1.本发明涉及大数据分析技术领域,更具体地,涉及一种基于大数据的传播主张和消费者故事分析方法及系统。
背景技术:
2.传播主张研究对企业洞察市场而言至关重要。无论是市场研究部进行消费者营销洞察,还是市场部对产品/品牌定位、声明品牌/活动营销传播主张、广告创意生产以及公关内容生产,都离不开对传播主张研究,并从中分析总结出消费者故事。
3.然而,互联网中用户生产内容(ugc)声音大多杂乱无序,表现为发声平台的多元分散、数据杂乱难以收集进行统计分析以及声音质量参差不齐。传统的分析研究方法难以深入剖析蕴含在大数据信息背后的传播主张,并构建出消费者故事。这导致在传统研究方法和技术下,传播主张的洞察十分低效,企业对于诸如“他们是谁,基于什么场景购买?市场的解决方案有什么痛点?还有什么潜在需求?”等与消费者认知密切相关的问题,无法有系统全面的认知和把握。
4.现有技术中,公开号为:cn106779827a中国发明专利,于2017年5月31日公开了一种互联网用户行为采集及分析检测的大数据方法,包括:(1)数据的搜集和预处理;(2)数据分析及挖掘;(3)对数据分析的结果加以利用。搜集互联网用户数据,主要是微博、qq、微信数据,包括用户的个人基本信息和网络发言数据;以及主要的互联网商业数据,包括电商,行业论坛,门户网站的相关频道,主要是商品,商品销量,以及用户评价等;通过自建计算集群来进行上述搜集,根据公开的信息去预测、补全未公开的信息,如年龄预测等。该方案虽然获取互联网用户行为数据进行分析,但并没有对传播主张进行分析,没有对消费者故事实现精细化分析与研究。
技术实现要素:
5.本发明为克服上述现有技术缺少基于大数据的传播主张和消费者故事分析的缺陷,提供一种基于大数据的传播主张和消费者故事分析方法及系统。
6.本发明的首要目的是为解决上述技术问题,本发明的技术方案如下:
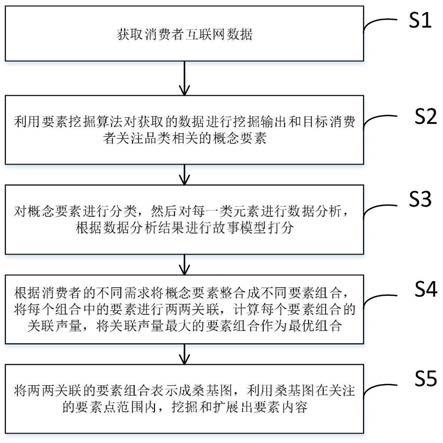
7.一种基于大数据的传播主张和消费故事分析方法,包括以下步骤:
8.s1:获取消费者互联网数据;
9.s2:利用要素挖掘算法对获取的数据进行挖掘输出和目标消费者关注品类相关的概念要素;
10.s3:对概念要素进行分类,然后对每一类元素进行数据分析,根据数据分析结果进行故事模型打分;
11.s4:根据消费者的不同需求将要素整合成不同要素组合,将每个组合中的要素进行两两关联,计算每个要素组合的关联声量,将关联声量最大的要素组合作为最优组合;
12.s5:将两两关联的要素组合表示成桑基图,利用桑基图在关注的要素点范围内,挖
掘和扩展出要素内容。
13.进一步地,所述消费者互联网数据获取的渠道包括:通用型社交媒体、论坛网站、行业垂直论坛。
14.进一步地,步骤s2所述利用要素挖掘算法对获取的数据进行挖掘输出和目标消费者关注品类相关的概念要素具体步骤为:
15.确定标注的要素;
16.对训练数据进行标注;
17.利用微调预训练模型的方法对现有的命名实体识别模型进行预训练,使命名实体识别模型学习标注数据中的信息;
18.将要分析的文本输入至训练好的命名实体识别模型,输出概念要素。
19.进一步地,步骤s3中对概念要素进行分类,然后对每一类元素进行数据分析,根据数据分析结果对进行故事模型打分具体步骤为:
20.将概念要素分为五种类型,对每种要素类型进行数据分析,所述数据分析包括:基于声量的热度排行和上升速度排行分析;
21.将数据分析结果输入至故事模型进行打分,得到消费者故事分数。
22.进一步地,所述基于声量的热度排行通过目标要素在筛选的时间范围内在互联网出现的文章提及声量值来计算得到;所述上升速度排行则通过目标要素在过去一段时间内,每个月的声量的增长情况来计算得到。
23.进一步地,故事模型通过三个方面指标进行打分即:故事类型、文章中人物的情绪、故事的整体丰富度。
24.进一步地,步骤s4所述的根据消费者的不同需求将要素进行整合成不同要素组合,其中,以消费者的情感诉求为需求的组合包括要素类型有:情感需求,自我描述,需求场景;以消费者的产品体验为需求的组合包括要素类型有:产品痛点,自我描述,使用场景。
25.进一步地,步骤s4的具体过程为:
26.根据消费者的不同需求将要素整合成不同要素组合,将每个组合中的要素进行两两关联,计算每个要素组合的关联声量,将关联声量最大的要素组合作为对应类型组合的最优解,用户的需求和具体诉求计算出推荐指数,输出最优组合。
27.进一步地,在桑基图中两个要素之间的连线的粗细代表两个要素关联度的高低,连线越粗代表两个要素的关联越高,连线越细,代表两个要素关联度越低。
28.本发明第二方面提供了一种基于大数据的传播主张和消费者故事分析系统,包括存储器和处理器,所述存储器中包括基于大数据的传播主张和消费者故事分析方法程序,所述基于大数据的传播主张和消费者故事分析方法程序被所述处理器执行时实现如下步骤:
29.s1:获取消费者互联网数据;
30.s2:利用要素挖掘算法对获取的数据进行挖掘输出和目标消费者关注品类相关的概念要素;
31.s3:对概念要素进行分类,然后对每一类元素进行数据分析,根据数据分析结果进行故事模型打分;
32.s4:根据消费者的不同需求将要素整合成不同要素组合,将每个组合中的要素进
行两两关联,计算每个要素组合的关联声量,将关联声量最大的要素组合作为最优组合;
33.s5:将两两关联的要素组合表示成桑基图,利用桑基图在关注的要素点范围内,挖掘和扩展出要素内容。
34.与现有技术相比,本发明技术方案的有益效果是:
35.本发明基于获取的消费者互联网数据,通过要素提取、分类、故事打分,进一步通过要素关联得到最优组合,同时基于两两关联的要素能够挖掘和扩展出要素内容,本发明提高了数据处理分析效率,自动化的分析过程减少人工投入,通过要素的拆解组合,提供了便捷的新故事生成路径。
附图说明
36.图1为本发明一种基于大数据的传播主张和消费故事分析方法流程图。
37.图2为本发明实施例桑基图结合知识图谱工具扩展出的要素内容示意图。
38.图3为本发明一种基于大数据的传播主张和消费故事分析系统框图。
具体实施方式
39.为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本技术的实施例及实施例中的特征可以相互组合。
40.在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
41.实施例1
42.如图1所示,一种基于大数据的传播主张和消费故事分析方法,包括以下步骤:
43.s1:获取消费者互联网数据;
44.需要说明的是,本发明中的消费者互联网数据可以是消费者发布在论坛或者站点的的产品使用日志、产品体验分享等,消费者互联网数据可以从消费者热门发表言论的数据站点获取,只有消费者的真实消费产品反馈声音存在的数据站点才有价值的数据点,所述的在具体的实施过程中基于对行业品类的特性,设定特定的站点,例如通用型社交媒体、论坛网站,可以为多个品类行业提供消费者反馈声音收集,汽车行业品类、母婴行业品类则可以通过行业垂直论坛获取消费者互联网数据。
45.s2:利用要素挖掘算法对获取的数据进行挖掘输出和目标消费者关注品类相关的概念要素;
46.需要说明的是,步骤s1中获取的消费者互联网数据一般多元分散、数据杂乱,因此需要挖掘出与消费者故事相关的概念要素,本发明中利用要素挖掘算法对获取的数据进行挖掘输出和目标消费者关注品类相关的概念要素;具体步骤为:
47.确定标注的要素;
48.对训练数据进行标注;
49.利用微调预训练模型的方法对现有的命名实体识别模型进行预训练,使命名实体识别模型学习标注数据中的信息;
50.将要分析的文本输入至训练好的命名实体识别模型,输出概念要素。
51.需要说明的是,所述的训练数据可以从步骤s1获取的消费者互联网数据中选取。
52.s3:对概念要素进行分类,然后对每一类元素进行数据分析,根据数据分析结果进行故事模型打分;
53.需要说明的是,在本发明中根据步骤s2挖掘输出的概念要素,将概念要素分为5类,包括:人设、需求场景、情感需求、使用场景、产品痛点;对于每个不同的要素类型,进行数据分析,包括基于声量进行热度排行和上升速度排行,其中,所述基于声量的热度排行通过目标要素在筛选的时间范围内在互联网出现的文章提及声量值来计算得到;所述上升速度排行则通过目标要素在过去一段时间内,每个月的声量的增长情况来计算得到。通过设置热度排行和上升速度排行方便后续在相关的类型内进行独立对比,即某行业品类内,该需求场景或者情感需求最典型,短期内最需要被解决的问题是什么,帮助从业人员快速识别并获得数据分析结果;
54.进一步的,将数据分析结果输入至故事模型进行打分,得到消费者故事分数。在得到消费者故事分数后可以按照得分进行排序,提供给从业人员一个最重点关注的故事排列输出。
55.在本发明中,故事模型从三个方面的指标进行打分即:故事类型、文章中人物的情绪、故事的整体丰富度。所述的故事类型即消费者互联网数据包括产品感受、生活记录、科普文章、提问内容、营销广告等,不同的文章类型代表了不同业务价值的文章质量,不同的文章有不同的质量偏好,和真实消费者用户相关的高质量内容则故事类型指标的分值相应高。
56.所述文章中人物的情绪即消费者互联网数据中情绪的描述,人物的情绪包括:情绪的波动程度即正面的情绪和负面的情绪,情绪的复杂程度包括:基础简单情绪的表达和复杂情绪的陈述,例如“迎难而上”、“物流速度超快”、“心心念念的期盼”等词汇表达的是正面的情绪,同时也是基础简单的情绪表达,不同的情绪波动程度和情绪复杂程度对应不同的分数。
57.所述故事的整体丰富度即包含概念要素的数量,文章包含概念要素越多,整体丰富度分数越高。
58.s4:根据消费者的不同需求将要素整合成不同要素组合,将每个组合中的要素进行两两关联,计算每个要素组合的关联声量,将关联声量最大的要素组合作为最优组合;
59.在本发明中,根据消费者的不同需求将要素整合成不同要素组合,其中,以消费者的情感诉求为需求的组合包括要素类型有:情感需求,自我描述,需求场景;以消费者的产品体验为需求的组合包括要素类型有:产品痛点,自我描述,使用场景。
60.更具体的,根据消费者的不同需求将要素整合成不同要素组合,将每个组合中的要素进行两两关联,计算每个要素组合的关联声量,将关联声量最大的要素组合作为对应类型组合的最优解,用户的需求和具体诉求计算出推荐指数,输出最优组合。
61.需要说明的是,在本发明中,所述的关联声量指的是共同提及,在一个故事里面某两个要素经常一起被共同提及;
62.s5:将两两关联的要素组合表示成桑基图,利用桑基图在关注的要素点范围内,挖掘和扩展出要素内容。
63.需要说明的是,在步骤s4在俩俩关联的要素组合产生之后,系统就可以从业务的角度帮助业务人员快速生成桑基图,来展现用户在各个行为和偏好之间的关联关系和故事线,在桑基图中两个要素之间的连线越粗代表两个要素的关联度越高,即共同提及次数更多,连线越细,说明两个要素的共同提及次数较少,关联度越低。在一个具体的实施例中,通过桑基图的展示帮助业务人员完成基础的品类关联关系概览之后,基于某个故事链路点,用户还可以基于桑基图的结果继续自由探索和扩展,结合现有的知识图谱工具,在关注的要素点范围内,可以通过知识图谱的知识关联和拓展,快速挖掘或扩展相关的要素内容出来。如图2所示为本实施例中桑基图结合知识图谱工具扩展出的要素内容示意图。
64.如图3所示,本发明第二方面提供了一种基于大数据的传播主张和消费者故事分析系统,包括存储器和处理器,所述存储器中包括基于大数据的传播主张和消费者故事分析方法程序,所述基于大数据的传播主张和消费者故事分析方法程序被所述处理器执行时实现如下步骤:
65.s1:获取消费者互联网数据;
66.s2:利用要素挖掘算法对获取的数据进行挖掘输出和目标消费者关注品类相关的概念要素;
67.s3:对概念要素进行分类,然后对每一类元素进行数据分析,根据数据分析结果进行故事模型打分;
68.s4:根据消费者的不同需求将要素整合成不同要素组合,将每个组合中的要素进行两两关联,计算每个要素组合的关联声量,将关联声量最大的要素组合作为最优组合;
69.s5:将两两关联的要素组合表示成桑基图,利用桑基图在关注的要素点范围内,挖掘和扩展出要素内容。
70.显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
