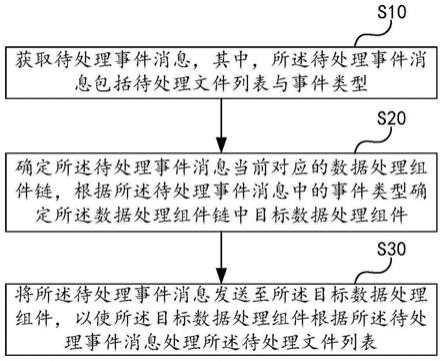
一种基于paddledetection的混淆矩阵生成方法
技术领域
1.本发明涉及深度学习目标检测领域,特别是指一种基于paddledetection的混淆矩阵生成方法。
背景技术:
2.飞桨(paddlepaddle)是集深度学习核心框架、工具组件和服务平台为一体的百度自主研发的开源深度学习平台。paddledetection是飞桨深度学习平台下的优秀的目标检测开发套件,提供多种主流目标检测、实例分割、关键点检测算法,并且将各个网络组件进行模块化、提供数据增强策略、损失函数策略等,模型的压缩和跨平台的的高性能部署能够帮助工业项目更好的完成落地。
3.对于目标检测而言,检测识别的准确率很大程度上取决于模型本身的识别精度,因此前期在对神经网络识别模型进行训练的时候需要找到一个合适的适合实际生产的评价指标。在paddledetection套件中评价神经网络模型评价指标是通过map来进行评价,不能反应实际分拣中的各个类别的识别精度。
4.混淆矩阵(confusion matrix)也称误差矩阵,用n行n列的矩阵来表示。在人工智能图像分类精度的评价中,主要用于比较分类结果和实际测得的值。混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目.如图1所示,第一行第一列中的96表示有96个实际归属第一类的实例被预测为第一类,同理,第一行第二列的2表示有2个实际归属为第一类的实例被错误预测为第二类,依次类推。
技术实现要素:
5.本发明的主要目的在于克服现有技术中的上述缺陷,提出一种基于paddledetection的混淆矩阵生成方法,能通过目标检测网络预测的检测框与实际的目标检测框进行匹配,将匹配的实际结果记录下来,绘制在混淆矩阵上,以便对于模型各个种类的识别结果进行统计研究,优化网络模型的训练方法。
6.本发明采用如下技术方案:
7.步骤一,在paddlepaddle平台下运用paddledetection目标检测开发套件训练一个目标检测网络。
8.步骤二,准备一批新的有标注的测试数据集,分为两个文件夹,一个文件夹放json文件,另一个放对应的图片文件。运用opencv的rect函数对json文件下的轮廓标签进行处理可以得到真实的目标物体外接矩形框;
9.步骤三,运用paddledetection开发套件下的infer.py对步骤二中的图片文件进行预测,得到预测标签;
10.步骤四,以图片文件的数量i来循环遍历,利用模型对每张图片进行预测,得到图
片中每个物体的检测框,对物体的检测框进行iou判断,对于同类且iou大于阈值的检测框删除其他的框,仅保留置信度得分最高的检测框、对于不同类的且iou大于阈值的,只保留一个检测框,其他的删除,并把相应的标签改为others,由此便可以得到预测修正后的矩形检测框;
11.步骤五,将步骤二得出的真实的目标物体外接矩形框与步骤四预测修正得到的矩形检测框进行循环匹配,将统计得到的值记录在矩阵上;
12.步骤六,创建excle表格,将步骤五得出的矩阵填充到表格中,绘制出用于评价模型实际应用效果的混淆矩阵。
13.由上述对本发明的描述可知,与现有技术相比,本发明具有如下有益效果:
14.(1)本发明提出一种基于paddledetection的混淆矩阵生成方法,能通过目标检测网络预测的检测框与实际的目标检测框进行匹配,将匹配的实际结果记录下来,绘制在混淆矩阵上,以便对于模型各个种类的识别结果进行统计研究,优化网络模型的训练方法。
附图说明
15.图1为混淆矩阵的示例图;
16.图2为本发明实施例中iou的计算方法;
17.图3为本发明实施例中删除目标检测预测的重叠框的示意图;
18.图4为本发明实施例中匹配预测框与真实框的程序流程示意图;
19.图5为本发明实施例得出的混淆矩阵示意图。
20.以下结合附图和具体实施例对本发明作进一步详述。
具体实施方式
21.本发明提出一种基于paddledetection的混淆矩阵生成方法,用于评价神经网络模型对实际目标检测的识别效果,所述神经网络为包括mask-rcnn在内的目标检测网络;本发明提供的方法能通过目标检测网络预测的检测框与实际的目标检测框进行匹配,将匹配的实际结果记录下来,绘制在混淆矩阵上,以便我们对于模型各个种类的识别结果进行统计研究,优化网络模型的训练方法。
22.本发明具体实施例以生活垃圾后端分选的实际工况为例。采集的图片数据为生活垃圾低值可回收物在传送带上的图片,运用labelme对图片数据进行标注,将图片中的目标物体分为十个类别,包括trans_hdpe、color_hdpe、white_hdpe、trans_pp、white_pp、black_pp、color_pp、trans_pet、bottle_pet、others。
23.参照图2、图3、图4、图5具体步骤如下:
24.步骤一,采集并标注生活垃圾低值可回收物数据集12000张,80%划为训练集和20%验证集。使用gpu进行训练,计算机配置为windows10,intel(r)i5-10400f cpu,nvidia geforce gtx3090显卡,24g显存,平台为paddlepaddle。使用paddledetection 2.0版本开发套件静态版本中的mask_rcnn神经网络模型,训练的初始学习率为0.00125,最大迭代步数max_iters为48000步,训练得到目标检测网络模型;
25.步骤二,准备一批新的有标注的测试数据集,分为两个文件夹,一个文件夹放json文件,另一个放对应的图片文件;json文件为通过labelme标注生成的json文件,里面记录
每个目标物体的种类及位置信息等。运用opencv的rect函数对json文件下的轮廓标签进行处理可以得到真实的目标物体外接矩形框。
26.步骤三,以步骤二中图片文件的数量i来循环遍历,利用步骤一训练得到的目标检测模型导出并在paddledetection2.0开发套件下执行infer.py对步骤二中的每张图片进行预测,将会得到np_boxes的列表,每一个np_boxes包含图片中每个物体的矩形检测框、类别、置信度。
27.步骤四,由于工况复杂的情况下,神经网络模型预测存在复选框和重叠框,会对最终检测精度的统计造成影响,因此需要对预测框进行修正。预测框位置可能与实际框存在微小的差别,经过实验统计预测框与实际框的iou值大于0.7即认为两个框试重合的,因此设iou阈值为0.7。
28.图片中每个目标物体的预测结果由步骤三得出,每个目标物体经过步骤三的预测都会得出一个或多个np_boxes,每一个np_boxes包含图片中每个物体的矩形检测框、类别、置信度。图片中的每个目标物体的实际结果由步骤二得出,每张图片目标物体的真实标签存放在对应的json文件中,运用标签中目标物体的点坐标可以得出目标物体的最小外接矩形框。
29.对于同一个物体如果预测结果有多个np_boxes(每一个np_boxes包含图片中每个物体的矩形检测框、类别、置信度),比较预测的每个np_boxes。对于同一个物体预测的每一个np_boxes都是同类的情况,保留iou(iou的计算方法如图2所示)大于阈值且置信度得分最高的np_boxes,删除其他的np_boxes;对于同一个物体预测的np_boxes属于不同类的情况,保留iou大于阈值且置信度得分最高的np_boxes并把相应的类别标签改为others,删除其它的np_boxes,单个物体的预测标签修正如图3所示,由此便可以得到预测修正后的矩形检测框。
30.步骤五,用步骤二得到的真实标签与步骤四修正的预测标签进行比对,匹配流程图如图4所示。程序的最外层循环以需要预测的图片数量来遍历,接着第二层循环以每张图片中的预测标签数量来循环,第三层循环以每张图片的实际标签数量来循环,通过每个物体的实际标签与预测标签进行iou判断,当iou大于阈值0.7即认为匹配到位,在矩阵的对应位置上计数。如果实际标签没有匹配到预测标签即认为是漏识别的也在矩阵对应的位置上进行统计。
31.步骤六,创建excle表格将记录的矩阵填充到表格中,绘制出混淆矩阵,纵向为实际类别,横向为预测类别,如图5所示。图5所示神经网络模型为11分类(包括背景),以第一行为例,实际中有64个color_pp被正确识别成color_pp,有10个被错误识别成black_pp,以此类推。
32.本发明提出一种基于paddledetection的混淆矩阵生成方法,能通过目标检测网络预测的检测框与实际的目标检测框进行匹配,将匹配的实际结果记录下来,绘制在混淆矩阵上,以便对于模型各个种类的识别结果进行统计研究,优化网络模型的训练方法。
33.上述仅为本发明的具体实施方式,但本发明的设计构思并不局限于此,凡利用此构思对本发明进行非实质性的改动,均应属于侵犯本发明保护范围的行为。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。