过程顺序可以与其他过程互换。
45.在一些实施例中,方法400的一些或所有过程(例如,步骤)由系统100执行。在某些示例中,方法400的一些或所有过程(例如,步骤)由计算机和/或由代码引导的处理器执行。例如,计算机包括服务器计算机和/或客户端计算机(例如,个人计算机)。在一些示例中,根据非瞬态计算机可读介质(例如,在计算机程序产品中,诸如计算机可读闪存驱动器中)包括的指令执行方法400的一些或所有过程(例如,步骤)。例如,非瞬态计算机可读介质可由包括服务器计算机和/或客户端计算机(例如,个人计算机和/或服务器机架)的计算机读取。例如,由非瞬态计算机可读介质包括的指令由包括服务器计算机的处理器和/或客户端计算机的处理器(例如,个人计算机和/或服务器机架)执行。
46.在一些实施例中,在过程402处,接收对与文本数据相关联的问题的预测答案。预测答案至少部分地基于机器学习系统的一个或多个第一模型生成。一个或多个第一模型与第一准确度分数相关联。在过程404处,至少部分地基于质量控制参数来确定是否需要由一个或多个外部实体对问题进行评估。在过程406处,响应于至少部分地基于质量控制参数确定需要由一个或多个外部实体对问题进行评估,将文本数据和与文本数据相关联的问题发送到一个或多个外部实体进行评估。在过程408处,从一个或多个外部实体接收对问题的真实答案。在过程410处,至少部分地基于真实答案和预测答案来确定一个或多个准确度参数。响应于一个或多个准确度参数小于预定最小阈值,在过程412处识别准确度降低事件,并且在过程414处增加质量控制参数。响应于至少一个问题的真实计数大于第一预定真实阈值,在过程416处生成一个或多个第二模型,并且在过程418处确定与该一个或多个第二模型相关联的第二准确度分数。在过程420处,响应于第二准确度分数大于与一个或多个第一模型相关联的第一准确度分数,在机器学习系统处利用一个或多个第二模型替换一个或多个第一模型。
47.图4b是示出了根据本发明的一个实施例的用于处理文本数据的机器学习系统的自适应训练的方法的简化图。此图仅为示例,不应不适当地限制权利要求的范围。本领域的普通技术人员将认识到许多变型、替代物和修改。除了如图4a所示的过程402-420之外,方法430进一步包括使用一个或多个处理器执行的过程432-438。尽上文已经使用该方法的一组选定过程示出,但是可以有许多替代物、修改和变型。例如,过程中的一些可以被扩展和/或组合。其他过程可插入上述过程。取决于实施例,过程顺序可以与其他过程互换。
48.在一些实施例中,方法430的一些或所有过程(例如,步骤)由系统100执行。在某些示例中,方法430的一些或所有过程(例如,步骤)由计算机和/或由代码引导的处理器执行。例如,计算机包括服务器计算机和/或客户端计算机(例如,个人计算机)。在一些示例中,根据非瞬态计算机可读介质(例如,在计算机程序产品中,诸如计算机可读闪存驱动器中)包括的指令执行方法430的一些或所有过程(例如,步骤)。例如,非瞬态计算机可读介质可由包括服务器计算机和/或客户端计算机(例如,个人计算机和/或服务器机架)的计算机读
取。例如,由非瞬态计算机可读介质包括的指令由包括服务器计算机的处理器和/或客户端计算机的处理器(例如,个人计算机和/或服务器机架)执行。
49.在一些实施例中,在过程432处,响应于一个或多个准确度参数等于或大于预定最小阈值,清除准确度降低事件。例如,响应于准确度降低事件被清除,在过程434处确定评估数量,并且在过程436处,将评估数量和真实计数存储在存储器中以供机器学习系统检取。评估数量指示由一个或多个外部实体从识别准确度降低事件起执行的评估的数量。在过程438处,至少部分地基于质量控制参数来确定是否需要由一个或多个外部实体对问题进行评估,直到准确度降低事件被清除。
50.图5是示出了根据本发明一个实施例的用于实现处理文本数据的机器学习系统的自适应训练系统的计算系统的简化图。此图仅为示例,不应不适当地限制权利要求的范围。本领域的普通技术人员将认识到许多变型、替代物和修改。计算系统500包括用于通信信息的总线502或其他通信机构、处理器504、显示器506、光标控制部件508、输入设备510、主存储器512、只读存储器(rom)514、存储单元516和网络接口518。在一些实施例中,方法400的一些或所有过程(例如,步骤)由计算系统500执行。在一些示例中,总线502耦合到处理器504、显示器506、光标控制部件508、输入设备510、主存储器512、只读存储器(rom)514、存储单元516和/或网络接口518。在某些示例中,网络接口耦合到网络520。例如,处理器504包括一个或多个通用微处理器。在一些示例中,主存储器512(例如,随机存取存储器(ram)、高速缓存和/或其他动态存储设备)被配置为存储将由处理器504执行的信息和指令。在某些实施例中,主存储器512被配置为在将由处理器504执行的指令的执行期间存储临时变量或其他中间信息。例如,当存储在处理器504可访问的存储单元516中时,指令将计算系统500呈现到专用机器中,该专用机器被定制以执行指令中指定的操作。在一些示例中,rom 514被配置为存储处理器504的静态信息和指令。在某些示例中,存储单元516(例如,磁盘、光盘或闪存驱动器)被配置为存储信息和指令。
51.一些实施例中,显示器506(例如,阴极射线管(crt)、lcd显示器或触摸屏)被配置为向计算系统500的用户显示信息。在一些示例中,输入设备510(例如,字母数字键和其他键)被配置为向处理器504通信信息和命令。例如,光标控制508(例如,鼠标、轨迹球或光标方向键)被配置为向处理器504通信附加信息和命令(例如,控制显示器506上的光标移动)。
52.根据一些实施例,一种用于被配置为预测对与文本数据相关联的问题的答案的机器学习系统的自适应训练的方法,包括接收与文本数据相关联的问题的预测答案。预测答案至少部分基于机器学习系统的一个或多个第一模型生成。一个或多个第一模型与第一准确度分数相关联。该方法进一步包括至少地基于质量控制参数确定是否需要由一个或多个外部实体对问题进行评估。响应于至少部分地基于质量控制参数确定需要由一个或多个外部实体对问题进行评估,将文本数据和与文本数据相关联的问题发送到一个或多个外部实体进行评估。该方法进一步包括从一个或多个外部实体接收问题的真实答案以及至少部分地基于真实答案和预测答案确定一个或多个准确度参数。响应于一个或多个准确度参数小于预定最小阈值,识别准确度降低事件,并且增加质量控制参数。响应于至少一个问题的真实计数大于第一预定真实阈值,生成一个或多个第二模型,并且确定与该一个或多个第二模型相关联的第二准确度分数。响应于第二准确度分数大于与一个或多个第一模型相关联的第一准确度分数,在机器学习系统处利用一个或多个第二模型替换一个或多个第一模
型。例如,该方法至少根据图1、图2和/或图3实现。
53.在一些示例中,质量控制参数指示所需由一个或多个外部实体执行的评估的数量。在某些示例中,至少部分地基于质量控制参数确定是否需要由一个或多个外部实体对问题进行评估包括至少部分地基于所确定的一个或多个准确度参数增加所需评估的数量。
54.在其他示例中,生成一个或多个第二模型包括至少部分地基于真实数据的一个或多个组合训练一个或多个第二模型。真实数据包括真实答案和与真实答案相关联的文本数据。例如,真实数据的一个或多个组合包括在识别准确度降低事件之后生成的真实数据。例如,真实数据的一个或多个组合包括在识别准确度降低事件之前和之后生成的真实数据。在一些示例中,确定与一个或多个第二模型相关联的第二准确度分数包括基于真实数据确定一个或多个第二模型中的每个模型的准确度分数。
55.在一些示例中,如果一个或多个第二模型中的每个模型的准确度分数大于一个或多个第一模型中的每个模型的准确度分数,则第二准确度分数大于第一准确度分数。在某些示例中,该方法进一步包括响应于第二准确度分数小于或等于第一准确度分数,等待真实计数进一步增加。响应于第二准确度分数小于或等于第一准确度分数,生成一个或多个第二模型,并确定与一个或多个第二模型相关联的第二准确度分数。在其他示例中,方法进一步包括至少部分地基于质量控制参数确定是否需要由一个或多个外部实体对问题进行评估,直到准确度降低事件被清除。
56.在其他示例中,方法进一步包括响应于一个或多个准确度参数等于或大于预定最小阈值,清除准确度降低事件。例如,响应于请求或推送事件接收对与文本数据相关联的问题的预测答案。在一些示例中,该方法进一步包括至少部分地基于一个或多个因素生成质量控制参数。一个或多个因素包括与文本数据相关联的一个或多个静态配置参数、与文本数据相关联的当前环境、与请求相关联的请求者的身份、与预测答案相关联的置信度,以及请求频率。在一些示例中,从一个或多个外部实体接收问题的真实答案包括由一个或多个外部实体基于文本数据,通过机械评估、虚拟评估或自然评估来评估问题。
57.在一些示例中,由一个或多个外部实体在不知道预测答案下,基于文本数据来评估问题。在其他示例中,方法进一步包括将所确定的一个或多个准确度参数存储在存储器中以供机器学习系统检取。例如,该方法进一步包括将准确度偏差存储在存储器中以供机器学习系统检取。准确度偏差等于一个或多个准确度参数和预定最小阈值的差。在某些示例中,该方法进一步包括响应于准确度降低事件被清除,确定评估数量。评估数量指示由一个或多个外部实体从识别准确度降低事件的时间起执行的评估数量。响应于准确度降低事件被清除,将评估数量和真实计数存储在存储器中以供机器学习系统检取。
58.在其他示例中,方法进一步包括响应于识别准确度降低事件,将真实计数存储在存储器中以供机器学习系统检取。例如,方法进一步包括响应于第一准确度分数随着时间增加而增加预定最小阈值。
59.根据某些实施例,一种用于被配置为预测与文本数据相关联的问题的答案的机器学习系统的自适应训练的系统,包括一个或多个处理器和存储指令的存储器。当由一个或多个处理器执行时,指令使得系统接收对与文本数据相关联的问题的预测答案。预测答案至少部分基于机器学习系统的一个或多个第一模型生成。一个或多个第一模型与第一准确度分数相关联。当由一个或多个处理器执行时,指令使得系统进一步执行至少部分地基于
质量控制参数确定是否需要由一个或多个外部实体对问题进行评估。响应于至少部分地基于质量控制参数确定需要由一个或多个外部实体对问题进行评估,将文本数据和与文本数据相关联的问题发送到一个或多个外部实体进行评估。当由一个或多个处理器执行时,指令使得系统进一步执行从一个或多个外部实体接收问题的真实答案,以及至少部分地基于真实答案和预测答案确定一个或多个准确度参数。响应于一个或多个准确度参数小于预定最小阈值,识别准确度降低事件,并且增加质量控制参数。响应于至少一个问题的真实计数大于第一预定真实阈值,生成一个或多个第二模型,并且确定与该一个或多个第二模型相关联的第二准确度分数。响应于第二准确度分数大于与一个或多个第一模型相关联的第一准确度分数,在机器学习系统处利用一个或多个第二模型替换一个或多个第一模型。例如,该系统至少根据图1、图2和/或图3实现。
60.在一些示例,质量控制参数指示所需由一个或多个外部实体执行的评估的数量。在某些示例中,至少部分地基于质量控制参数确定是否需要由一个或多个外部实体对问题进行评估包括至少部分地基于所确定的一个或多个准确度参数增加所需评估的数量。
61.在其他示例中,生成一个或多个第二模型包括至少部分地基于真实数据的一个或多个组合训练一个或多个第二模型。真实数据包括真实答案和与真实答案相关联的文本数据。例如,真实数据的一个或多个组合包括在识别准确度降低事件之后生成的真实数据。例如,真实数据的一个或多个组合包括在识别准确度降低事件之前和之后生成的真实数据。在一些示例中,确定与一个或多个第二模型相关联的第二准确度分数包括基于真实数据确定一个或多个第二模型中的每个模型的准确度分数。在一些示例中,如果一个或多个第二模型中的每个模型的准确度分数大于一个或多个第一模型中的每个模型的准确度分数,则第二准确度分数大于第一准确度分数。
62.根据某些实施例,一种非瞬态计算机可读存储介质存储一个或多个程序。一个或多个程序包括指令,当由一个或多个处理器执行时,指令使得用于被配置为预测与文本数据相关联的问题的答案的机器学习系统的自适应训练的系统执行接收与文本数据相关联的问题的预测答案。预测答案至少部分基于机器学习系统的一个或多个第一模型生成。一个或多个第一模型与第一准确度分数相关联。当由一个或多个处理器执行时,指令使得系统至少部分地基于质量控制参数进一步执行确定是否需要由一个或多个外部实体对问题进行评估。响应于至少部分地基于质量控制参数确定需要由一个或多个外部实体对问题进行评估,将文本数据和与文本数据相关联的问题发送到一个或多个外部实体进行评估。当由一个或多个处理器执行时,指令使得系统进一步执行从一个或多个外部实体接收问题的真实答案,以及至少部分地基于真实答案和预测答案确定一个或多个准确度参数。响应于一个或多个准确度参数小于预定最小阈值,识别准确度降低事件,并且增加质量控制参数。响应于至少一个问题的真实计数大于第一预定真实阈值,生成一个或多个第二模型,并且确定与该一个或多个第二模型相关联的第二准确度分数。响应于第二准确度分数大于与一个或多个第一模型相关联的第一准确度分数,在机器学习系统处利用一个或多个第二模型替换一个或多个第一模型。例如,该系统至少根据图1、图2和/或图3实现。
63.例如,本发明的各种实施例的一些或所有部件分别和/或与至少另一个部件组合,使用一个或多个软件部件、一个或多个硬件部件和/或软件和硬件部件的一个或多个组合来实现。在另一个示例中,本发明的各种实施例的一些或所有部件分别和/或与至少另一个
部件组合,在一个或多个电路(诸如一个或多个模拟电路和/或一个或多个数字电路)中实现。在又一个实施例中,虽然上文所述的实施例指代特定特征,但是本发明的范围还包括具有特征的不同组合的实施例以及不包括所述的全部特征的实施例。在又一个示例中,可以组合本发明的各种实施例和/或示例。
64.附加地,本文所述的方法和系统可以通过包括可由设备处理子系统执行的程序指令的程序代码在许多不同类型的处理设备上实现。软件程序指令可包括源代码、目标代码、机器代码或可操作以使处理系统执行本文所述的方法和操作的任何其他存储数据。然而,也可以使用其他实现,诸如固件或甚至被配置为执行本文所述的方法和系统的适当设计的硬件。
65.系统和方法的数据(例如,关联、映射、数据输入、数据输出、中间数据结果、最终数据结果等)可以在一个或多个不同类型的计算机实现的数据存储中存储和实现,诸如不同类型的存储设备和编程结构(例如,ram、rom、eeprom、闪存、平面文件、数据库、编程数据结构、编程变量、if-then(或类似类型)语句结构、应用程序编程接口等)。注意,数据结构描述用于在数据库、程序、存储器或其他计算机可读介质中组织和存储数据以供计算机程序使用的格式。
66.可以在许多不同类型的计算机可读介质上提供系统和方法,计算机可读介质包括包含指令(例如,软件)的计算机存储机制(例如,cd-rom、软盘、ram、闪存、计算机硬盘驱动器、dvd等)以供处理器在执行中使用,以执行方法的操作并实现本文所述的系统。本文描述的计算机部件、软件模块、功能、数据存储器和数据结构可以直接或间接地彼此连接,以便允许其操作所需的数据流。还应注意,模块或处理器包括执行软件操作的代码单元,并且可以实现为例如子例程代码单元、或实现为软件功能代码单元、或实现为对象(如在面向对象的范例中)、或实现为小程序、或在计算机脚本语言中或实现为另一种类型的计算机代码。软件部件和/或功能可能位于单个计算机上或分布在多个计算机上,具体取决于手头的情况。
67.计算系统可包括客户端设备和服务器。客户端设备和服务器通常彼此远离,并且通常通过通信网络交互。客户端设备和服务器的关系根据在相应计算机上运行且彼此具有客户端设备-服务器关系的计算机程序来产生。
68.本说明书包含用于特定实施例的许多细节。也可将在本说明书中单独的各实施例的情境中所描述的某些特征以组合的形式实现在单个实施例中。反之,也可单独地在多个实施例中、或在任何合适的子组合中实现在单个实施例的情境中所描述的各种特征。此外,尽管上述特征可被描述为在某些组合中起作用,但在某些情况下,可以从组合中移除来自组合的一个或多个特征,并且组合例如可以被指向子组合或子组合的变型。
69.类似地,虽然在附图中以特定顺序描绘了多个操作,但不应当将此理解为要求按所示的特定顺序或顺序地执行此类操作,或者要求要执行所有示出的操作以实现期望的结果。在某些情况下,多任务处理和并行处理可能是有利的。此外,不应当将上文所描述的各实施例中的各种系统部件分开理解为在所有实施例中都要求进行此类分开,并且应当理解,一般可将所描述的程序部件和系统一起集成在单个的软件产品中,或将其封装进多个软件产品中。
70.尽管已经描述了本发明的特定实施例,但是本领域技术人员将理解,存在与所描
述的实施例等效的其他实施例。因此,应当理解,本发明不受所示具体实施例的限制,而仅受所附权利要求书的范围的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。