一种基于pso和双向gru的短期负荷预测模型
技术领域
1.本发明涉及电力系统负荷预测领域,具体为一种基于pso和双向 gru的短期负荷预测模型。
背景技术:
2.电力系统负荷预测是电力系统规划和稳定、安全、经济运行的基础,根据预测期限可以将负荷预测分为长期预测,中期预测,短期预测和超短期预测,不同的预测类型对电网有着不同的应用目的,其中短期负荷预测一般指当前时刻往后1小时到1周的负荷预测,适用于火电分配及水火协调等方面,可靠的预测结果有利于提高发电设备的利用率,降低电力网络的运营成本,而随着电网市场化改革的推进,有效的短期负荷预测对实时电价的影响更加明显,但是随着电网规模的不断扩大,负荷多样性的增加,高效和精确的短期负荷预测变得更加困难,这就要求超短期的负荷预测方法同时具有快速和准确的特点;
3.目前,用于负荷预测的方法主要可以分为两大类,分别是传统的统计学方法和新兴的机器学习方法,统计学方法包括了多元线性回归模型、卡尔曼滤波器模型、以及时间序列模型等,它建立的模型具有比较明确的数学形式,数据分布的假定和模型的合理性决定了预测结果好坏,而由于电力负荷具有复杂性和非线性的特点,很难做出较为符合实际的分布假定和建立明确的数学模型,因此多数的统计学方法在进行短期负荷预测时效果并不理想,机器学习方法包括了包括模糊推理系统、人工神经网络和支持向量机等,这些方法能够较好的处理非线性问题,因此预测的准确率有所提高,但也存在一些其它问题,如缺乏自学能力,无法处理大规模数据,破坏数据的时序特征,手动特征选择等。
技术实现要素:
4.本发明的目的就在于为了解决传统预测模型无法充分考虑历史时期以及未来时期负荷影响因素对当前预测负荷的影响、无法自动寻找gru神经网络合适的参数的技术问题,因此而提出一种基于pso和双向gru的短期负荷预测模型。
5.本发明的目的可以通过以下技术方案实现:一种基于pso和双向 gru的短期负荷预测模型,包括如下步骤:
6.(1)对样本数据进行预处理,剔除异常数据,填充残缺数据,将输入数据转换为矩阵形式,初始化pso算法参数;
7.(2)定义适应度,采用bigru网络预测值的均方差作为粒子适应度值fit;
8.式中y为真实值,y’为预测值;
9.(3)以粒子的位置信息作为bigru网络的参数,构建多个bigru 网络;
10.(4)训练所有网络,得到每个粒子的自适应度值,更新个体极值和群体极值;
11.(5)根据个体极值和群体极值用非线性惯性权值迭代更新粒子速度和位置信息;
12.(6)满足条件或达到最大迭代次数后进入步骤(7),否则返回执行步骤(3);
13.(7)得到优化后的参数,提高迭代次数,重新训练bigru网络;
14.(8)通过训练好的pso-bigru网络进行预测。
15.进一步在于:所述pso算法为粒子群优化算法,整个算法由多个粒子组成,每个粒子在优化过程中都是一种解,假如有n个粒子,粒子群{zi∈rd,i=1,2,
…
n}代表一个种群,粒子群各粒子在d维空间中的坐标为zi=(x
i1
,x
i2
,
…
,x
id
,),每一个粒子在d维空间中进行运动,其速度为vi=(v
i1
,v
i2
,
…
,v
id
,),其自身的历史最好位置为pi= (p
i1
,p
i2
,
…
,p
id
,),整个粒子群的最好位置为: pg=(p
g1
,p
g2
,
…
,p
gd
,),粒子群在d维空间中不断地运动和改变方向来更新位置,其第k代种群中的位置和速度更新为:
16.x
idk 1
=x
idk
v
idk 1
17.v
idk
=ωv
idk-1
c1r1(p
idk-1-x
idk-1
) c2r2(p
gdk-1-x
gdk-1
)
18.其中,ω∈[0,1]为惯性权重,表征对自身当前位置的信任度;c1、 c2为加速度系数,使粒子向组内最优个体进行学习,每次总结最后达到组内最优点;r1、r2是范围为[0,1]的随机实数,粒子xi为 (g
1i
,g
2i
,εi),g
1i
表示bigru网络第一个隐含层的神经元个数,g
2i
表示bigru网络第二个隐含层的神经元个数,εi表示bigru网络的学习率。
[0019]
进一步在于:所述bigru的表达式为:
[0020][0021]
式中:α
t
为时刻t信息前向传播gru单元隐层输出权重;β
t
为时刻t信息后向传播gru单元隐层输出权重;b
t
为对应的偏置量; g
ru
为门控循环单元,其当前时刻的隐藏层状态h
t
由沿时间前向传播的时刻(t-1)隐藏层输出沿时间后向传播的时刻(t-1)隐藏层输出以及当前时刻输入x
t
3个部分共同决定,bigru在结构上可以看成是前向与后向传播gru的组合,时刻t的隐藏层输出为信息前向传播隐藏层输出和信息后向传播隐藏层输出线性叠加的结果。
[0022]
进一步在于:所述gru是lstm的一种变体,gru模型内部由更新门和重置门构成。
[0023]
进一步在于:所述pso算法是一种随机的、并行的优化算法。
[0024]
与现有技术相比,本发明的有益效果是:
[0025]
bigru网络能够充分考虑历史时期以及未来时期负荷影响因素对当前预测负荷的影响,同时,通过粒子群算法来优化bigru网络的隐含层神经元数,学习率,从而得到合适的网络参数,提高bigru网络的预测精度,以历史负荷作为网络输入数据,迭代输入,充分挖掘数据的内部信息,建立预测模型,提高了短期负荷预测精度。
附图说明
[0026]
为了便于本领域技术人员理解,下面结合附图对本发明作进一步的说明。
[0027]
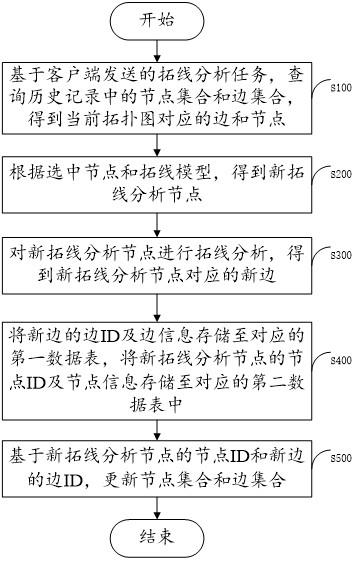
图1是本发明实施例提供的一种基于pso和双向gru的短期负荷预测模型的具体流
程图。
[0028]
图2是本发明实施例提供的一种基于pso和双向gru的短期负荷预测模型的gru网络结构示意图。
[0029]
图3是本发明实施例提供的一种基于pso和双向gru的短期负荷预测模型的双向gru结构模型示意图。
具体实施方式
[0030]
下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0031]
请参阅图1所示,本实施例提供了一种基于pso和双向gru的短期负荷预测模型,包括如下步骤:
[0032]
(1)对样本数据进行预处理,剔除异常数据,填充残缺数据,将输入数据转换为矩阵形式,初始化pso算法参数;
[0033]
(2)定义适应度,采用bigru网络预测值的均方差作为粒子适应度值fit;
[0034]
式中y为真实值,y’为预测值;
[0035]
(3)以粒子的位置信息作为bigru网络的参数,构建多个bigru 网络;
[0036]
(4)训练所有网络,得到每个粒子的自适应度值,更新个体极值和群体极值;
[0037]
(5)根据个体极值和群体极值用非线性惯性权值迭代更新粒子速度和位置信息;
[0038]
(6)满足条件或达到最大迭代次数后进入步骤(7),否则返回执行步骤(3);
[0039]
(7)得到优化后的参数,提高迭代次数,重新训练bigru网络;
[0040]
(8)通过训练好的pso-bigru网络进行预测。
[0041]
pso算法为粒子群优化算法,整个算法由多个粒子组成,每个粒子在优化过程中都是一种解,假如有n个粒子,粒子群{zi∈rd,i= 1,2,
…
n}代表一个种群,粒子群各粒子在d维空间中的坐标为zi= (x
i1
,x
i2
,
…
,x
id
,),每一个粒子在d维空间中进行运动,其速度为vi= (v
i1
,v
i2
,
…
,v
id
,),其自身的历史最好位置为pi=(p
i1
,p
i2
,
…
,p
id
,),整个粒子群的最好位置为: pg=(p
g1
,p
g2
,
…
,p
gd
,),粒子群在d维空间中不断地运动和改变方向来更新位置,其第k代种群中的位置和速度更新为:
[0042]
x
idk 1
=x
idk
v
idk 1
[0043]vidk
=ωv
idk-1
c1r1(p
idk-1-x
idk-1
) c2r2(p
gdk-1-x
gdk-1
)
[0044]
其中,ω∈[0,1]为惯性权重,表征对自身当前位置的信任度;c1、 c2为加速度系数,使粒子向组内最优个体进行学习,每次总结最后达到组内最优点;r1、r2是范围为[0,1]的随机实数,粒子xi为 (g
1i
,g
2i
,εi),g
1i
表示bigru网络第一个隐含层的神经元个数,g
2i
表示bigru网络第二个隐含层的神经元个数,εi表示bigru网络的学习率。
[0045]
bigru的表达式为:
[0046][0047]
式中:α
t
为时刻t信息前向传播gru单元隐层输出权重;β
t
为时刻t信息后向传播gru单元隐层输出权重;b
t
为对应的偏置量; g
ru
为门控循环单元,bigru结构如图3所示,其当前时刻的隐藏层状态h
t
由沿时间前向传播的时刻(t-1)隐藏层输出沿时间后向传播的时刻(t-1)隐藏层输出以及当前时刻输入x
t
3个部分共同决定,bigru在结构上可以看成是前向与后向传播gru的组合,时刻t的隐藏层输出为信息前向传播隐藏层输出和信息后向传播隐藏层输出线性叠加的结果,gru是lstm的一种变体,它在保持lstm 良好学习性能的同时,参数更少,收敛速度更快,gru模型内部由更新门和重置门构成,与lstm不同的是gru用更新门替代lstm的输入门和遗忘门,其中,更新门表示前一时刻隐藏层神经元输出信息对当前时刻隐藏层神经元的影响程度,当更新门值越大时,影响程度越大,重置门表示前一时刻隐藏层神经元输出的被忽略程度,当重置门的值越大时,忽略信息越少,gru具体结构如图2所示,pso算法是一种随机的、并行的优化算法。
[0048]
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。