1.本发明属于计算机视觉技术领域,尤其是视觉内容理解与分析领域,涉及一种基于目标空间语义对齐的视频描述方法。
背景技术:
2.在互联网 2.0时代,人、机、物均由网络和边缘设备紧密联系在一起,信息传递至关重要,视频作为占有量与日俱增的多媒体数据形态,包含着比文本图像更为丰富的视觉特征。准确理解视频内容成为诸如视频监控、自动驾驶、视障人群导航等各类实际应用的迫切需求,用人类易于理解的自然语言描述视频内容是视觉理解的重要研究方向,称之为视频描述。
3.视频描述任务是用一句或一段符合语法规范的自然语句对视频内容进行描述,从技术上颇具挑战性。其中关键的技术问题是如何利用视觉外观特征和运动特征,并刻画视频帧中不同目标空间关系及其与描述单词的映射关系,从而生成更符合真实视频内容的自然语句。
4.目前,主流的视频描述方法大部分采用编码器-解码器(encoder-decoder)框架。其中,编码器一般采用卷积神经网络(cnn:convolutional neural network)和卷积三维神经网络(c3d:convolutional 3d neural network)分别获取视频的外观特征和运动特征;解码器一般采用长短时记忆网络(lstm:long-short time memory)用于解码视频特征生成对应的描述语句。众所周知,视频数据中往往存在某些冗余片段,对于视频中的整体人物事件描述并无益处。现有基于卷积神经网络的编码器无法过滤此类冗余片段,难以实现对与人物事件直接关联片段的重点关注。而视觉理解领域广泛应用的注意力机制(attention)作为一种权重调整策略能用于实现对某些感兴趣视频片段的关注,因此可被用于构建视频描述模型;作为注意力的改进版本,转换器(transformer)的自注意力(self-attention)和多头注意力(multi-head attention)模块能有效捕获视频帧之间的时序关系,并将这种关系映射到描述语句中,有利于生成能准确描述事件内容及其时序先后关系的语句。
5.上述视频描述方法主要存在以下不足:(1)提取特征时只考虑视频的二维静态特征和三维动态特征,没有充分考虑视频中目标物体之间的关系,往往会导致对不同目标间关系进行描述的语句出现语义错乱,如将两个毫无关联的目标词语进行组合;(2)当利用注意力机制时,往往考虑单词与视频帧的对应关系,而忽略了单词与视频帧的目标物体的对应关系,导致生成语句出现目标物体无关的描述;(3)传统注意力机制的时间和空间复杂度过高,与视频帧数量成二次正比,难以用于实时性较高的实际任务中。基于以上考虑,迫切需要一种既能有效捕获视频帧目标关系又能降低时空复杂度的视频描述方法。
技术实现要素:
6.本发明的目的就是针对现有技术的不足,提出了一种基于目标空间语义对齐的视频描述方法,通过刻画目标边缘的邻接关系反映视频帧中不同目标的空间关系;并利用随
机注意力机制以线性时空复杂度实现单词-视频帧以及单词-视频目标之间的语义对齐,最终能快速生成自然流畅的视频描述语句。
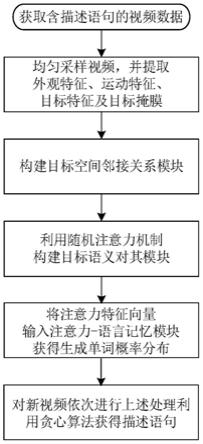
7.本发明方法获取含有描述语句的视频数据集合后,依次进行如下操作:
8.步骤(1).对视频均匀采样得到帧序列,利用二维和三维卷积网络,分别获取外观特征和运动特征向量,并通过掩膜区域卷积神经网络获取目标特征向量和目标掩膜集合;
9.步骤(2).构建目标空间邻接关系模块,输入为视频的目标掩膜集合,输出为目标邻接关系矩阵;
10.步骤(3).利用随机注意力机制构建目标语义对齐模块,实现单词候选集的单词-视频帧对齐和单词-视频目标对齐,输入为外观特征、运动特征以及目标特征向量和目标邻接关系矩阵,输出为注意力特征向量;
11.步骤(4).将注意力特征向量输入注意力-语言记忆模块,获得生成单词的概率分布,利用随机梯度下降算法优化视频描述模型直至收敛;
12.步骤(5).对新视频依次通过(1)~(4)得到生成语句的概率分布,利用贪心搜索算法得到相应的描述语句。
13.进一步,步骤(1)具体是:
14.(1-1).对视频均匀采样n个视频帧,获得帧序列集合其中三维张量xi为第i帧图像,表示实数域,c、h、w分别为图像的通道数、高度和宽度;视频描述语句对应的独热编码其中,l为描述语句长度,b
t
为描述语句的第t个单词在词汇表中的独热向量,n表示词汇表的单词个数;
15.(1-2).利用残差网络提取视频的外观特征向量集合其中表示第i帧的外观特征向量,a表示外观,u表示外观特征向量的通道维度大小;利用卷积三维网络提取视频的运动特征向量集合其中表示第i-1帧至第i 1帧提取的运动特征向量,m表示运动,表示运动特征的通道维度;
16.(1-3).将va中的外观特征向量以及vm中的运动特征向量依次沿通道维度进行拼接,得到视频特征向量集合其中vi表示为第i个视频帧特征向量,其通道维度大小
17.(1-4).对于视频帧xi,利用掩膜区域卷积神经网络进行目标检测,获取第i个视频帧中的目标特征向量集合和目标掩膜集合gi={g
i,j
|0≤j≤m,g
i,j
∈0,1h×w},o
i,j
表示第i个视频帧的第j个目标的特征向量,m表示设定的视频帧目标数量,r表示目标特征向量的维度大小,g
i,j
表示第i个视频帧的第j个目标的掩膜。
18.又进一步,步骤(2)具体是:
19.(2-1).目标空间邻接关系模块由目标对匹得分矩阵和目标对共边缘率矩阵组成,用于获取目标之间的空间关系;首先计算目标像素点的位置,具体是:输入目标掩膜集合gi
,获取目标像素点位置信息集合将第i个视频帧中的第j个目标的掩膜g
i,j
中任意元素为1的空间位置下标ι和μ作为目标像素点位置信息集合d
i,j
中的元素,定义相邻像素点为两个像素点之间的距离小于一个阈值即其中表示第i帧中第q个目标中的第ω个像素点与第i帧中第w个目标中的第σ个像素点之间的距离小于ψ,ψ为正实数,||
·
||2为l2范数;
20.(2-2).构建目标对匹得分矩阵,具体是:利用视频帧的目标像素点位置信息集合d
i,j
,计算目标对匹配数表示第i个视频帧中第q个目标和第w个目标在所有视频帧中匹配的次数,match表示匹配,其中d
i,q
表示第i个视频帧中第q个目标中所有像素点的位置信息,d
i,w
表示第i个视频帧中第w个目标中所有像素点的位置信息,匹配表示两个目标存在相邻像素点,表示当两个目标匹配时为1,否则为0;将目标对匹配数归一化处理,获得归一化目标对匹配得分
21.利用归一化目标对匹配得分构建目标对匹配得分矩阵集合:
22.其中,第i个视频帧的目标对匹得分矩阵其中归一化目标对匹配得分为目标对匹得分矩阵中第q行、第w列的元素,也即第i个视频帧中第q个目标和第w个目标在所有视频帧中的匹配次数的归一化得分;
23.(2-3).构建目标对共边缘率矩阵,具体是:利用视频帧的目标像素点位置信息集合d
i,j
计算第i帧中的第q个目标和第w个目标的共享边界长度所述的共享边界长度是指两个目标之间相邻像素点的个数,其中用于计算两个目标的共同边界长度;输入第i个视频帧中的第q个目标的掩膜g
i,q
,计算第i帧中的第q个目标的周长τ(
·
)用于计算目标的周长,周长是指一个目标边界像素点的个数;输入共享边界长度与目标周长计算目标对共边缘率即第i帧的第q个目标和第w个目标的共享边界长度除以在视频帧i中第q个目标的周长,edge表示边缘;对目标对共边缘率归一化处理,得到归一化目标对共边缘率得分
24.利用归一化目标对共边缘率得分构建目标对共边缘率矩阵集合:
25.其中,第i个视频帧的目标对共边缘率矩阵
26.归一化目标对匹配得分为目标对共边缘率矩阵中第q行、第w列的元素,表示第i个视频帧中第q个目标和第w个目标在所有视频帧中的共边缘率的归一化得分;
27.(2-4).利用目标对共边缘率矩阵集合与目标对匹配得分矩阵集合获取目标邻接关系矩阵集合其中,第i个视频帧的目标邻接关系矩阵目标邻接关系矩阵qi的元素为目标邻接关系得分e
i,q,w
。
28.再进一步,步骤(3)具体是:
29.(3-1).目标语义对齐模块由单词选择子模块、视频随机注意力子模块和目标随机注意力子模块组成,用于实现单词-视频帧和单词-视频目标的对齐;单词选择子模块,该模块由一个点积注意力层和一个线性层组成,用于选择重复度较小的单词;视频随机注意力子模块由一个随机注意力层和多个线性层组成,用于实现单词和视频帧之间的对齐;目标随机注意力子模块由一个加性注意力层、一个随机注意力层和多个线性层组成,用于实现单词与视频帧中目标的对齐;
30.(3-2).构建单词选择子模块,具体是:
31.①
首先输入生成的单词组集合t表示时间步的索引,第t时间步生成第t个单词,y
t
表示第t时间步生成单词的独热编码向量,表示生成描述语句长度,n表示词汇表单词的个数;将第t时间步之前生成的单词作为历史单词,对其进行词嵌入编码,得到历史单词嵌入矩阵表示对单词y
t
进行词嵌入编码,为可学习矩阵,l表示词向量的长度,t表示转置;
32.②
然后利用历史单词嵌入矩阵r
t
=[f1,f2,...,f
t-1
]
t
,使用点积注意力方法获取第t时间步的单词注意力矩阵softmax为归一化指数函数,a
p,t
为第t时间步第p个单词与所有单词对应的注意力权重向量;f
t
表示第t时间步的随机视频特征向量;
[0033]
③
使用余弦相似度计算单词和单词之间的相关程度:第t个时间步中第p个单词与其他单词的相关程度输出单词相似度集合{α
1,t
,...,α
p,t
,...,α
t-1,t
};
[0034]
④
将单词相似度集合{α
1,t
,...,α
p,t
,...,α
t-1,t
}按照数值大小升序排列,取出前λ
个元素的单词下标,并根据单词下标从历史单词嵌入矩阵r
t
中取出对应单词向量,加入单词候选集表示第t时间步加入候选集中的第个历史单词嵌入向量;
[0035]
(3-3).构建随机注意力子模块,具体是:
[0036]
①
首先输入第i帧视频特征向量vi,计算第i帧的随机视频特征向量fi:
[0037]
其中,为可学习参数向量,θ表示为可学习参数向量的数目,z表示正整数;
[0038]
②
然后利用第t时间步单词候选集p
t
的历史单词嵌入向量计算第t时间步第个历史单词的随机单词特征向量
[0039]
其中,为可学习参数向量;
[0040]
③
最后在第t时间步时,利用视频帧的随机视频特征向量fi,历史单词的随机单词特征向量和所有视频帧的视频特征向量集合v,使用随机注意力机制,计算得到第t时间步时第个历史单词的单词-视频帧对齐特征向量其中,表示外积,为可学习参数矩阵;
[0041]
(3-4).构建目标随机注意力子模块,具体是:
[0042]
①
首先输入第i个视频帧的视频特征向量vi和第t时间步的单词候选集p
t
中的历史单词嵌入向量使用加性注意力方法计算关系得分表示第t时间步时第个历史单词与第i个视频帧之间的关系得分,其中分别是可学习的参数矩阵,为可学习的参数向量,为可学习的参数矩阵的第一个维度;
[0043]
②
然后利用第i帧的目标邻接关系矩阵qi与目标特征向量集合oi,计算目标邻接关系特征向量其中c
i,q
表示第i个视频帧第q个目标的目标邻接关系特征向量,o
i,w
表式第i个视频帧中的第w个目标的目标特征向量,得到第i帧目标邻接关系特征向量集合
[0044]
③
利用第i帧中第q个目标的目标邻接关系特征向量c
i,q
,计算第i帧中第q个目标的随机目标邻接关系特征向量
[0045]
其中,为可学习参数向量;
[0046]
④
在第t时间步时,利用随机目标邻接关系特征向量历史单词的随机单词特征向量和第i帧的目标邻接关系特征向量集合ci,使用随机注意力机制计算得到第t时间步时第个历史单词与第i个视频帧的单词-视频帧目标对齐特征向量其中,为可学习参数矩阵;
[0047]
⑤
利用关系得分和单词-视频帧目标对齐特征向量计算得到第t时间步第个历史单词的单词-视频目标对齐特征向量
[0048]
(3-5).最后将单词-视频帧对齐特征向量单词-视频目标对齐特征向量和历史单词嵌入向量依次在通道上拼接,得到第个历史单词的注意力特征向量表示
[0049]
更进一步,步骤(4)具体是:
[0050]
(4-1).构造注意力-语言记忆模块,该模块由一个双层长短时记忆网络组成,用于获得生成单词的概率分布;首先获取注意力语言对齐向量,具体是:输入为第个历史单词的注意力特征向量将所有的历史单词的注意力特征相加得到注意力语义对齐向量
[0051]
(4-2).构造双层长短时记忆网络,具体是:将第t时间步的注意力语义对齐向量和第t-1时间步的时序注意力隐藏向量输入长短时记忆网络,输出为时序注意力特征γ表示注意力隐藏向量维度大小,attn表示注意力;
[0052]
将第t时间步的时序注意力特征第t-1时间步生成的历史单词嵌入向量f
t-1
和时序语言隐藏向量输入长短时记忆网络,输出为时序语言特征上标lang表示语言;
[0053]
(4-3).利用全连接层及softmax函数计算第t时间步预测单词的独热编码向量y
t
的概率分布向量其中表示全连接层权重矩阵,计算y
t
对应的历史单词嵌入向量并将其加入历史嵌入矩阵r
t
=[f1,
f2,...,f
t-1
]
t
得到
[0054]
(4-4).针对真实的文本描述语句b,历史单词嵌入矩阵r
t 1
,计算两者的交叉熵损失其中表示独热编码。
[0055]
还进一步,步骤(5)的具体是:
[0056]
(5-1).利用随机梯度下降法通过最小化交叉熵损失函数,优化视频描述模型直至收敛,其中视频描述模型包含目标语义对齐模块和注意力-语言记忆模块;
[0057]
(5-2).输入新视频均匀采样n个视频帧后得到首先依次经过步骤(1)~(4)得到第一个单词的概率分布向量分别表示第一个单词的概率分布向量,开始符的概率分布向量,通过贪心搜索算法从词汇表中将最大概率对应索引的单词作为第一个生成的单词b
′1;
[0058]
(5-3).重复步骤(3)~(4),最终获得描述语句{b
′1,b
′2,b
′3,...,b
′
l'
},其中b
′
t
为第t个单词,l
′
为生成语句长度。
[0059]
本发明提出了一种目标空间语义对齐的视频描述方法,该方法具有以下几个特点:1)将目标关系引入视频描述方法,提出利用目标对匹配数和目标对共边缘率表示不同目标空间邻接关系,2)在单词与视频帧对齐的基础上提出单词与目标之间的对齐,提高生成描述语句的准确性;3)通过随机注意力机制计算单词-视频帧和单词-视频目标之间的注意力权重,将二次复杂度降低为线性复杂度。
[0060]
本发明适用于目标关系复杂同时时序较长的视描述任务,有益效果包括:1)利用目标对匹配数和目标共边缘率获取目标空间邻接关系,增加生成描述语句对目标描述的准确性;2)利用语义对齐模块,实现单词-视频帧和单词-视频目标之间的对应,从而缩小生成语句与视频内容之间的语义差异;3)利用随机特征注意力方式,引入核函数思想,将现有注意力方法的复杂度和序列长度呈平方的关系,降低到呈线性关系,显著提高了模型运行效率。
附图说明
[0061]
图1是本发明方法的流程图。
具体实施方式
[0062]
以下结合附图对本发明作进一步说明。
[0063]
如图1,一种基于目标空间语义对齐的视频描述方法,首先对视频进行均匀采样,提取其视频特征向量、目标特征向量和掩膜集合;然后将视频掩膜集合输入目标空间邻接关系模块,该模块能获得目标邻接关系矩阵;利用目标邻接关系矩阵与目标特征向量共同构建目标邻接关系特征,同时利用单词选择模块得到单词候选集;将目标邻接关系特征向量、视频特征向量和候选单词集共同输入目标语义对齐模块,实现语义对齐;得到语义对齐向量后输入注意力-语言记忆模块,实现最终语句的生成。该方法可以不仅捕获目标空间关系,而且实现单词-视频帧和单词-视频目标之间的对齐,从而能生成准确的描述语句。具体是获取含有描述语句的视频数据集合后,进行如下操作:
[0064]
步骤(1).对视频均匀采样得到帧序列,利用二维和三维卷积网络,分别获取外观特征和运动特征向量,并通过掩膜区域卷积神经网络获取目标特征向量和目标掩膜集合;具体是:
[0065]
(1-1).对视频均匀采样n个视频帧,获得帧序列集合其中三维张量xi为第i帧图像,表示实数域,c、h、w分别为图像的通道数、高度和宽度;视频描述语句对应的独热(one-hot)编码其中,l为描述语句长度,b
t
为描述语句的第t个单词在词汇表中的独热向量,n表示词汇表的单词个数;
[0066]
(1-2).利用残差网络提取视频的外观特征向量集合其中表示第i帧的外观特征向量,a表示外观,u表示外观特征向量的通道维度大小;利用卷积三维网络(c3d)提取视频的运动特征向量集合其中表示第i-1帧至第i 1帧提取的运动特征向量,m表示运动,表示运动特征的通道维度;
[0067]
(1-3).将va中的外观特征向量以及vm中的运动特征向量依次沿通道维度进行拼接,得到视频特征向量集合其中vi表示为第i个视频帧特征向量,其通道维度大小
[0068]
(1-4).对于视频帧xi,利用掩膜区域卷积神经网络(mask r-cnn:mask region-based convolutional neural network)进行目标检测,获取第i个视频帧中的目标特征向量集合和目标掩膜集合o
i,j
表示第i个视频帧的第j个目标的特征向量,m表示设定的视频帧目标数量,r表示目标特征向量的维度大小,g
i,j
表示第i个视频帧的第j个目标的掩膜。
[0069]
步骤(2).构建目标空间邻接关系模块,输入为视频的目标掩膜集合,输出为目标邻接关系矩阵;具体是:
[0070]
(2-1).目标空间邻接关系模块由目标对匹得分矩阵和目标对共边缘率矩阵组成,用于获取目标之间的空间关系;先计算目标像素点的位置,具体是:输入目标掩膜集合gi,获取目标像素点位置信息集合将第i个视频帧中的第j个目标的掩膜g
i,j
中任意元素为1的空间位置下标ι和μ作为目标像素点位置信息集合d
i,j
中的元素,定义相邻像素点为两个像素点之间的距离小于一个阈值即其中表示第i帧中第q个目标中的第ω个像素点与第i帧中第w个目标中的第σ个像素点之间的距离小于ψ,ψ为正实数,
·
||2为l2范数;
[0071]
(2-2).构建目标对匹得分矩阵,具体是:利用视频帧的目标像素点位置信息集合d
i,j
,计算目标对匹配数表示第i个视频帧中第q个目标和第w个目标
在所有视频帧中匹配的次数,match表示匹配,其中d
i,q
表示第i个视频帧中第q个目标中所有像素点的位置信息,d
i,w
表示第i个视频帧中第w个目标中所有像素点的位置信息,匹配表示两个目标存在相邻像素点,表示当两个目标匹配时为1,否则为0;将目标对匹配数归一化处理,获得归一化目标对匹配得分
[0072]
利用归一化目标对匹配得分构建目标对匹配得分矩阵集合:
[0073]
其中,第i个视频帧的目标对匹得分矩阵其中归一化目标对匹配得分为目标对匹得分矩阵中第q行、第w列的元素,也即第i个视频帧中第q个目标和第w个目标在所有视频帧中的匹配次数的归一化得分;
[0074]
(2-3).构建目标对共边缘率矩阵,具体是:利用视频帧的目标像素点位置信息集合d
i,j
计算第i帧中的第q个目标和第w个目标的共享边界长度所述的共享边界长度是指两个目标之间相邻像素点的个数,其中用于计算两个目标的共同边界长度;输入第i个视频帧中的第q个目标的掩膜g
i,q
,计算第i帧中的第q个目标的周长τ(
·
)用于计算目标的周长,周长是指一个目标边界像素点的个数;输入共享边界长度与目标周长计算目标对共边缘率即第i帧的第q个目标和第w个目标的共享边界长度除以在视频帧i中第q个目标的周长,edge表示边缘;对目标对共边缘率归一化处理,得到归一化目标对共边缘率得分
[0075]
利用归一化目标对共边缘率得分构建目标对共边缘率矩阵集合:
[0076]
其中,第i个视频帧的目标对共边缘率矩阵归一化目标对匹配得分为目标对共边缘率矩阵中第q行、第w列的元素,表示第i个视频帧中第q个目标和第w个目标在所有视频帧中的共边缘率的归一化得分;
[0077]
(2-4).利用目标对共边缘率矩阵集合与目标对匹配得分矩阵集合获
取目标邻接关系矩阵集合其中,第i个视频帧的目标邻接关系矩阵目标邻接关系矩阵qi的元素为目标邻接关系得分e
i,q,w
。
[0078]
步骤(3).利用随机注意力机制构建目标语义对齐模块,实现单词候选集的单词-视频帧对齐和单词-视频目标对齐,输入为外观特征、运动特征以及目标特征向量和目标邻接关系矩阵,输出为注意力特征向量;具体是:
[0079]
(3-1).目标语义对齐模块由单词选择子模块、视频随机注意力子模块和目标随机注意力子模块组成,用于实现单词-视频帧和单词-视频目标的对齐;单词选择子模块,该模块由一个点积注意力层和一个线性层组成,用于选择重复度较小的单词;视频随机注意力子模块由一个随机注意力层和多个线性层组成,用于实现单词和视频帧之间的对齐;目标随机注意力子模块由一个加性注意力层、一个随机注意力层和多个线性层组成,用于实现单词与视频帧中目标的对齐;
[0080]
(3-2).构建单词选择子模块,具体是:
[0081]
①
首先输入生成的单词组集合t表示时间步的索引,第t时间步生成第t个单词,y
t
表示第t时间步生成单词的独热编码向量,表示生成描述语句长度,n表示词汇表单词的个数;将第t时间步之前生成的单词称为历史单词并将对其进行词嵌入编码得到历史单词嵌入矩阵表示对单词y
t
进行词嵌入编码,为可学习矩阵,l表示词向量的长度,t表示转置;
[0082]
②
然后利用历史单词嵌入矩阵r
t
=[f1,f2,...,f
t-1
]
t
,使用点积注意力方法获取第t时间步的单词注意力矩阵softmax为归一化指数函数,a
p,t
为第t时间步第p个单词与所有单词对应的注意力权重向量;f
t
表示第t时间步的随机视频特征向量;
[0083]
③
使用余弦相似度计算单词和单词之间的相关程度:第t个时间步中第p个单词与其他单词的相关程度输出单词相似度集合{α
1,t
,...,α
p,t
,...,α
t-1,t
};
[0084]
④
为减少历史单词重复,将单词相似度集合{α
1,t
,...,α
p,t
,...,α
t-1,t
}按照数值大小升序排列,取出前λ个元素的单词下标,并根据单词下标从历史单词嵌入矩阵r
t
中取出对应单词向量,加入单词候选集表示第t时间步加入候选集中的第个历史单词嵌入向量;
[0085]
(3-3).构建随机注意力子模块,具体是:
[0086]
①
首先输入第i帧视频特征向量vi,计算第i帧的随机视频特征向量fi:
[0087]
其中,
为可学习参数向量,θ表示为可学习参数向量的数目,z表示正整数;
[0088]
②
然后利用第t时间步单词候选集p
t
的历史单词嵌入向量计算第t时间步第个历史单词的随机单词特征向量
[0089]
其中,为可学习参数向量;
[0090]
③
最后在第t时间步时,利用视频帧的随机视频特征向量fi,历史单词的随机单词特征向量和所有视频帧的视频特征向量集合v,使用随机注意力机制,计算得到第t时间步时第个历史单词的单词-视频帧对齐特征向量其中,表示外积,为可学习参数矩阵;
[0091]
(3-4).构建目标随机注意力子模块,具体是:
[0092]
①
首先输入第i个视频帧的视频特征向量vi和第t时间步的单词候选集p
t
中的历史单词嵌入向量使用加性注意力方法计算关系得分表示第t时间步时第个历史单词与第i个视频帧之间的关系得分,其中分别是可学习的参数矩阵,为可学习的参数向量,为可学习的参数矩阵的第一个维度;
[0093]
②
然后利用第i帧的目标邻接关系矩阵qi与目标特征向量集合oi,计算目标邻接关系特征向量其中c
i,q
表示第i个视频帧第q个目标的目标邻接关系特征向量,o
i,w
表式第i个视频帧中的第w个目标的目标特征向量,得到第i帧目标邻接关系特征向量集合
[0094]
③
利用第i帧中第q个目标的目标邻接关系特征向量c
i,q
,计算第i帧中第q个目标的随机目标邻接关系特征向量
[0095]
其中,为可学习参数向量;
[0096]
④
在第t时间步时,利用随机目标邻接关系特征向量历史单词的随机单词特征向量和第i帧的目标邻接关系特征向量集合ci,使用随机注意力机制计算得到第t时间步时第个历史单词与第i个视频帧的单词-视频帧目标对齐特征向量
其中,为可学习参数矩阵;
[0097]
⑤
利用关系得分和单词-视频帧目标对齐特征向量计算得到第t时间步第个历史单词的单词-视频目标对齐特征向量
[0098]
(3-5).最后将单词-视频帧对齐特征向量单词-视频目标对齐特征向量和历史单词嵌入向量依次在通道上拼接,得到第个历史单词的注意力特征向量表示
[0099]
步骤(4).将注意力特征向量输入注意力-语言记忆模块,获得生成单词的概率分布,利用随机梯度下降算法优化视频描述模型直至收敛;具体是:
[0100]
(4-1).构造注意力-语言记忆模块,该模块由一个双层长短时记忆网络组成,用于获得生成单词的概率分布;首先获取注意力语言对齐向量,具体是:输入为第个历史单词的注意力特征向量将所有的历史单词的注意力特征相加得到注意力语义对齐向量
[0101]
(4-2).构造双层长短时记忆网络,具体是:将第t时间步的注意力语义对齐向量和第t-1时间步的时序注意力隐藏向量输入长短时记忆网络(lstm:long-short term memory),输出为时序注意力特征γ表示注意力隐藏向量维度大小,attn表示注意力;
[0102]
再将第t时间步的时序注意力特征第t-1时间步生成的历史单词嵌入向量f
t-1
和时序语言隐藏向量输入长短时记忆网络,输出为时序语言特征上标lang表示语言;
[0103]
(4-3).利用全连接层及softmax函数计算第t时间步预测单词的独热编码向量y
t
的概率分布向量其中表示全连接层权重矩阵,计算y
t
对应的历史单词嵌入向量并将其加入历史嵌入矩阵r
t
=[f1,f2,...,f
t-1
]
t
得到
[0104]
(4-4).针对真实的文本描述语句b,历史单词嵌入矩阵r
t 1
,计算两者的交叉熵损失其中表示独热编码。
[0105]
步骤(5).对新视频依次通过(1)~(4)得到生成语句的概率分布,利用贪心搜索算
法得到相应的描述语句;具体是:
[0106]
(5-1).利用随机梯度下降法通过最小化交叉熵损失函数,优化视频描述模型直至收敛,其中视频描述模型包含目标语义对齐模块和注意力-语言记忆模块;
[0107]
(5-2).输入新视频均匀采样n个视频帧后得到首先依次经过步骤(1)~(4)得到第一个单词的概率分布向量分别表示第一个单词的概率分布向量,开始符的概率分布向量,通过贪心搜索算法从词汇表中将最大概率对应索引的单词作为第一个生成的单词b
′1;
[0108]
(5-3).重复步骤(3)~(4),最终获得描述语句{b
′1,b
′2,b
′3,...,b
′
l'
},其中b
′
t
为第t个单词,l
′
为生成语句长度。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。