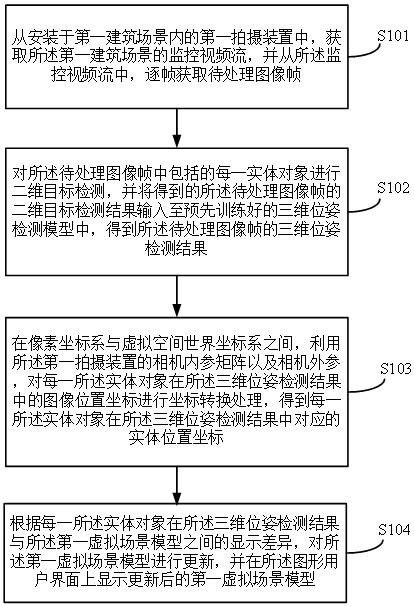
技术特征:
1.一种基于聚合相似度的深度哈希的不平衡商标检索方法,其特征在于,具体包括以下步骤:s1.构建基于聚合相似度的深度哈希神经网络的网络架构,并初始化所述神经网络参数;s2.通过哈达玛矩阵和bern随机采样的良好属性生成商标哈希簇心c={c1,c2,...,c
m
},其中,m为商标哈希簇心,即等于商标类的总数目,q表示哈希编码位数;s3.基于s2预设的商标哈希簇心c,构建商标语义哈希簇心c
′
={c1′
,c2′
,...,c
n
′
},n为商标训练集的总样本数目;s4.对于商标数据集训练集的训练样本x
i
,通过稀疏哈希编码模块获得训练集哈希编码集;s5.计算argminl
t
损失并执行反向传播以优化神经网络参数,直至模型收敛,生成基于聚合相似度的深度哈希神经网络。2.根据权利要求1所述的方法,其特征在于:所述神经网络的网络架构包括一个基于卷积神经网络的特征提取器、一个基于聚合相似度的哈希编码器和一个基于汉明距离匹配的分类器构成;所述特征提取器选用卷积神经网络架构alexnet作为骨干;所述卷积神经网络架构alexnet由7个权重层构成,包括5个卷积层和2个全连接层;第一、第二和第五个卷积层之后均使用三个最大池化层。3.根据权利要求2所述的方法,其特征在于:所述第一个卷积层有96个大小为11*11的滤波器,步长为4个像素,填充为2个像素;其他卷积层的步长和填充均被设置为1个像素;第二个卷积层有256个大小为5*5的滤波器;第三、第四和第五卷积层分别有384、384和256个大小为3*3的滤波器;所述特征提取器接收到数据进行处理产生高维特征,每一个全连接层学习一个非线性映射图z:其中,表示输入
×
在第l层的隐藏表征,w
l
和b
l
分别表示第l层的权重参数和偏置参数,a
l
表示激活函数单元;所有隐层层激活函数均选用relu单元:a
l
(x)=max(0,x)。4.根据权利要求2所述的方法,其特征在于:所述卷积神经网络的最后一层为包含k个隐藏单元的哈希层,所述哈希层通过函数其中,l表示总层数,当alexnet作为特征提取器时,l=8;表示哈希层的隐藏表征;所述哈希层利用双曲线正切tanh激活函数a
l
(x)=tanh(x),将其输出压缩到[-1,1]以内,使得哈希层的隐藏表征编码成二进制位码。5.根据权利要求1所述的方法,其特征在于:所述步骤s2更具体为:构建q
×
q哈达玛矩阵根据所述哈达玛矩阵构建商标哈希簇心,具体如公式(1)-(2)所示:(2)所示:
其中,当m≤q时,表示商标哈希中心c
i
;当q≤m≤2q,表示商标哈希中心c
i
。6.根据权利要求1所述的方法,其特征在于:所述步骤s4更具体为:将整体4096维的特征向量稀疏为4096/q段特征向量,其中q是二进制哈希码的维度,即征向量稀疏为4096/q段特征向量,其中q是二进制哈希码的维度,即接着由像素特征向量生成二进制哈希编码;商标哈希编码函数具体由公式(3)所示:其中,i=1,2,...,n;k=1,2,...,q;接着引入稀疏编码阈值函数,通过量化步骤降低映射误差;对于中间变量接着引入稀疏编码阈值函数,通过量化步骤降低映射误差;对于中间变量阈值函数如公式(4)所示:其中,δ是一个很小的正超参数。7.根据权利要求6所述的方法,其特征在于:所述步骤s5更具体为:s51.商标训练集的总样本数目为n,对于单标签商标数据,训练集中每一商标样本均一一对应其中的一个商标哈希簇心,对于每一训练样本x
i
对应映射的哈希簇心定义为商标语义哈希簇心c
i
′
,i=1,2,...,n;s52.给定商标哈希簇心c={c1,c2,...,c
m
}和训练样本x
i
,i=1,2,...,n,获得商标的语义簇心集合c
′
={c1′
,c2′
,...,c
n
′
};s53.根据商标的语义簇心集合c
′
和总样本商标哈希编码集合h获得c
′
和h之间的相似度损失l
c
;s54.根据所述相似度损失l
c
和l
q
获得商标哈希簇心的优化公式;其中,l
q
表示一个导数难以计算的非光滑函数,通过使用光滑函数进行替换,|x|≈log(cosh),l
q
计算如式(5)所示:8.根据权利要求7所述的方法,其特征在于:所述步骤s53具体为:由kl散度和朴素贝叶斯属性分析,通过求h关于c
′
的对数最大后验概率来量化以获得c
′
和h之间的相似度损失l
c
,具体如式(6)所示:其中,p(c
′
)为定值,上述公式放缩如下所示:其中,p(h)是先验分布,和p(c
′
|h)是似然函数;将p(c
′
|h)建模为gibbs分布:其中α和β为常数,dist
h
为哈希码与对应商标哈希语义簇
心之间的汉明距离。所述哈希码与对应商标哈希语义簇心之间的汉明距离由二进制交叉熵bce测量,即dist
h
(c
′
i
,h
i
)=bce(c
′
i
,h
i
),具体如式(8)所示:9.根据权利要求8所述的方法,其特征在于:所述c
′
和h之间的相似度损失l
c
中的p(c
′
i
|h
i
)取相反数,故相似度损失l
c
如式(9)所示:10.根据权利要求9所述的方法,其特征在于:所述步骤s54更具体为:根据所述相似度损失l
c
和l
q
,获得商标哈希中心的优化公式,具体如公式(10)所示:其中θ为深度散列函数学习的所有参数的集合,λ1为超参数。
技术总结
本发明公开一种基于聚合相似度的深度哈希的不平衡商标检索方法,步骤为:第一:构建神经网络的网络架构,并初始化神经网络参数;第二:通过哈达玛矩阵和Bern随机采样的良好属性生成商标哈希簇心;第三:基于商标哈希簇心,构建商标语义哈希簇心;第四:对于商标数据集训练集的训练样本,通过稀疏哈希编码模块获得训练集哈希编码集;第五:计算argminL
技术研发人员:林煜森 戴青云 雷方元 杨驭涵
受保护的技术使用者:广东技术师范大学
技术研发日:2021.12.07
技术公布日:2022/3/8
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。