对话装置、方法以及信息记录介质
1.本技术在日本专利申请2020-152168(申请日:9/10/2020)的基础上,从该申请享有优先的利益。本技术通过参照该申请,包含该申请的全部内容。
技术领域
2.本发明的实施方式涉及对话装置、方法以及信息记录介质。
背景技术:
3.一般而言,对话装置从用户输入的自然语句等文本信息中提取检索所需的检索关键字,使用提取出的检索关键字来检索数据库,根据检索出的结果向用户输出应答。成为检索对象的数据库是1个以上的数据库,例如包括综合了多个数据库功能的1个数据库、相互独立的多个数据库。具体而言,对话装置检索用户等指定的1个以上的数据库。
4.第一,在对话装置检索被指定的1个数据库的情况下,无法输出考虑了未被指定的其他数据库中的检索结果的应答。例如,在基于某个检索关键字在特定的数据库中的检索件数为0件的情况下,对话装置无法进行进一步的检索,而无法继续提示在检索件数的筛选时应使用的其他检索关键字、其他数据库。第二,在对话装置检索被指定的多个数据库的情况下,无法决定优先利用从多个数据库得到的多个检索结果中的哪个检索结果来输出应答。因此,期望一种对话装置,其在优先利用被指定的1个数据库中的检索结果的同时,输出将该检索结果与未指定的其他数据库中的检索结果合并后的应答。
技术实现要素:
5.本发明要解决的技术问题在于,提供一种能够进行灵活的对话的对话装置、方法以及信息记录介质。
6.实施方式的对话装置包含指定部、取得部、提取部、检索部、生成部以及输出部。指定部指定多个数据库中的1个数据库。取得部取得用户输入的文本信息。提取部从所述文本信息提取检索所需的检索关键字。检索部使用所述检索关键字,检索被指定的所述数据库和所述多个数据库中的除了被指定的所述数据库以外的其他数据库。生成部根据在被指定的所述数据库中与所述检索关键字一致的数据件数即第一检索件数、和在所述其他数据库中与所述检索关键字一致的数据件数即第二检索件数,生成应答。输出部将所生成的所述应答输出至所述用户。
7.根据上述结构的对话装置,能够进行灵活的对话。
附图说明
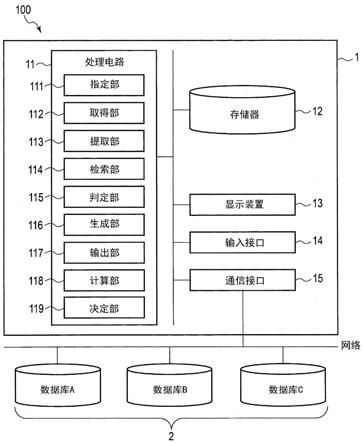
8.图1是表示第一实施方式的对话装置的结构例的框图。
9.图2是表示第一实施方式的对话装置的动作例的流程图。
10.图3是表示与筛选关键字的决定有关的详细内容的流程图。
11.图4是表示存储在多个数据库中的数据表的一例的图。
12.图5是表示多个数据库各自的数据件数的一例的图。
13.图6是表示第二实施方式的对话装置的结构例的框图。
14.图7是表示第二实施方式的对话装置的动作例的流程图。
15.附图标记说明
[0016]1…
对话装置、2
…
数据库、11
…
处理电路、12
…
存储器、13
…
显示装置、14
…
输入接口、15
…
通信接口、111
…
指定部、112
…
取得部、113
…
提取部、114
…
检索部、115
…
判定部、116
…
生成部、117
…
输出部、118
…
计算部、119
…
决定部、120
…
识别部、100
…
对话系统、200
…
数据表、300
…
汇总数据表。
具体实施方式
[0017]
以下,参照附图对实施方式的对话装置进行说明。
[0018]
(第一实施方式)
[0019]
参照图1对第一实施方式的对话装置1的结构例进行说明。
[0020]
对话装置1是从用户所输入的自然语句等文本信息中提取检索所需的检索关键字,使用提取出的检索关键字检索多个数据库2,根据检索出的结果向用户输出应答的装置。具体而言,对话装置1是任务定向型的对话装置,通过安装于服务器等,既可以作为对话专用的硬件来安装,或者也可以作为应用程序等的软件来安装。在本实施方式中,对话装置1包括处理电路11、存储器12、显示装置13、输入接口14以及通信接口15。各构成部通过总线可相互通信地连接。另外,各结构部也可以不通过各个硬件来安装。例如,各构成部中的至少2个也可以通过1个硬件来安装。
[0021]
另外,对话装置1被连接为能够经由网络与多个数据库2通信。另外,包括对话装置1、数据库2以及网络的系统整体也称为对话系统100。
[0022]
处理电路11控制对话装置1的动作。处理电路11具有cpu(central processing unit)、mpu(micro processing unit)、gpu(graphics processing unit)、fpu(floating point unit)等处理器作为硬件。处理电路11通过经由处理器执行在存储器12中展开的程序,来执行与各程序对应的各部(指定部111、取得部112、提取部113、检索部114、判定部115、生成部116、输出部117、计算部118、决定部119)。此外,各部也可以不通过由单独的处理器构成的处理电路来安装。例如,各部也可以通过组合多个处理器而得到的处理电路来安装。
[0023]
指定部111指定多个数据库中的1个数据库。
[0024]
取得部112取得用户输入的文本信息。
[0025]
提取部113从文本信息提取检索所需的检索关键字。
[0026]
检索部114使用检索关键字,检索被指定的数据库和多个数据库中除了被指定的数据库以外的其他数据库。
[0027]
判定部115判定各种命题的真伪。
[0028]
生成部116根据在被指定的数据库中与检索关键字一致的数据件数即第一检索件数、和在其他数据库中与检索关键字一致的数据件数即第二检索件数,来生成应答。
[0029]
输出部117将所生成的应答输出至用户。
[0030]
计算部118针对多个数据库所包含的各个数据表,计算多个数据项目各自的平均
信息量。另外,计算部118使用对多个数据库分别设定的加权,针对多个数据项目各自的平均信息量来计算加权平均。
[0031]
决定部119将多个数据项目中的、平均信息量的加权平均最大的数据项目决定为筛选关键字。
[0032]
存储器12存储有处理电路11使用的数据、程序等信息。存储器12具有ram(random access memory:随机存取存储器)等半导体存储器元件作为硬件。此外,存储器12也可以是在与磁盘(软(注册商标)盘、硬盘)、光磁盘(mo)、光盘(cd、dvd、blu-ray(注册商标))、闪存器(usb闪存器、存储卡、ssd)、磁带等外部存储装置之间读写信息的驱动装置。此外,存储器12的存储区域既可以存在于对话装置1内部,也可以存在于外部存储装置。
[0033]
显示装置13显示由处理电路11生成的数据、存储在存储器12中的数据等信息。作为显示装置13,例如能够使用阴极射线管(crt:cathode ray tube)显示器、液晶显示器(lcd:liquid crystal display)、等离子体显示器、有机el显示器(oeld:organic electro-luminescence display)以及平板终端等显示器。
[0034]
输入接口14接受来自利用对话装置1的用户的输入,将接受到的输入变换为电信号并输出至处理电路11。作为输入接口14,能够使用鼠标、键盘、轨迹球、开关、按钮、操纵杆、触控板、触摸面板显示器、麦克风等物理的操作部件。另外,输入接口14也可以是从与对话装置1分体的外部的输入装置接受输入,将接受到的输入变换为电信号并输出至处理电路11的装置。
[0035]
通信接口15在与数据库2之间经由网络收发数据。通信接口15与外部装置之间能够使用任意的通信标准。
[0036]
数据库2存储各种数据。数据库2例如可以作为存储在服务器中的数据文件而被安装。在本实施方式中设为,数据库2包含多个关系数据库(rdb),多个数据库2分别包含定义了与检索关键字相关联的多个数据项目的数据表。数据库2例如包括数据库a、数据库b以及数据库c。另外,数据库2设为是通过遵循sql(statured query language)等数据库语言的查询(query)来检索的数据库。
[0037]
参照图2对第一实施方式的对话装置的动作例进行说明。
[0038]
在步骤s101中,指定部111指定多个数据库2中的1个数据库。例如,对话装置1接受用户经由键盘等输入接口14输入的指示,指定与该指示对应的数据库。此外,对话装置1也可以指定默认的数据库,还可以根据用户的资料(profile)等自动地指定数据库。即,作为数据库的指定方法,能够应用任意的方法。另外,对在对话结束之前被指定了一次的数据库进行保存并设为并不再次询问。
[0039]
在步骤s102中,取得部112取得用户输入的文本信息。例如,对话装置1取得用户经由键盘(键输入)、触控板(touchpad)以及触摸面板显示器(基于手写识别的输入)、头戴式耳机以及ai扬声器等的麦克风(基于声音识别的输入)等输入接口14输入的文本信息。所取得的文本信息被存储在存储器12中。
[0040]
在步骤s103中,提取部113从文本信息提取检索所需的检索关键字。在检索关键字的提取中,作为第一提取方法,可以预先准备包含成为提取对象的多个关键字在内的列表,如果所取得的文本信息中包含有该列表上的任意一个关键字,则提取相应的关键字。第一提取方法例如准备“电阻器”、“电容器”、“晶体管”这样的多个关键字,如果所取得的文本信
息是“寻找电阻器”,则由于该多个关键字中的“电阻器”被包含在文本信息中,因此提取“电阻器”。
[0041]
作为第二提取方法,可以预先准备包含成为提取对象的关键字在内的多个文章的列表,如果所取得文本信息中包含有该列表上的任意一个文章,则提取该文章中包含的关键字。第二提取方法例如准备“寻找
○○”
、“检索
△△”
、“有
□□
吗”这样的多个文章,如果所取得的文本信息是“寻找电阻器”,则提取与
○○
的部分对应的“电阻器”。
[0042]
作为第三提取方法,也可以预先大量地准备包含成为提取对象的关键字在内的文章和该文章中成为提取对象的关键字(标签)的组,使用该组作为学习数据来制作机器学习模型,通过该机器学习模型进行提取。第三提取方法例如准备“寻找电阻器”这样的文章与对该文章的标签即“电阻器”的组、“检索电容器”这样的文章与针对该文章的标签即“电容器”的组、“有晶体管吗”这样的文章与针对该文章的标签即“晶体管”的组那样的多个组作为学习数据,通过使学习用模型学习文章与标签的关系从而制作机器学习模型。如果使用该机器学习模型所取得的文本信息是“寻找电阻器”,则基于学习到的文章与标签的关系提取“电阻器”。即,作为检索关键字的提取方法,能够应用任意的方法。所提取的检索关键字被存储在存储器12中。
[0043]
在步骤s104中,检索部114使用检索关键字,检索被指定的数据库和多个数据库2中除了被指定的数据库以外的其他数据库。例如,对话装置1基于提取出的检索关键字,制作基于sql的查询,检索多个数据库2。查询例如是包含“select*from database a where name like%电阻器%”那样的检索关键字在内的指令语句。多个搜索结果与检索到的每个数据库建立关联地存储在存储器12中。在本实施方式中设为,检索结果是在数据库2中与检索关键字一致的数据件数。
[0044]
在步骤s105中,判定部115判定在被指定的数据库中与检索关键字一致的数据件数(第一检索件数)是否为0件。在判定为是0件的情况下(步骤s105的是),进入到步骤s106。在判定为不是0件、即1件以上的情况下(步骤s105的否),进入到步骤s109。
[0045]
在步骤s106中,判定部115判定在未被指定的其他数据库中与检索关键字一致的数据件数(第二检索件数)是否为0件。在判定为是0件的情况下(步骤s106的是),进入到步骤s107。在判定为不是0件、即1件以上的情况下(步骤s106的否),进入到步骤s108。
[0046]
在步骤s107中,生成部116生成询问与检索关键字不同的关键字的应答。到本步骤为止,判明了若是该检索关键字则无法在被指定的数据库以及其他数据库中进行进一步的检索,因此对话装置1生成“reject()”指令。本指令表示未受理该检索关键字这一情况,是询问不同关键字的应答的一例。所生成的应答被存储在存储器12中。
[0047]
在步骤s108中,生成部116生成询问与被指定的数据库不同的数据库的应答。到本步骤为止,判明了如果检索与被指定的数据库不同的其他数据库,则能够发现数据,因此对话装置1生成“request(db)”指令。本指令是询问新指定的其他数据库的应答的一例。所生成的应答被存储在存储器12中。或者,对话装置1也可以生成回答在其他数据库中的检索件数的应答。
[0048]
在步骤s109中,判定部115判定在被指定的数据库中与检索关键字一致的数据件数(第一检索件数)是否为阈值以下。该阈值既可以设定为用户经由输入接口14输入的任意的值,也可以设定为预先存储在存储器12中的任意的值。在判定为是阈值以下的情况下(步
骤s109的是),进入到步骤s110。在判定为不是阈值以下、即大于阈值的情况下(步骤s109的否),进入到步骤s111。
[0049]
在步骤s110中,生成部116生成对在被指定的数据库中的检索件数进行回答的应答。到本步骤为止,判明了在被指定的数据库中的检索件数为阈值以下,因此对话装置1生成“offer(contents)”指令。本指令是回答在指定的数据库中的检索件数的应答的一例。所生成的应答被存储在存储器12中。
[0050]
在步骤s111中,生成部116生成询问在被指定的数据库中的检索件数的筛选中所需的筛选关键字的应答。到本步骤为止,判明了在被指定的数据库中的检索件数大于阈值,因此对话装置1生成“request(slot)”指令。本指令是询问用于筛选检索件数的数据项目(也称为时隙)的应答的一例。所生成的应答被存储在存储器12中。另外,筛选关键字相当于成为询问对象的数据项目,与该筛选关键字的决定有关的详细流程在图3中后述。
[0051]
在步骤s112中,输出单元117向用户输出所生成的应答。对话装置1例如将所生成的指令输出至显示装置13。另外,所生成的应答是机械能够理解的形式的信息(指令),因此对话装置1也可以变换为人能够理解的形式的信息(文本信息)并输出。在应答的变换中,作为第一变换方法,也可以在存储器12中预先准备“$name$的检索结果是$count$件”这样的多个定型语句,通过在$name$中嵌入检索关键字、在$count$中嵌入检索件数来进行变换。作为第二变换方法,也可以预先大量准备检索关键字、检索件数、以及生成的文章的组,使用该组作为学习数据生成机器学习模型,通过该机器学习模型而输出。即,作为变换方法,可以应用任意的方法。之后,对话装置1将变换为文本信息的应答输出至显示装置13。另外,用户观察显示装置13所输出的应答,因此也可以说对用户输出应答。
[0052]
例如,对话装置1从存储器12取得在步骤s107中生成的“reject()”指令,变换为“无法检索。请用其他关键字进行检索”这样的应答语句并输出至显示装置13。另外,对话装置1从存储器12取得在步骤s108中生成的“request(db)”指令,变换为在“东京事业所的数据库中无法检索。请指定其他事业所的数据库”这样的应答语句并输出至显示装置13。另外,对话装置1从存储器12取得在步骤s110中生成的“offer(contents)”指令,变换为“检索结果为10件”这样的应答语句并输出至显示装置13,另外,对话装置1从存储器12取得在步骤s111中生成的“request(slot)”指令,变换为“请告知〇〇(数据项目)”这样的应答语句并输出至显示装置13。另外,在slot中放入对话装置1询问的数据项目,例如如果slot是电压(voltage),则成为request(voltage)指令。在该情况下,对话装置1从存储器12取得request(voltage)指令,变换为“电压是几个”这样的应答语句并输出至显示装置13。
[0053]
另外,本动作例所示的各步骤能够适当变更顺序。例如,步骤s101可以处于步骤s104之前的任意阶段。另外,步骤s105以及步骤s106也可以相互调换顺序。
[0054]
参照图3对与筛选关键字的决定有关的详细内容进行说明。
[0055]
在步骤s201中,计算部118针对多个数据库2所包含的各个数据表中,计算多个数据项目各自的数据件数。具体而言,对话装置1针对被指定的数据库以及未被指定的其他数据库中的多个数据项目的每一个中,计算各数据项目的每个值的数据件数。
[0056]
例如,假设在多个数据库2中存储有图4所示的数据表200。数据表200存储与电气部件有关的数据,作为数据项目包含“部件id”、“部件名”以及“型号”。部件id是分配给各个记录的序列号,被分配从0001起各增加1的值。部件名是电气部件的名称,包含“电阻器”、“电容器”以及“晶体管”作为数据值。型号是各电气部件固有的识别编号,包含“abc”、“def”以及“ghi”作为数据值。另外,即使是相同的部件名,也存在型号不同的情况。进而,即使是同一型号,也存在部件名不同的情况。另外,也存在同一记录重复的情况。这样,在数据表200中存储有多个将部件名和型号建立对应而得到的记录(数据)。
[0057]
对话装置1针对“部件名”分别计算具有“电阻器”的数据件数、具有“电容器”的数据件数、具有“晶体管”的数据件数。同样地,对话装置1针对“型号”分别计算具有“abc”的数据件数、具有“def”的数据件数、具有“ghi”的数据件数。同样地,对话装置1针对多个数据库2所包含的各个数据表进行计算。作为计算结果,多个数据库2各自的数据件数如图5所示的汇总数据表300那样表示。
[0058]
在步骤s202中,计算部118针对多个数据库2所包含的各个数据表,计算多个数据项目各自的平均信息量。各数据项目的平均信息量反映各数据项目中的各数据值的件数的偏差,平均信息量越高,表示各数据值的件数的偏差越小,是均等的。根据这样的性质,由于平均信息量更高的数据项目包含更多的信息,因此对检索件数的筛选是有用的。
[0059]
例如,考虑关于汇总数据表300来计算多个数据项目各自的平均信息量的情况。平均信息量通过以下的式子算出。
[0060]
[数式1]
[0061][0062]
h(sj)表示数据项目(时隙)sj中的平均信息量。各数据项目sj具有多个值vi。p(vi)是将与值vi有关的数据件数除以数据项目sj所包含的全部的数据件数而得到的数值。
[0063]
针对汇总数据表300中,基于数式(1),如以下那样求出多个数据库2中的每个数据库2的各数据项目的平均信息量。
[0064]
ha(p
部件名
)=0.477、ha(p
型号
)=0.439
[0065]
hb(p
部件名
)=0.185、hb(p
型号
)=0.461
[0066]
hc(p
部件名
)=0.346、hc(p
型号
)=0.415
[0067]
另外,ha(p
部件名
)表示与数据库a的数据项目“部件名”有关的平均信息量。
[0068]
在步骤s203中,计算部118使用对多个数据库2分别设定的加权,针对多个数据项目各自的平均信息量来计算加权平均。具体而言,对话装置1将对被指定的数据库设定的加权设定为比对其他数据库设定的加权大的值。
[0069]
例如,考虑针对汇总数据表300的各数据项目的平均信息量来计算加权平均的情况。平均信息量的加权平均通过以下的式子算出。
[0070]
[数式2]
[0071][0072]hall
表示平均信息量的加权平均。wi是针对多个数据库2的每一个而设定的加权。wi具有多个值,各值的总和为1。
[0073]
针对汇总数据表300,基于数式(2),如以下那样求出各数据项目的平均信息量的
加权平均。另外,设为:多个数据库2中、被指定的数据库设为数据库a、未被指定的其他数据库是数据库b以及数据库c。
[0074]hall
(p
部件名
)=3/5*ha(p
部件名
) 1/5*hb(p
部件名
) 1/5*hc(p
部件名
)=0.392
[0075]hall
(p
型号
)=3/5*ha(p
型号
) 1/5*hb(p
型号
) 1/5*hc(p
型号
)=0.439、
[0076]
另外,设定为:数据库a的加权wa=3/5、数据库b的加权wb=1/5、数据库c的加权wc=1/5。
[0077]
在步骤s204中,决定部119将多个数据项目中的平均信息量的加权平均最大的数据项目决定为筛选关键字。各数据项目的平均信息量为,各数据值的数据件数越均等则越大,因此若是平均信息量更大的数据项目,包含用户搜索的数据的概率越高。在上述的例子中,由于h
all
(p
型号
)比h
all
(p
部件名
)大,因此对话装置1将数据项目“型号”决定为筛选关键字。另外,筛选关键字作为对话装置1询问的数据项目(时隙)而在步骤s112中被使用。
[0078]
根据以上所示的第一实施方式,生成重视用户所指定的数据库中的检索结果、并且考虑了其他数据库中的检索结果的应答。由此,即使被指定的数据库的检索件数为0件,也能够考虑其他数据库中的检索结果来进行灵活的对话。另外,在被指定的数据库的检索件数为1件以上且比阈值大的情况下,能够优先利用被指定的数据库的检索结果、并且进一步考虑其他数据库的检索结果地、决定作为筛选关键字进行询问的数据项目。
[0079]
(第二实施方式)
[0080]
参照图6对第二实施方式的对话装置的结构例进行说明。在第二实施方式中,对话装置1决定从用户发出的声音信息中提取出的多个检索关键字中的、最接近用户的发出内容的检索关键字(正确关键字)。另外,第二实施方式的对话装置1的结构,除了第一实施方式的结构以外,还在处理电路11中具有识别部120。
[0081]
识别部120对声音信息进行声音识别并变换为文本信息。
[0082]
参照图7对第二实施方式的对话装置的动作例进行说明。
[0083]
在步骤s301中,指定部111指定多个数据库中的1个数据库。步骤s301与步骤s101相同。
[0084]
在步骤s302中,识别部120对用户通过声音输入的声音信息进行声音识别,并变换为文本信息。具体而言,对话装置1对用户经由麦克风等输入接口14输入的声音信息进行声音识别。声音信息是反映了用户的发言的声音信号,是与一定期间中的声音的振幅、频率的时间变化有关的波形信息。对于向文本信息的变换,只要应用一般的声音识别处理中使用的现有技术即可,例如,可以是基于声学模型、语言模型的声音识别。在本实施方式中,对话装置1根据识别的可靠度,变换为包含多个变换候选在内的文本信息。
[0085]
在步骤s303中,取得部112取得变换后的文本信息。所取得的文本信息被存储在存储器12中。
[0086]
在步骤s304中,提取部113从变换后的文本信息提取多个搜索关键字。具体而言,对话装置1从包含多个变换候选在内的文本信息中分别提取与各变换候选对应的检索关键字。提取出的多个检索关键字被存储在存储器12中。
[0087]
在步骤s305中,检索部114使用多个检索关键字,检索被指定的数据库和未被指定的其他数据库。步骤s305与步骤s104相同。
[0088]
在步骤s306中,判定部115判定在被指定的数据库中与多个检索关键字一致的数
据件数是否为0件。在判定为是0件的情况下(步骤s306的是),进入到步骤s307。在判定为不是0件、即1件以上的情况下(步骤s306的否),进入到步骤s310。
[0089]
在步骤s307中,判定部115判定在未被指定的其他数据库中与多个检索关键字一致的数据件数是否为0件。在判定为是0件的情况下(步骤s307的是),进入到步骤s308。在判定为不是0件、即1件以上的情况下(步骤s307的否),进入到步骤s309。
[0090]
在步骤s308中,生成部116生成询问与多个检索关键字不同的关键字的应答。到本步骤为止,判明了若是该多个检索关键字,则无法在被指定的数据库以及其他数据库中进行进一步的检索,因此对话装置1生成“reject()”指令。本指令表示不受理该多个检索关键字,是询问不同关键字的应答的一例。所生成的应答被存储在存储器12中。
[0091]
在步骤s309中,生成部116生成如下应答,该应当为,将多个检索关键字中的、其他数据库中的检索件数的总和最大的检索关键字作为正确关键字,而回答其他数据库中的正确关键字的检索件数的应答。到本步骤为止,判明了在被指定的数据库中的检索件数为0件,其他数据库中的检索件数为1件以上,因此对话装置1生成“offer(contents)”指令。本指令是回答其他数据库中的正解关键字的检索件数的应答的一例。所生成的应答被存储在存储器12中。
[0092]
在步骤s310中,生成部116生成如下应答,该应当为,将多个检索关键字中的、在被指定的数据库中的检索件数为1件以上的检索关键字作为正确关键字,而回答该正确关键字的检索件数的应答。到本步骤为止,判明了在被指定的数据库中的检索件数为1件以上,因此对话装置1生成“offer(contents)”指令。本指令是回答在被指定的数据库中的正解关键字的检索件数的应答的一例。所生成的应答被存储在存储器12中。
[0093]
另外,在s310中,在存在多个符合正确关键字的检索关键字的情况下,也可以将该多个检索关键字中的声音识别的可靠度最大的检索关键字作为正确关键字。或者,也可以将该多个检索关键字中的、被指定的数据库中的检索件数最大的检索关键字作为正确关键字。当然,对于多个检索关键字中的1个检索关键字,在被指定的数据库中得到了1件以上的检索件数的情况下,将该检索关键字作为正确关键字即可。
[0094]
在步骤s311中,输出单元117向用户输出所生成的应答。步骤s311与步骤s112相同。
[0095]
以上,对第二实施方式的对话装置1的动作的概略进行了说明。在此,作为具体例,考虑如下情况:用户指定数据库a,对话装置1使用多个检索关键字,检索被指定的数据库a和作为未被指定的其他数据库的数据库b、以及数据库c。
[0096]
例如,假设声音识别的结果是,按照声音识别的可靠度从高到低的顺序,作为用户的发言语句而得到“寻找abc”、“寻找abe”、“寻找abp”这3个候选。对话装置1从各候选中提取“abc”、“abe”、“abp”作为多个检索关键字。接着,使用该多个检索关键字检索各数据库的结果如下。
[0097]
select*from database a where code like%abc%-》0
[0098]
select*from database b where code like%abc%-》0
[0099]
select*from database c where code like%abc%-》0
[0100]
select*from database a where code like%abe%-》0
[0101]
select*from database b where code like%abe%-》10
[0102]
select*from database c where code like%abe%-》0
[0103]
select*from database a where code like%abp%-》0
[0104]
select*from database b where code like%abp%-》10
[0105]
select*from database c where code like%abp%-》20
[0106]
例如检索结果“select*from database a where code like%abc%-》0”表示“数据库a中作为型号(code)而包括“abc”的数据件数为0件”。
[0107]
根据上述检索结果,如以下那样求出被指定的数据库a中的各检索关键字的检索件数的总和、其他数据库b以及数据库c中的各检索关键字的检索件数的总和。
[0108]
counta(abc)=0,count
b c
(abc)=0
[0109]
counta(abe)=0,count
b c
(abe)=10
[0110]
counta(abp)=0,count
b c
(abp)=30
[0111]
例如,“counta(abc)=0”表示数据库a中的“abc”的检索结果为0件。“count
b c
(abc)=0”表示数据库b以及数据库c中的“abc”的检索结果为0件。
[0112]
根据上述检索结果可知,在被指定的数据库a中,多个检索关键字“abc”、“abe”、“abp”的检索件数为0件,在其他数据库b以及数据库c中,该多个检索关键字的检索件数为1件以上。因此,进行与步骤s309相当的处理。在此,由于多个检索关键字中的、其他的数据库b以及数据库c中的检索件数的总和最大的检索关键字是“abp”,因此对话装置1将“abp”决定为正确关键字。最后,生成回答“abp”在其他数据库b以及数据库c中的检索件数的如以下那样的应答,并输出至显示装置13。“通过abp进行了检索,但未找到。在数据库b中找到了10件,在数据库c中找到了20件。
[0113]
根据以上说明的第二实施方式,即使在多个检索关键字中无法根据用户所指定的数据库的检索结果来决定正确关键字的情况下,也能够通过利用其他数据库的检索结果来决定正确关键字。即,与第一实施方式同样,能够进行灵活的对话。
[0114]
对本发明的几个实施方式进行了说明,但这些实施方式是作为例子而提示的,并不意图限定发明的范围。这些实施方式能够以其他各种方式实施,在不脱离发明的主旨的范围内,能够进行各省略、置换、变更。这些实施方式及其变形包含在发明的范围或主旨中,同样包含在权利要求书所记载的发明及其等同的范围内。
[0115]
另外,能够将上述的实施方式汇总为以下的技术方案。
[0116]
(技术方案1)
[0117]
一种对话装置,具备:
[0118]
指定部,指定多个数据库中的1个数据库;
[0119]
取得部,取得用户输入的文本信息;
[0120]
提取部,从所述文本信息中提取检索所需的检索关键字;
[0121]
检索部,使用所述检索关键字,检索被指定的所述数据库和所述多个数据库中的除了被指定的所述数据库以外的其他数据库;
[0122]
生成部,根据在被指定的所述数据库中与所述检索关键字一致的数据件数即第一检索件数、和在所述其他数据库中与所述检索关键字一致的数据件数即第二检索件数,生成应答;以及
[0123]
输出部,将所生成的所述应答输出至所述用户。
[0124]
(技术方案2)
[0125]
根据上述技术方案1,
[0126]
在所述第一检索件数为0件、并且所述第二检索件数为0件的情况下,所述生成部生成询问与所述检索关键字不同的关键字的应答。
[0127]
(技术方案3)
[0128]
根据上述技术方案1或技术方案2,
[0129]
在所述第一检索件数为0件、并且所述第二检索件数为1件以上的情况下,所述生成部生成询问与被指定的所述数据库不同的数据库的应答。
[0130]
(技术方案4)
[0131]
根据上述技术方案1或技术方案2,
[0132]
在所述第一检索件数为0件、并且所述第二检索件数为1件以上的情况下,所述生成部生成回答所述第二检索件数的应答。
[0133]
(技术方案5)
[0134]
根据上述技术方案1至技术方案4中任一项,
[0135]
在所述第一检索件数为1件以上、并且为阈值以下的情况下,所述生成部生成回答所述第一检索件数的应答。
[0136]
(技术方案6)
[0137]
根据上述技术方案1至技术方案5中任一项,
[0138]
在所述第一检索件数为1件以上、并且大于阈值的情况下,所述生成部生成询问所述第一检索件数的筛选所需的筛选关键字的应答。
[0139]
(技术方案7)
[0140]
根据上述技术方案6,
[0141]
所述多个数据库分别包含定义了与所述检索关键字关联的多个数据项目的数据表,
[0142]
所述对话装置还具备:
[0143]
计算部,针对所述多个数据库所包含的各个数据表,计算所述多个数据项目各自的平均信息量,并且使用对所述多个数据库分别设定的加权,对于所述多个数据项目各自的平均信息量来计算加权平均;以及
[0144]
决定部,将所述多个数据项目中的所述平均信息量的加权平均最大的数据项目决定为所述筛选关键字。
[0145]
(技术方案8)
[0146]
根据上述技术方案1至技术方案7中任一项,
[0147]
还具备识别部,该识别部对声音信息进行声音识别并变换为文本信息,
[0148]
所述取得部取得变换后的所述文本信息,
[0149]
所述提取部从变换后的所述文本信息中提取多个检索关键字,
[0150]
所述检索部使用所述多个检索关键字,检索被指定的所述数据库和所述其他数据库,
[0151]
所述生成部在被指定的所述数据库中的所述多个检索关键字的检索件数为0件、并且所述其他数据库中的所述多个检索关键字的检索件数为1件以上的情况下,将所述多
个检索关键字中的、在所述其他数据库中的检索件数的总和最大的检索关键字作为正确关键字,生成应答,该应答回答所述其他数据库中的所述正确关键字的检索件数。
[0152]
(技术方案9)
[0153]
一种对话方法,
[0154]
指定多个数据库中的1个数据库;
[0155]
取得用户输入的文本信息;
[0156]
从所述文本信息中提取检索所需的检索关键字;
[0157]
使用所述检索关键字,检索被指定的所述数据库和所述多个数据库中的除了被指定的所述数据库以外的其他数据库;
[0158]
根据在被指定的所述数据库中与所述检索关键字一致的数据件数即第一检索件数、和在所述其他数据库中与所述检索关键字一致的数据件数即第二检索件数来生成应答;
[0159]
将所生成的所述应答输出至所述用户。
[0160]
(技术方案10)
[0161]
一种信息记录介质,存储用于使计算机实现如下功能的对话程序:
[0162]
指定功能,指定多个数据库中的1个数据库;
[0163]
取得功能,取得用户输入的文本信息;
[0164]
提取功能,从所述文本信息中提取检索所需的检索关键字;
[0165]
检索功能,使用所述检索关键字,检索被指定的所述数据库和所述多个数据库中的除了被指定的所述数据库以外的其他数据库;
[0166]
生成功能,根据在被指定的所述数据库中与所述检索关键字一致的数据件数即第一检索件数、和在所述其他数据库中与所述检索关键字一致的数据件数即第二检索件数,生成应答;以及
[0167]
输出功能,将所生成的所述应答输出至所述用户。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。