应用于transformer神经网络的层归一化处理硬件加速器及方法
技术领域
1.本技术涉及神经网络技术领域,尤其涉及应用于transformer神经网络的层归一化处理硬件加速器及方法。
背景技术:
2.transformer网络是一个用于解决自然语言处理问题的神经网络模型,其模型架构如图1所示,主要包括一个编码器堆栈和一个解码器堆栈,编码器堆栈和解码器堆栈又各自包含n个编码器层和多个解码器层。transformer神经网络计算过程中,输入序列首先经过词向量嵌入层处理及位置编码叠加处理后,得到输入矩阵,该输入矩阵输至编码器堆栈中,依次经历多个编码器层的运算,得到编码器堆栈的输出矩阵。编码阶段结束后就是解码阶段,解码阶段中每一步会输出目标句子的一个元素,实现自然语言的处理。
3.每个编码器层和解码器层均由多头注意力层和前馈层组成。多头注意力层包括大小一致的三个输入矩阵,分别为第一输入矩阵、第二输入矩阵及第三输入矩阵,前馈层仅包括一个输入矩阵。在多头注意力层中,三个输入矩阵经过一系列处理(包括线性处理和softmax层的处理)之后,得到第一中间矩阵,然后针对该中间矩阵进行层归一化处理,得到多头注意力层最终的输出矩阵。同样的,在前馈层中,输入矩阵经过一系列处理得到第二中间矩阵,然后针对该中间矩阵进行层归一化处理,得到前馈层的输出矩阵。
4.目前,都是在cpu或gpu这样通用的计算平台上运行上述计算流程。在执行层归一化处理的过程中,为了得到中间矩阵每行元素的方差值,需先计算中间矩阵中每行元素的平均值,再分别获取每个元素与平均值之间的差值,针对差值进行平方后执行累加操作,这样的处理步骤较为繁琐,存在较大延时。为了提高transformer神经网络的运算速度和效率,亟需设计出专用于层归一化处理的硬件加速器。
技术实现要素:
5.为了减少层归一化处理过程的延时,提高transformer神经网络的运算速度和效率,本技术通过以下实施例公开了应用于transformer神经网络的层归一化处理硬件加速器及方法。
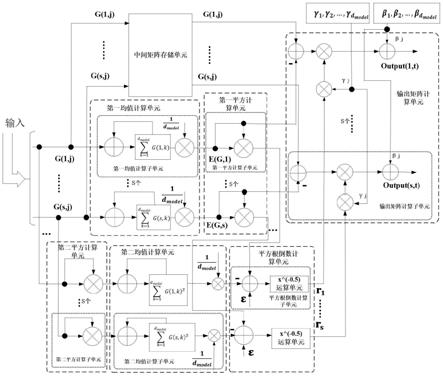
6.本技术第一方面公开了一种应用于transformer神经网络的层归一化处理硬件加速器,所述层归一化处理硬件加速器包括:
7.中间矩阵存储单元、第一均值计算单元、第二均值计算单元、第一平方计算单元、第二平方计算单元、平方根倒数计算单元及输出矩阵计算单元;
8.所述中间矩阵存储单元的输出端接至所述输出矩阵计算单元;
9.所述第一均值计算单元的输出端分别接至所述第一平方计算单元及所述输出矩阵计算单元;所述第一平方计算单元的输出端接至所述平方根倒数计算单元;
10.所述第二平方计算单元的输出端接至所述第二均值计算单元;
11.所述第二均值计算单元的输出端接至所述平方根倒数计算单元;
12.所述平方根倒数计算单元的输出端接至所述输出矩阵计算单元。
13.可选的,所述中间矩阵存储单元用于获取并存储所述中间矩阵,所述中间矩阵为多头注意力层处理过程中的第一中间矩阵或前馈层处理过程中的第二中间矩阵;
14.所述第一均值计算单元用于计算所述中间矩阵中每行元素的均值,并将计算结果输入至所述第一平方计算单元;
15.所述第一平方计算单元用于对所述第一均值计算单元输入的值执行平方运算,获取所述中间矩阵中每行元素均值的平方;
16.所述第二平方计算单元用于针对所述中间矩阵中的每个元素执行平方运算,获取平方矩阵;
17.所述第二均值计算单元用于计算所述平方矩阵每行元素的均值;
18.所述平方根倒数计算单元用于根据所述中间矩阵每行元素均值的平方及所述平方矩阵每行元素的均值,获取所述中间矩阵每行元素方差的平方根倒数;
19.所述输出矩阵计算单元用于对所述中间矩阵的每个元素、所述中间矩阵每行元素的均值及所述中间矩阵每行元素方差的平方根倒数进行层归一化处理,获得所述多头注意力层或所述前馈层最终的输出矩阵。
20.可选的,所述平方根倒数计算单元在根据所述中间矩阵每行元素均值的平方及所述平方矩阵每行元素的均值,获取所述中间矩阵每行元素方差的平方根倒数的过程中,用于根据以下公式,获取所述中间矩阵每行元素的方差:
21.var(g,i)=e(g,i)
2-f(i,k);
[0022][0023]
其中,var(g,i)表示所述中间矩阵g第i行元素的方差,e(g,i)表示所述中间矩阵g第i行元素的均值,f(i,k)表示所述平方矩阵第i行元素的均值,g(i,k)表示所述中间矩阵第i行第k列的元素,d
model
表示所述中间矩阵的总列数。
[0024]
可选的,所述输出矩阵计算单元用于根据以下公式,对所述中间矩阵的每个元素、所述中间矩阵每行元素的均值及所述中间矩阵每行元素方差的平方根倒数进行层归一化处理,获取所述多头注意力层或所述前馈层最终的输出矩阵:
[0025][0026]
其中,output(i,j)表示所述输出矩阵中第i行第j列的元素,var(g,i)表示所述中间矩阵g第i行元素的方差,g(i,j)表示所述中间矩阵g第i行第j列的元素,e(g,i)表示所述中间矩阵第i行元素的均值,ε为第一参数,γj表示第二参数,βj表示第三参数。
[0027]
可选的,所述第一均值计算单元包括多个第一均值计算子单元,所述第二均值计算单元包括多个第二均值计算子单元,所述第一平方计算单元包括多个第一平方计算子单元,所述第二平方计算单元包括多个第二平方计算子单元,所述平方根倒数计算单元包括多个平方根倒数计算子单元,所述输出矩阵计算单元包括多个输出矩阵计算子单元;
[0028]
所述第一均值计算子单元、所述第二均值计算子单元、所述第一平方计算子单元、
所述第二平方计算子单元、所述平方根倒数计算子单元及所述输出矩阵计算子单元的数量均与所述多头注意力层中任一输入矩阵的行数一致。
[0029]
本技术第二方面公开了一种应用于transformer神经网络的层归一化处理方法,所述层归一化处理方法应用于本技术第一方面所述的应用于transformer神经网络的层归一化处理硬件加速器,所述层归一化处理方法包括:
[0030]
将中间矩阵的所有元素按照列序依次输入至中间矩阵存储单元中,其中,若当前运算属于多头注意力层,则所述中间矩阵为第一中间矩阵,若当前运算为前馈层,则所述中间矩阵为第二中间矩阵;
[0031]
将中间矩阵的每行元素分别输入至多个第一均值计算子单元中,计算出所述中间矩阵中每行元素的均值;以及将中间矩阵的每行元素分别输入至多个第二平方计算子单元中,获取平方矩阵;
[0032]
将所述中间矩阵中每行元素的均值分别输入至多个第一平方计算子单元中,获取所述中间矩阵中每行元素均值的平方;
[0033]
将所述平方矩阵中每行元素分别输入至多个第二均值计算子单元中,计算出所述平方矩阵中每行元素的均值;
[0034]
将所述中间矩阵中每行元素均值的平方及所述平方矩阵中每行元素的均值分别输入至多个平方根倒数计算子单元中,获得所述中间矩阵每行元素方差的平方根倒数;
[0035]
分别将所述中间矩阵的每个元素、所述中间矩阵每行元素的均值及所述中间矩阵每行元素方差的平方根倒数分别输入至多个输出矩阵计算子单元中,获得所述多头注意力层或所述前馈层最终的输出矩阵。
[0036]
本技术第三方面公开了一种计算机设备,包括:
[0037]
存储器,用于存储计算机程序;
[0038]
处理器,用于执行所述计算机程序时实现如本技术第二方面所述的应用于transformer神经网络的层归一化处理方法的步骤。
[0039]
本技术第四方面公开了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理执行时实现如本技术第二方面所述的应用于transformer神经网络的层归一化处理方法的步骤。
[0040]
本技术公开了应用于transformer神经网络的层归一化处理硬件加速器及方法,该硬件加速器包括中间矩阵存储单元、第一均值计算单元、第二均值计算单元、第一平方计算单元、第二平方计算单元、平方根倒数计算单元及输出矩阵计算单元。中间矩阵存储单元、第一均值计算单元及平方根倒数计算单元的输出端均接至输出矩阵计算单元,第一均值计算单元的输出端接至第一平方计算单元。第一平方计算单元的输出端接至平方根倒数计算单元。第二平方计算单元的输出端接至第二均值计算单元。第二均值计算单元的输出端接至平方根倒数计算单元。通过上述硬件加速器执行层归一化处理,能够有效减小延时,提高transformer神经网络的运算速度和效率。
附图说明
[0041]
为了更清楚地说明本技术的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还
可以根据这些附图获得其他的附图。
[0042]
图1为transformer神经网络的模型架构示意图;
[0043]
图2为本技术实施例公开的应用于transformer神经网络的层归一化处理硬件加速器的硬件架构示意图;
[0044]
图3为本技术实施例公开的应用于transformer神经网络的层归一化处理方法的工作流程示意图。
具体实施方式
[0045]
为了减少层归一化处理过程的延时,提高transformer神经网络的运算速度和效率,本技术通过以下实施例公开了应用于transformer神经网络的层归一化处理硬件加速器及方法。
[0046]
本技术中,将多头注意力层的三个输入分别定义为q、k、v,将前馈层的输入定义为x,输入张量x的尺寸和输入张量q、k、v的尺寸是相同的,它们均等于[batch_size,s,dmodel](batch_size表示一次有多少个输入序列,s代表一个输入序列中有多少个词,dmodel的大小代表了神经网络模型的尺寸)。考虑batch_size为1的情形,输入张量可以认为退化为了矩阵,那么全部的运算都可以认为是对输入矩阵的操作(batch_size即使大于1,也可以认为是多个尺寸相同,元素不同的输入矩阵,对它们进行了相同且互不干扰的操作最后再合并到一起)。
[0047]
本技术第一实施例公开了一种应用于transformer神经网络的层归一化处理硬件加速器,参见图2所示的结构示意图,所述层归一化处理硬件加速器包括:
[0048]
中间矩阵存储单元、第一均值计算单元、第二均值计算单元、第一平方计算单元、第二平方计算单元、平方根倒数计算单元及输出矩阵计算单元。
[0049]
所述中间矩阵存储单元的输出端接至所述输出矩阵计算单元。
[0050]
所述第一均值计算单元的输出端分别接至所述第一平方计算单元及所述输出矩阵计算单元。
[0051]
所述第一平方计算单元的输出端接至所述平方根倒数计算单元。
[0052]
所述第二平方计算单元的输出端接至所述第二均值计算单元。
[0053]
所述第二均值计算单元的输出端接至所述平方根倒数计算单元。
[0054]
所述平方根倒数计算单元的输出端接至所述输出矩阵计算单元。
[0055]
进一步的,所述中间矩阵存储单元用于获取并存储所述中间矩阵,所述中间矩阵为多头注意力层处理过程中的第一中间矩阵或前馈层处理过程中的第二中间矩阵。
[0056]
所述第一均值计算单元用于计算所述中间矩阵中每行元素的均值,并将计算结果输入至所述第一平方计算单元。
[0057]
所述第一平方计算单元用于对所述第一均值计算单元输入的值执行平方运算,获取所述中间矩阵中每行元素均值的平方。
[0058]
所述第二平方计算单元用于针对所述中间矩阵中的每个元素执行平方运算,获取平方矩阵。
[0059]
所述第二均值计算单元用于计算所述平方矩阵每行元素的均值。
[0060]
所述平方根倒数计算单元用于根据所述中间矩阵每行元素均值的平方及所述平
方矩阵每行元素的均值,获取所述中间矩阵每行元素方差的平方根倒数。
[0061]
所述输出矩阵计算单元用于对所述中间矩阵的每个元素、所述中间矩阵每行元素的均值及所述中间矩阵每行元素方差的平方根倒数进行层归一化处理,获得所述多头注意力层或所述前馈层最终的输出矩阵。
[0062]
进一步的,所述第一均值计算单元包括多个第一均值计算子单元,所述第二均值计算单元包括多个第二均值计算子单元,所述第一平方计算单元包括多个第一平方计算子单元,所述第二平方计算单元包括多个第二平方计算子单元,所述平方根倒数计算单元包括多个平方根倒数计算子单元,所述输出矩阵计算单元包括多个输出矩阵计算子单元。
[0063]
所述第一均值计算子单元、所述第二均值计算子单元、所述第一平方计算子单元、所述第二平方计算子单元、所述平方根倒数计算子单元及所述输出矩阵计算子单元的数量均与所述多头注意力层中任一输入矩阵的行数一致。
[0064]
本技术实施例中,层归一化函数运算模块的输入是大小为s
×
dmodel的中间矩阵g,输出也是同样大小的矩阵(命名为output)。
[0065]
目前,通常采用以下公式计算中间矩阵第i行元素的均值:
[0066][0067]
通常采用以下公式计算中间矩阵第i行元素的方差:
[0068][0069]
通过上述公式执行层归一化处理的过程中,为了得到中间矩阵每行元素的方差值,需先计算中间矩阵中每行元素的平均值,再分别获取每个元素与平均值之间的差值,针对差值进行平方后再执行累加操作,这样的计算过程步骤较为繁琐,实际处理过程中,会产生较大的延时,增加了transformer神经网络的运算时间,降低了transformer神经网络的运算效率。
[0070]
本技术实施例中,为了减小延时,提出一种优化方法,使用另一种方法来计算中间矩阵第i行元素的方差,计算公式如下:
[0071][0072]
基于上述优化方法,所述平方根倒数计算单元在根据所述中间矩阵每行元素均值的平方及所述平方矩阵每行元素的均值,获取所述中间矩阵每行元素方差的平方根倒数的过程中,用于根据以下公式,获取所述中间矩阵每行元素的方差:
[0073]
var(g,i)=e(g,i)
2-f(i,k)。
[0074][0075]
其中,var(g,i)表示所述中间矩阵g第i行元素的方差,e(g,i)表示所述中间矩阵g第i行元素的均值,f(i,k)表示所述平方矩阵第i行元素的均值,g(i,k)表示所述中间矩阵第i行第k列的元素,d
model
表示所述中间矩阵的总列数。
[0076]
进一步的,所述输出矩阵计算单元用于根据以下公式,对所述中间矩阵的每个元素、所述中间矩阵每行元素的均值及所述中间矩阵每行元素方差的平方根倒数进行层归一化处理,获取所述多头注意力层或所述前馈层最终的输出矩阵:
[0077][0078]
其中,output(i,j)表示所述输出矩阵中第i行第j列的元素,var(g,i)表示所述中间矩阵g第i行元素的方差,g(i,j)表示所述中间矩阵g第i行第j列的元素,e(g,i)表示所述中间矩阵第i行元素的均值,ε为第一参数,γj表示第二参数,βj表示第三参数。ε用于防止分母等于零从而使得运算结果变成无穷大,其取值为10-8
。第二参数包括d
model
个(γ1、γ2、
…
、γj、
…
、γ
dmodel
),分别用于计算输出矩阵不同列的元素,第三参数包括d
model
个(β1、β2、
…
、βj、
…
、β
dmodel
),分别用于计算输出矩阵不同列的元素,第二参数及第三参数均为预设的值。
[0079]
上述实施例公开的应用于transformer神经网络的层归一化处理硬件加速器,包括中间矩阵存储单元、第一均值计算单元、第二均值计算单元、第一平方计算单元、第二平方计算单元、平方根倒数计算单元及输出矩阵计算单元。通过该硬件加速器执行层归一化处理,能够有效减小延时,提高transformer神经网络的运算速度和效率
[0080]
本技术第二实施例公开了一种应用于transformer神经网络的层归一化处理方法,所述层归一化处理方法应用于本技术第一实施例所述的应用于transformer神经网络的层归一化处理硬件加速器,参见图3所示的工作流程示意图,所述层归一化处理方法包括:
[0081]
步骤s11,将中间矩阵的所有元素按照列序依次输入至中间矩阵存储单元中,其中,若当前运算属于多头注意力层,则所述中间矩阵为第一中间矩阵,若当前运算为前馈层,则所述中间矩阵为第二中间矩阵。
[0082]
步骤s12,将中间矩阵的每行元素分别输入至多个第一均值计算子单元中,计算出所述中间矩阵中每行元素的均值,以及将中间矩阵的每行元素分别输入至多个第二平方计算子单元中,获取平方矩阵。
[0083]
步骤s13,将所述中间矩阵中每行元素的均值分别输入至多个第一平方计算子单元中,获取所述中间矩阵中每行元素均值的平方。
[0084]
步骤s14,将所述平方矩阵中每行元素分别输入至多个第二均值计算子单元中,计算出所述平方矩阵中每行元素的均值。
[0085]
步骤s15,将所述中间矩阵中每行元素均值的平方及所述平方矩阵中每行元素的均值分别输入至多个平方根倒数计算子单元中,获得所述中间矩阵每行元素方差的平方根倒数。
[0086]
步骤s16,分别将所述中间矩阵的每个元素、所述中间矩阵每行元素的均值及所述中间矩阵每行元素方差的平方根倒数分别输入至多个输出矩阵计算子单元中,获得所述多头注意力层或所述前馈层最终的输出矩阵。
[0087]
在一种实现方式中,结合图2公开的结构图,上述实施例公开的层归一化处理方法的具体实施过程为:
[0088]
将中间矩阵g输入至层归一化处理硬件加速器中,每次输入该矩阵的一列元素,即
第一个时刻输入g(1,1)-g(s,1),第j个时刻输入g(1,j)-g(s,j),依次类推,直到最后一个时刻输入g(1,dmodel)-g(s,dmodel)。与此同时,层归一化处理硬件加速器中的中间矩阵存储单元、第一均值计算单元、第二平方计算单元及第二均值计算单元执行以下操作:把中间矩阵g存储于“中间矩阵存储单元”中;累加计算出累加计算出在中间矩阵g输入完成后,便得到在中间矩阵g输入完成后,便得到以及以及利用第一平方计算单元,计算得到e(g,1)2、e(g,2)2及e(g,s)2。
[0089]
根据第一均值计算单元、第二均值计算单元及第一平方计算单元的运算结果,利用平方根倒数计算单元中的加法器计算出var(g,1)=e(g,1)
2-e(g.*g,1)、var(g,2)=e(g,2)
2-e(g.*g,2)、
……
、var(g,s)=e(g,s)
2-e(g.*g,s),再利用“x^(-0.5)”运算单元求出r1=(var(g,1) ε)^(-0.5),r2=(var(g,2) ε)^(-0.5),
……
,rs=(var(g,s) ε)^(-0.5)。
[0090]
根据中间矩阵存储单元、第一均值计算单元及平方根倒数计算单元的运算结果,输出矩阵计算单元根据公式计算最终的输出矩阵。第一个时刻的输出为output(1,1)、output(2,1)、
……
、output(s,1),第二个时刻的输出为output(1,2)、output(2,2)、
……
、output(s,2),直到第dmodel个时刻,输出output(1,dmodel)、output(2,dmodel)、
……
、output(s,dmodel),获取层归一化处理硬件加速器最终的输出矩阵。
[0091]
本技术第三实施例公开了一种计算机设备,包括:
[0092]
存储器,用于存储计算机程序。
[0093]
处理器,用于执行所述计算机程序时实现如本技术第二实施例所述的应用于transformer神经网络的层归一化处理方法的步骤。
[0094]
本技术第四实施例公开了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理执行时实现如本技术第二实施例所述的应用于transformer神经网络的层归一化处理方法的步骤。
[0095]
以上结合具体实施方式和范例性实例对本技术进行了详细说明,不过这些说明并不能理解为对本技术的限制。本领域技术人员理解,在不偏离本技术精神和范围的情况下,可以对本技术技术方案及其实施方式进行多种等价替换、修饰或改进,这些均落入本技术的范围内。本技术的保护范围以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。