1.本发明公开一种图像显示方法,特别涉及一种适用于具广角网络摄影机的视频会议系统的图像显示方法。
背景技术:
2.owl labs于美国专利证书号us 10,636154b2的专利文献中,已公开有关人形检测的方法,而理光于日本专利证书号jp 4908543b2的专利文献中,则公开有关声音检测的方法。因为现有的视频会议软件(如zoom)只能显示4:3或16:9的画面,水平视角(horizontal angular field of view,hfov)大于或等于180度的广角网络摄影机无法把整个细长全景图像(panoramic image)都传送给视频会议软件。即使有传送出去的图像,视频会议软件所显示的画面中,人物都会变得非常小,不易识别。为解决上述问题,因此提出本发明。
技术实现要素:
3.有鉴于此,如何减轻或消除上述相关领域的缺失,实为有待解决的问题。
4.根据本发明的一实施例,提供一种图像显示方法,适用于具广角网络摄影机的视频会议系统,该广角网络摄影机用以捕捉一全景图像,该全景图像的长宽比大于或等于2:1,该方法包含:根据该全景图像,框选多个感兴趣区域,其中各感兴趣区域具多个属性的至少其一;根据是否填入该全景图像的一部分与该些感兴趣区域的属性、位置及数量,选择多个预设画面布局之一当作一输出画面布局;以及,根据该些感兴趣区域的属性,将该全景图像的一部分及该些感兴趣区域的至少其一填入到该输出画面布局的对应视窗中,以形成一组合图框。
5.上述实施例的优点之一,是依据使用者喜好、是否有发言者及出席者人数及分布,从水平视角大于或等于180度的全景图像中选择次场景数据或感兴趣区域(region of interest,roi)以进行组合,有如导播般舍弃不重要的图像片段,使得出席者最后看到的组合图框就如亲临现场开会一般,不会遗漏任何重点,并且可以随时依照使用者偏好强调重点roi。此外,传统上从不同网络相机取得的全景图像的长宽比(aspect ratio)与一般视频软件所呈现的画面的长宽比不同时,仅能单纯地于画面上下方补黑边、左右边裁剪或变形处理,相比之下,本发明的图像显示方法除了明显提高画面利用率之外,亦大幅提升画面的美观程度。
6.本发明的其他优点将搭配以下的说明和附图进行更详细的解说。
附图说明
7.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
8.图1为根据本发明一实施例,显示一视频会议系统的示意图。
9.图2a至图2b为根据本发明一实施例,显示图像显示方法。
10.图3a至图3f为根据本发明一实施例,显示从全景图像到组合图框的所有roi的框选过程。
11.图4a至图4b为显示一差异图像与聚集多个差异区域的一示例。
12.图5显示本发明合并roi的条件与方法。
13.图6a至图6g为显示本发明不同的预设画面布局。
14.图7a至图7e为根据本发明,显示将不同长宽比的roi及全景图像填入输出画面布局中不同长宽比的对应视窗的示意图。
15.图8a至图8c为根据本发明,当输出画面布局改变时,显示不同转场特效。
16.附图标号:
17.100:视频会议系统
18.110a、110b:广角摄影机
19.120a、120b:导播装置
20.130a、130b:通讯装置
21.301:以人形/人脸检测来定位的roi
22.302:手动方式框选的roi
23.303:追踪中roi
24.304:说话中roi
25.305:已识别的roi
26.306:被合并的roi
27.310:全景图像
28.320:组合图框
具体实施方式
29.以下说明为完成发明的较佳实现方式,其目的在于描述本发明的基本精神,但并不用以限定本发明。实际的发明内容必须参考之后的权利要求范围。
30.必须了解的是,使用于本说明书中的“包含”、“包括”等词,用以表示存在特定的技术特征、数值、方法步骤、作业处理、元件以及/或组件,但并不排除可加上更多的技术特征、数值、方法步骤、作业处理、元件、组件,或以上的任意组合。
31.于权利要求中使用如“第一”、“第二”、“第三”等词是用来修饰权利要求中的元件,并非用来表示之间具有优先顺序,前置关系,或者是一个元件先于另一个元件,或者是执行方法步骤时的时间先后顺序,仅用来区别具有相同名字的元件。
32.必须了解的是,当元件描述为“连接”或“耦接”至另一元件时,可以是直接连结、或耦接至其他元件,可能出现中间元件。相反地,当元件描述为“直接连接”或“直接耦接”至另一元件时,其中不存在任何中间元件。使用来描述元件之间关系的其他语词也可类似方式解读,例如“介于”相对于“直接介于”,或者是“邻接”相对于“直接邻接”等等。
33.图1为根据本发明一实施例,显示一视频会议系统的示意图。该视频会议系统100包含二台广角网络摄影机110a、110b、两个导播装置120a、120b、以及至少两个通讯装置
130a~130b。设置于会议室a的广角网络摄影机110a拍摄所有与会人员,产生一个全景图像a,并通过网络或usb影片类别(usb video device class,uvc)传送给导播装置120a,而设置于会议室b的广角网络摄影机110b拍摄所有与会人员,产生一全景图像b并通过网络或uvc传送给导播装置120b。其中,该些广角网络摄影机110a~110b可为水平视角大于或等于180度的广角摄影机,可产生水平视角大于或等于180度的全景图像a~b。但本发明所定义的全景图像不限于水平视角大于或等于180度,而包括所有长宽比大于或等于2:1的图像。需特别说明的是,长宽比是指图像的宽度与高度之间的关系,而并非代表图像的物理尺寸或以像素为单位的尺寸。具体而言,本发明所定义的全景图像的长宽比主要包含360x180、180x60、360x60、180x90等常见格式,但不以此为限。
34.一实施例中,各导播装置利用一独立的处理器及一存储介质(图未示)来实施,例如图1的导播装置120b独立于该通讯装置130b之外,具有一独立的处理器及一存储介质(图未示)。另一实施例中,各导播装置利用对应通讯装置的处理器及存储介质(图未示)来实施,例如图1的该通讯装置130a包含该导播装置120a。上述各导播装置的该存储介质存储多个指令供其相对应的处理器执行:图2a至图2b的方法中所有的步骤。图2a至图2b的方法容后说明。该些通讯装置130a~130b包含,但不受限于,个人电脑、平板电脑、智慧型手机等等。通讯装置130a通过执行一第一视频软件(请参考步骤s220的相关说明),传送导播装置120a输出的组合图框a给通讯装置130b以及通过网络接收并显示通讯装置130b所传来的组合图框b;同样地,通讯装置130b通过执行一第二视频软件,传送导播装置120b输出的组合图框b给通讯装置130a以及通过网络接收并显示通讯装置130a所传来的组合图框a。如图1所示,该通讯装置130b设置于会议室b,而该通讯装置130a设置于会议室a,使得两个会议室内的人员通过通讯装置130a~130b的屏幕可以看见对方会议室的与会人员。
35.图2a至图2b绘示根据本发明一实施例的一图像显示方法。图3a至图3f绘示根据本发明一实施例,显示从广角网络摄影机110a及110b传递至导播装置120a及120b的全景图像,经处理为组合图框的所有roi的框选过程。以下,请同时参考图1、图2a、图2b、图3a至图3f,详细说明本发明的图像显示方法。
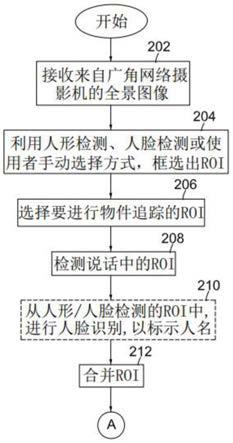
36.步骤s202:接收来自广角网络摄影机的全景图像310,该全景图像310的水平视角大于或等于180度。图3a为广角网络摄影机(110a、110b)所拍摄的全景图像310的一个例子。一实施例中,各广角网络摄影机(110a、110b)包含至少两个镜头及一麦克风阵列。
37.步骤s204:利用人形检测、人脸检测及使用者手动选择其中之一或其组合,于全景图像310中,检测或框选感兴趣区域roi。如图3b所示,根据本发明,要在一全景图像310中找出人的位置,使用人形检测或人脸检测来定位roi 301,也可以先以人形检测找出人形大致位置之后,再利用人脸检测精准定位roi 301。人形检测与人脸检测包含,但不受限于以下两种方式:(1)深度学习(deep learning),用来进行人工智慧检测(ai detection),例如使用程序语言python搭配电脑视觉库opencv、开源神经网络库keras与开源数据库tensorflow,藉由opencv撷取图像信息进行图像处理,使用keras提供的神经网络模块以tensorflow作为后端进行模型训练;(2)机器学习(machine learning),可利用隐性马可夫模型(hidden markov models,hmm)及支援向量机(support vector machines,svm)来实施。基本上,传统的机器学习需要开发者自己去决定特征要用什么(例如,把一张人的图变成一个梯度阵列(gradient array)),然后传给学习模块(如svm或hmm)去做训练及测试。而
深度学习则是可以由模块本身决定特征点(或者可以说特征点的撷取已经包含在模块里面了),所以可以直接把图传给深度学习模块(如多层感知器(multilayer perceptron,mlp)、深度神经网络(deep neural network,dnn)、卷积神经网络(convolutional neural network,cnn)、循环神经网络(recurrent neural network,rnn)等),就可以进行训练及测试。而深度学习及机器学习的技术已为本领域技术人员所熟知,故在此不予赘述。另请注意,上述深度学习及机器学习仅是示例,而非本发明的限制,现存或将来发展出来的其他人形/人脸检测方法亦可适用于本发明的概念。
38.在通篇说明书及后续的请求项当中所提及的相关用语定义如下,除非本说明书中另有特别指明。“框选一roi”一词指的是:利用一选取框来定义一全景图像中一roi(即一次场景)的有效范围。请注意,图3b至图3e中的矩形选取框仅是示例,而非本发明的限制,其他形状的选取框亦适用本发明的概念。“优先级”一词指的是:将一roi填入至一输出画面布局之一对应视窗的顺序。例如,优先级越高,该roi就越早被填入对应视窗。举例而言,优先级范围从1到5,其中1表示最低优先级,而5表示最高优先级;另一例子中,优先级范围从a到c,其中c表示最低优先级,而a表示最高优先级。
39.如图3b所示,最左边白板的roi 302无法利用前述人形检测或人脸检测的方式自动检测,但可由使用者手动选取。于任一roi 301及roi 302选取完之后,可以拖拉、放大以及缩小选取框,也能于roi 301及roi 302均选取完之后再增加或减少选取框的数量,甚至还能将该些roi 301~roi 302调整到想要的位置跟范围。请注意,最左边白板的roi 302,除了由使用者手动选取之外,也能采用任何已知方法来检测出白板或布幕或电视的roi。另外,在本步骤选取的roi 301~roi 302的属性全部被定义成“静态”,亦即,roi 301~302的大小与位置不会随着框内人物的移动而改变。
40.步骤s206:根据使用者需求,选择要进行物件追踪(object tracking)的roi。使用者主要是从步骤s204所选取的静态roi当中,选择要进行物件追踪的roi。例如,以图3b至图3c的例子而言,使用者从步骤s204所选取的roi 301~roi 302之中,选择其一当作要进行物件追踪的roi 303。请注意,本步骤将上述roi 303的属性定义成“动态”(或“追踪中”),亦即,roi 303的位置会跟着框内人物移动而移动。
41.本步骤以下列四种追踪方式来进行物件追踪(object tracking)(如追踪图3c的roi303内的人物):(1)特征撷取方式。特征撷取:输入roi 303=》角落检测=》输出多个角落点。追踪:输入特征点=》使用“光流法(optical flow)/均值偏移(mean shift)/移动估测(motion estimation)”来计算各点的移动向量=》决定群组的移动向量=》决定roi 303的移动向量。(2)人类姿势估测方式(human pose estimation):采用任何现存及未来发展的人类姿势估测方式。例如:定义人体结构,主要是人体主要关节及其连接;举例来说,可利用部件强度场(part intensity field,pif)找出各个人体关键点(主要关节)以及部件关联场(part association field,paf)用以将各关键点连结成完整人体模型=》将人体结构放入roi 303=》于roi 303中,将人体结构与人的姿势对齐。(3)前景(foreground)检测方式(利用前景来移动roi 303):平滑化(smooth)一图框=》计算目前的平滑化图像与先前的平滑化图像之间的一差异图像(difference image)(如图4a),由于物体移动是渐进的,因此明显的差异仅在于“物体边缘”,中间部份由于材质颜色相同因此差异不明显,这使得移动中的物体看起来像是由“线条”组成的轮廓;此差异图像为灰阶且有深有浅,且点与点之
间无明确联系=》为了更明确取得该物体的范围,对该差异图像进行二值化(binary)=》聚集(grouping)多个差异区域,例如对已二值化的差异图像进行扩张(dilation)、以及侵蚀(erosion)处理(结果如图4b)=》若该些经聚集后的差异区域与roi 303重叠,则移动roi 303以覆盖该些差异区域。(4)使用尺度不变特征转换(scale-invariant feature transform,sift)或方向梯度直方图(histogram of oriented gradient,hog)来进行特征比对与追踪。由于上述四种检测追踪方法已为本领域技术人员所熟知,故在此不予赘述。另请注意,上述四种检测追踪方法仅是示例,而非本发明的限制,现存或将来发展出来的其他检测追踪方法亦可适用于本发明的概念。
42.步骤s208:检测说话中的roi。本步骤利用下列二种方式,从上述三种roi301~roi303中,检测是否有人正在说话:(1)利用麦克风阵列来计算波束成型(beamforming),以估测声源方向(direction of arrival,doa),进而产生一可能声源方向。声源方向估测方法包含,但不受限于,最大可能性(maximum likelihood,ml)法、时间延迟估测(time delay estimation,tde)法、及特征结构(eigenstructure method)等等。(2)利用麦克风阵列来选择较大声音来源。以包含四个麦克风(声源方向分别为0度、90度、180度及270度)的麦克风阵列为例,假设90度及180度的声源方向收到的能量较大,分别为50分贝及60分贝,则选取该两个最大能量的麦克风做内插(interpolation)以决定角度,把分贝转成能量之后就等于180度的声音能量是90度的10倍,所以内插出来的可能声源方向就会是(180*10 90*1)/11≈172度。实际实施时,为方便后续比对水平视角及声源方向,必须适当架设广角网络摄影机(110a、110b)的镜头及麦克风阵列,使产生的全景图像水平视角0~360度刚好匹配麦克风的声源方向0~360度,例如全景图像水平视角0度匹配麦克风的声源方向0度、全景图像水平视角180度匹配麦克风的声源方向180度等等。
43.本步骤于检测会议室内是否有与会人员说话时,假设已选好上述三种roi301~303,故roi 301~303的各水平视角角度均为已知,当麦克风阵列检测到有人说话而算出一可能声源方向时,若任一roi 301~303的水平视角θ减去该可能声源方向θs的角度差值(θ-θs)小于一临界值θ
t1
时,则决定将角度差值小于该临界值θ
t1
的roi当作目前说话中的roi,如图3d中的roi 304。假设有两个roi 301~303的位置同时都邻近该可能声源方向且角度差值都小于该临界值θ
t1
时,则选择角度差值最小(即最近)的roi,当作目前说话中的roi 304。请注意,在本步骤选取的roi 304的属性被定义成“说话中”。
44.步骤s210:从人形检测及/或人脸检测的roi 301中,进行人脸识别,并自动标示人名。于本发明中使用的人脸识别方法,包括但不限于使用尺度不变特征转换(scale-invariant feature transform,sift)图像特征点、加速稳健特征(speeded up robust features,surf)图像特征点、局部二值模式特征向量直方图(local binary patterns histogram,lbph)作为图像特征点进行识别,以及基于主成分分析(principal components analysis,pca)分析数据的eigenface和使用线性判别分析(linear discriminant analysis,lda)的fisherface,依照不同的理论及方法让系统从已知的样本中学习并且找出分类的方法,以进行人脸识别。或者,也可以深度学习模块(如多层感知器(mlp)、深度神经网络(dnn)、卷积神经网络(cnn)、循环神经网络(rnn)等)进行人脸识别。本步骤可为以已事先训练好的模型进行已知样本的人脸识别,亦可搭配网络爬虫技术,同步进行名人的人脸识别。请参考图3e中的识别框305,并请注意,在本步骤选取的roi 305的属性被定义成“已识别”。由于本步骤并非必须,因此在图2a中以虚线显示。
45.步骤s212:于符合既定条件时,合并roi。本发明图像显示方法进行到本步骤时,已产生以下数据:(1)全景图像310;(2)不同属性的roi:例如“静态”的roi 301、302、“动态”的roi 303、“说话中”的roi 304及“已识别”的roi 305。图5显示本发明合并roi的条件与方法。为避免上述roi摆进输出画面布局的各视窗时会出现一些重复的人物/物件画面,若有符合下列两个条件的任一的至少两个roi,本步骤必须进行合并:(i)中心点视角接近的roi:例如图5中任两个感兴趣区域roi-1及roi-2(即上述roi 301~305)的中心点的水平视角差距(θ1-θ2)小于一预设角度θ
t2
时,就合并roi-1及roi-2,例如θ
t2
=10o;(ii)有重叠区域/像素的roi:任两个roi-1及roi-2(即上述roi 301~305)之间,只要有重叠的区域或像素,就进行合并roi。至于合并的方法,是将所有要合并的roi上下左右取联集区域,例如图5中的虚线矩形框roi 306合并了roi-1及roi-2。应特别注意的是,各roi可以不只对应一个属性,且在后续步骤当中,此一合并后的roi 306的属性之一可被设为“合并”、“具有多个人”、或“人数”(例如:2人)。另外,请注意,上述无论是合并后的roi 306或是合并前roi-1及roi-2,于后续的步骤s216中,都会被考虑是否填入一输出画面布局的对应视窗,以产生一组合图框320。
46.步骤s214:根据是否要填入该全景图像一部分与上述roi(301~306)的属性、位置及数量,从多个预设的画面布局(layout)中选择其一,当作一输出画面布局。本发明预设的画面布局包含,但不受限于,编制布局a-b(如图6a至图6b)、聚焦布局(如图6c)、格状布局(如图6d)、子母画面布局(如图6e)、主讲者布局(如图6f)以及由上而下布局(如图6g)。
47.图6a至图6f显示本发明不同的预设画面布局。各种不同属性及数量的roi适合不同的预设画面布局,而不同的预设画面布局具有不同的呈现方式以适合不同的会议人数、人员分布或场景。请注意,各预设画面布局中包含一个至多个不同或相同的尺寸及长宽比的视窗。例如:图6a的编制布局a包含三个不同尺寸及长宽比的视窗,而图6g的由上而下布局则包含两个相同尺寸及长宽比的视窗。
48.图6a至图6b显示二种编制布局a-b,适合roi较多且重点人物不只一人的情况。编制布局a-b都是在图框上方以横幅呈现全景图像(可看到全部的与会者),而图框下方则分别用两个以上的视窗呈现多位重点人物,且各视窗的尺寸及长宽比未必相同;需特别说明的是,编制布局a-b在图框上方不限于完整呈现全景图像,而可只呈现全景图像的一部分,只要能约莫看到全部的与会者即可。一实施例中,使用者亦可自由调整编制布局a-b图框上方欲呈现的部分。一实施例中,图框下方可用多个分割视窗呈现高达8位重点人物。图6c显示聚焦布局,适合多个位置接近的roi且该些roi所占据的位置只有整个360度的一部份,例如,本布局可以把上述位置接近的roi都框在一起成一个大视窗,或是将在一特定期间内有说话的roi都框在一起成一个大视窗。图6d显示格状布局,适合重要的(具最高优先级或/及次高优先级)roi的数量比较多且比较分散的场景,或者不重要的roi比较少也不需要用全景图像来呈现的场景;本布局呈现方式是把分群完毕的roi以工整的多格视窗来呈现,不一定要四格,也不一定要双数格子。图6d的例子中,四个视窗显示四位与会者,当有新的发言者加入时,会直接取代最久没发言的与会者。
49.图6e显示子母画面布局,适合有一个比较大的roi 302(例如白板或布幕或电视)且有与会者的场景;本布局呈现方式是在大视窗放白板或布幕或电视或主讲者的roi,而小
视窗显示讲解者或发问者roi。图6f显示主讲者布局,适合与会者较多而且主要发言者只有一人的场景;本布局呈现方式是在图框下方放全景图像且在图框上方放主讲者的roi 304,如果有人发问且主讲者可能有一段时间不讲话,才会将发问者的roi放入图框上方的大视窗。图6g显示由上而下布局,适合没有任何roi需要特别显示的情况;本布局主要是让广角的全景图像以上下各半的方式填入组合图框320的上下视窗中,值得注意的是,为了使组合图框320能够符合视频软件显示画面时所需要的长宽比,填入过程中可能会裁剪到全景图像上下缘的一部分,举例而言,假设广角全景图像长宽比是6:1且视频软件显示画面时所需要的长宽比是16:9(比例约等于1.78),若组合图框的上下视窗各显示半个全景图像的话,长宽比会等于3:2(比例约等于1.5)。在上下视窗的半个全景图像都不改变宽度,而采取均匀裁剪上下缘的方式填入上下视窗的前提下,上下各半个全景图像的上下缘都各会被切掉大约7.8%。
50.在本步骤中,根据是否要填入该全景图像的一部分与上述roi(301~306)的属性、位置及数量其中至少之一,从多个预设的画面布局(layout)中选择其一,当作一输出画面布局。举例而言,若要放入全景图像的一部分,可以选择编制布局a-b、主讲者布局或由上而下布局;若需要大的roi(白板或屏幕)来讲解(当作讲解画面),可以选择子母画面布局;若只有一个说话中roi(即单人主讲),可以选择主讲者布局;若有多个说话中的roi(即多人讨论),可以选择编制布局a-b、格状布局或聚焦布局;若多个roi在全景图像中的位置是相对接近的,可以选择聚焦布局;若多个roi在全景图像中的位置是相对分散的,可以选择格状布局。
51.步骤s216:根据上述roi(301~306)的属性,将该些roi或/及该全景图像的至少一部份填入该输出画面布局的对应视窗,以产生一组合图框320。须注意的是,上述各roi(301~306)及该全景图像的长宽比未必等于其对应视窗的长宽比,因此必须先调整roi及该全景图像的该至少一部份的长宽比。于一实施例中,除了编制布局a-b、主讲者布局以及由上而下布局需先放入全景图像至预设对应视窗之外,各roi依据本身属性,分别填入该输出画面布局的对应视窗中。举例而言,若各roi仅对应一个属性,可设定roi(301~306)的所有属性中,“说话中”属性的优先级最高、“合并”、“具有多个人”、或“人数多于1人”属性的优先级次之、“动态”属性的优先级再次之、“静态”及“已识别”属性的优先级最低;考量到图框的空间及视窗的数量都有限制,原则上,各输出画面布局优先显示具最高优先级的“说话中”roi,若还有剩余视窗,再显示具次高优先级的“合并”、“具有多个人”、或“人数多于1人”的roi,若还有剩余视窗,再显示具次次高优先级的“动态”roi,最后,若还有剩余视窗,再显示具最低优先级的“静态”及“已识别”roi,反之,若没有多余视窗/空间,就先放弃“静态”及“已识别”roi。另一个实施例中,各roi不只对应一个属性且不同属性具不同优先级,例如:“钉选”属性具有优先级a,“合并”、“具有多个人”、或“人数多于1人”属性具有优先级b,其余属性的优先级则为c,但在同为优先级c的属性当中还能再细分不同优先级,例如“说话中”属性的优先级最高,设为c3,“动态”属性的优先级次之,设为c2;“静态”及“已识别”属性的优先级最低,设为c1;换言之,包括“钉选”属性的roi,不论是否包含其他属性,必定具有优先级a,对于不具有“钉选”属性但包括“合并”、“具有多个人”、或“人数多于1人”属性的roi必定具有优先级b,至于只包括其他剩余属性的roi则具优先级c。
52.根据本发明,“钉选”属性直接被给予最高优先级,换言之,只要有“钉选“属性的
roi一定会被挑选及填入各输出画面布局的对应视窗,而且,“钉选”属性是使用者手动选择的属性,使用者可以自己决定钉选以及取消钉选。须注意的是,取决各输出画面布局的性质(例如:需放入全景图像、需有讲解画面、单人主讲或多人讨论),具有“钉选”属性的roi的数目会有所不同,例如,若一输出画面布局中只能填入四个具有“钉选”属性的roi,当使用者钉选到第5个roi时,第1个(最旧)被钉选的roi会立即被取消钉选。另一方面,各输出画面布局依其性质以及使用者偏好,可选择填入/显示例如优先级分别为1a1b2c(即包含一个具优先级a的roi、一个具优先级b的roi及两个具优先级c的roi)的四个roi。由于具有优先级a或b的roi数量必然较少,故具有优先级a的roi之间毋须进一步细分,具有优先级b的roi亦同。至于具有优先级c的roi因为类别及数量比较多,故必须根据优先级高低依序填入各输出画面布局的对应视窗。
53.一实施例中,各roi不只对应一个属性且不同属性具不同优先级,各输出画面布局是依优先级高低将roi排序以产生一排序后的感兴趣区域串,再依序填入对应视窗,而在比较多个roi的优先级的排序过程中,是取各roi的全部属性中所具有最高优先级来比较,若有两个(含)以上roi之间的最高优先级相同,则比次高优先级,依此类推,直到分出所有roi的优先级高低(以下称为逐一比较法)。例如:roi-1具有四个属性,其优先级分别为(5,4,2,1),roi-2具有三个属性,其优先级分别为(5,4,3),因为roi-1及roi-2的前两个优先级相同,但第三个优先级不同,故roi-2优先于roi-1。又例如:roi-3具有四个属性,其优先级分别为(5,4,2,1),roi-4具有三个属性,其优先级分别为(5,4,2),因为roi-3及roi-4的前三个优先级相同,再继续往下比时,由于roi-3有第四个优先级但roi-4却没有,故roi-3优先于roi-4。这种取最高优先级的做法也适用于一roi内包含有多个roi的情况。
54.另一实施例中,同样地,各roi不只对应一个属性且不同属性具不同优先级,但是各roi需先计算本身所具全部属性优先级的加总,即加总优先级,再依各roi加总优先级的高低将roi排序,而在比较多个roi的加总优先级的过程中,倘若其中有两个(含)以上的roi之间的加总优先级相同,再利用上述逐一比较法,由最高优先级开始比较,接着再比次高优先级,依此类推,直到分出所有roi的优先级高低以产生一排序后的感兴趣区域串(以下称为加总暨逐一比较法)。最后,根据优先级高低,将roi依序填入对应视窗。
55.另一实施例中,各roi不只对应一个属性且所有属性分成多个级别,而同一级别的属性中,再细分成多个类别,例如所有属性分成x、y、z三个级别且级别优先级分别是10、5、1,另外,属性y的级别再分成两个类别y1、y2且优先级分别是6、7。各输出画面布局先依级别优先级高低将roi排序,而在比较多个roi的级别优先级的排序过程中,是取各roi的全部属性中所具有最高级别优先级来比较,若有两个(含)以上roi之间的最高级别优先级相同,就以上述逐一比较法或上述加总暨逐一比较法,比较同一级属性中的类别优先级(例如比较y1及y2),若同一级属性中的类别优先级也相同,再比较下一级属性的级别优先级高低,依此类推,直到分出所有roi的优先级高低以产生一排序后的感兴趣区域串(以下称为级类别比较法)。最后,根据级别及类别优先级的高低,将roi依序填入对应视窗。
56.此外,根据本发明,任一roi被填入一特定视窗时不会影响输出画面呈现的美观度,即可定义该roi对于此特定视窗具有该优先级s,举例一:当roi的尺寸(scale)与对应视窗的尺寸大小差距在一定范围内(例如0.5倍到1.5倍之间)且不会因为放大或缩小roi太多而影响图像清晰度时,则可定义该roi对于该对应视窗具有该优先级s;举例二:当roi的长
宽比与对应视窗的长宽比不同并且无法利用扩大roi的选取框范围来达到和对应视窗一样的长宽比时(亦即扩大roi选取框范围的过程中会碰触到全景画面的边缘,如图7c的情况),该roi即不具有优先级s,反之,可定义该roi对于该对应视窗具有该优先级s。一实施例中,当一输出画面布局的所有视窗都选择具优先级s的roi时,可优先选择同时具有一最适合尺寸属性及/或一最适合长宽比属性的roi来填入对应视窗,以达到均匀化解析度或与会人员于画面中显示的大小均匀化的效果,进而美化输出画面布局。于另一实施例中,假设一输出画面布局的其中一个视窗需选择具有优先级s的roi,首先仍须利用上述三种方法(逐一比较法、加总暨逐一比较法及级类别比较法)的任一种比较出具优先级a的roi-a及具优先级b的roi-b,此时,若两个roi的优先级差距小于一个临界值th,则有优先级s的roi将会优先于没有优先级s的roi被填入该视窗,据此,即可保留该临界值th的弹性,换言之,临界值th越大,表示使用者觉得优先级s越重要。
57.图7a至图7e为根据本发明,绘示如何将不同长宽比的roi及全景图像填入输出画面布局中不同长宽比的对应视窗的示意图。将不同长宽比的roi及全景图像填入输出画面布局中不同长宽比的对应视窗的方法共有四种如下。方法一:于全景图像上,若可以扩大roi的选取框范围,则左右上下扩大选取框的范围,使其长宽比符合对应视窗的比例,例如图7a,原roi-a的比例3:4,经左右扩大选取框后,符合对应视窗的长宽比16:9;例如图7b,原roi-b的比例6:1,经上下扩大选取框后,即符合对应视窗的长宽比6:3。方法二:于全景图像上,能扩大就扩大选取框范围,若完全无法扩大,再根据对应视窗的长宽比,裁剪掉roi内多余的图像,例如图7d。方法三:当扩大该目标感兴趣区域的选取框范围过程中碰到该全景图像的边缘而无法再扩大时,就采取以下二种做法:方法(a):将选取框由全景图像边缘推回来以符合对应视窗的长宽比;方法(b):将选取框的一边补上黑边以符合对应视窗的长宽比。例如图7c的例子,原roi-c的比例6:1,经上下扩大选取框后,只能扩大到长宽比6:3,距离目标值6:4还有一段距离,此时可采用方法(a),将选取框由全景图像边缘向下推回来,使选取框范围符合对应视窗的长宽比6:4,结果是原roi位在对应视窗的偏上方(如右下图),但可完全采用全景图像的内容,较为自然。另一个选择是采用方法(b),将无法再扩大的选取框(6:3)的上方补上黑边以符合对应视窗的长宽比6:4,结果是原roi可以位在对应视窗的中间(如左下图)。方法四:于全景图像上,若无法扩大选取框范围及裁剪掉roi内多余的图像,就根据对应视窗的长宽比,直接将roi内的图像变形,如图7e中的圆形变椭圆形。
58.步骤s220:将该组合图框320传送给一视频软件以进行显示。例如,于图1中,通讯装置130a通过执行一视频软件a,传送导播装置120a输出的组合图框a给通讯装置130b,以及通过网络接收并显示该通讯装置130b所传来的组合图框b。传送给该视频软件的组合图框320符合现有一般视频软件指定/常用的长宽比或/及像素数。该视频软件包含各种视频会议软件及各种网络摄影机的应用软件,且各种视频会议软件包含但不受限于,zoom cloud meeting、skype、腾讯会议(tencent meeting)、思科会议(cisco webex meeting)、line、威立方会议(v-cube meeting)、谷歌视频会议(google meet)等等。上述组合图框320输出到各种网络摄影机的应用软件上后,可以用来直播,制作会议纪录,剪辑分享等等。
59.请注意,为了方便说明,上述图6a-6g的通讯装置130a~130b显示相同的画面布局,实际实施时,于导播装置120a~120b上执行的本发明图像显示方法,可根据各全景图像a~b上所选择/检测出的不同roi的属性及数量,各自选择不同输出画面布局以产生两个不
同组合图框320a~b,再通过网络传给通讯装置130a~130b以利显示。例如,图1中,通讯装置130b显示编制布局a,而通讯装置130a显示主讲者布局。
60.另外,请注意,会议的整个过程是动态的,全程的全景图像会持续变化,框选的roi的属性及数量也会随着全景图像内容而改变,之后,输出画面布局再随之而改变。例如,从会议室是空的到人数到齐(此时可能选用由上而下布局),到开始开会,到有人主讲(此时可能选用主讲者布局)、有人发问(此时可能选用子母画面布局)、有人移动、有人离席、有人加入(此时可能选用格状布局)、有少数人集结讨论(可能选用聚焦布局),到最后开会结束。
61.图8a至图8c根据本发明,当输出画面布局改变时,显示不同转场特效。当输出画面布局由a改变至b时,需要一些转场特效,例如图8a所示,输出画面布局a原本显示roi-x,转场后,输出画面布局b想要显示的是roi-y,虚线粗框表示在输出画面布局a内原本roi-x的显示范围,若将该显示范围放大1.2倍(等于左右各放大10%)后(虚线细框)会碰到目标roi-y的话,可直接在全景图像上由左至右移动镜头(pan)至目标roi-y,否则,表示转场距离太远,就在两个roi-x及roi-y之间直接切换做转场,如图8b所示。因为转场距离太远的情况下,若固定移动镜头(pan)的转速,可能会耗时过久,若固定转场时间的话,移动镜头的转速可能过快,这些都无法让消费者接受,故直接切换roi-x及roi-y做转场。以格状布局切换至主讲者布局为例,慢慢放大格状布局其中一个视窗的比例至主讲者布局的主讲者视窗大小,如图8c所示。
62.在输出画面布局中,可以依据roi/选取框的视角区域的不同,来选择不同投影方式来呈现画面。预设的投影方式包含,但不受限于,等距长方投影(equirectangular projection)、圆柱投影(cylinder projection)、透视投影(perspective projection)、帕尼尼投影(panini projection)以及鱼眼投影(fisheye projection)。
63.上述仅为本发明的较佳实施例而已,而并非用以限定本发明的申请专利范围;凡其他未脱离本发明所揭示的精神下所完成的等效改变或修饰,均应包含在下述申请专利范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。