1.本发明涉及计算机技术领域,尤其涉及一种事件预测模型的确定方法、装置、设备和存储介质。
背景技术:
2.发展态势预测用于预测事件在当下和/或未来的走向。目前,发展态势预测可以用于进行事件预警,也可以为事件的处理提供辅助。
3.针对某一事件,如果事件成因对事件结果产生即时性影响,而且该事件成因对事件结果影响具有确定性,那么可以预测发展态势。如:某家宾馆需要1000条毛巾(事件成因),那么纺织厂需要生成1000条毛巾(事件结果)。但是,如果事件成因和事件结果之间的关系具有不确定性,例如:事件成因和事件结果存在时差,事件结果受到已知事件成因和未知事件的影响,则由于事件成因的不确定性,使得事件的发展态势无法进行预测。
4.例如:城市污染情况一般通过专业设备测量获得,如:空气污染情况、水体污染情况、噪声污染情况都是通过专业设备进行测量获得的,虽然可以知道人口流动对城市污染存在影响,但是人口流动(事件成因)与城市污染情况(事件结果)之间的关系具有不确定性的,目前无法根据人口流动情况来预测空气污染情况、水体污染情况、噪声污染情况。
5.又如:河流上游的人流量大可能会对下游的环境产生不良影响,而上游的污染物到达下游需要一定时间,所以上游的人流量和下游的环境污染之间存在时差,目前尚没有一种方法可以根据上游的人流量预测下游的环境污染的情况。
6.再如:公共卫生事件多由人员流动产生,而且公共卫生事件可能存在潜伏期,所以事件成因(人员流动)和事件结果(卫生事件)存在时差,而该时差对于事件结果的走向会产生不确定性,如:时差的长短是未知的,时差期间出现大量的人员聚集会影响事件结果的走向,导致无法通过建模的方式预测公共卫生事件的未来走向。
技术实现要素:
7.本发明实施例的主要目的在于提供一种事件预测模型的确定方法、装置、设备和存储介质,以解决在现有技术中,如果事件成因和事件结果之间的存在不确定性,则无法进行态势预测的问题。
8.针对上述技术问题,本发明实施例是通过以下技术方案来解决的:
9.本发明实施例提供了一种事件预测模型的确定方法,包括:获取多个来源地区分别对应的历史迁移信息;在每个所述来源地区对应的历史迁移信息中,确定与事件信息的相关系数最大的历史迁移信息,作为所述来源地区对应的候选历史迁移信息;根据所述事件信息以及预设的回归模型,在所述多个来源地区分别对应的候选历史迁移信息中,筛选出符合预设模型回归条件的候选历史迁移信息;根据所述符合预设回归条件的候选历史迁移信息,生成样本迁移信息;根据所述样本迁移信息以及所述事件信息,确定事件预测模型,以便利用目标迁移信息以及所述事件预测模型执行事件信息预测。
10.其中,在所述获取多个来源地区分别对应的历史迁移信息之前,包括:多次执行采集聚合操作;其中,每次执行所述采集聚合操作包括:采集第一预设时间长度内的多个时间段分别对应的历史用户信息;其中,在每次执行采集聚合操作中,所述第一预设时间长度的起始时间不同;所述历史用户信息包括:进入所述目标地区的用户的来源地区;在所述第一预设时间长度内的多个时间段分别对应的历史用户信息中,聚合时间段相同并且来源地区相同的所述历史用户信息;根据聚合结果生成每个来源地区对应的历史迁移信息;其中,所述历史迁移信息用于表示在所述第一预设时间长度的每个时间段内,从所述历史迁移信息对应的来源地区进入所述目标地区的用户数量。
11.其中,在每个所述来源地区对应的历史迁移信息中,确定与事件信息的相关系数最大的历史迁移信息,作为所述来源地区对应的候选历史迁移信息,包括:获取第二预设时间长度内的多个时间段分别对应的目标事件数据并生成事件信息;所述第二预设时间长度与所述第一预设时间长度的时长相等;针对每个所述来源地区对应的多个历史迁移信息,计算所述事件信息分别与每个所述历史迁移信息的相关系数,并且确定与所述事件信息的相关系数最大的历史迁移信息,作为候选历史迁移信息。
12.其中,在每个所述来源地区对应的历史迁移信息中,确定与事件信息的相关系数最大的历史迁移信息之后,还包括:针对所述与事件信息的相关系数最大的历史迁移信息,确定所述历史迁移信息对应的第一时间长度的起始时间以及所述事件信息对应的第二时间长度的起始时间,将所述第一时间长度的起始时间和所述第二时间长度的起始时间的差值,作为所述历史迁移信息对应的时滞阶数;或者,针对所述与事件信息的相关系数最大的历史迁移信息,确定所述历史迁移信息对应的第一时间长度的结束时间以及所述事件信息对应的第二时间长度的结束时间,将所述第一时间长度的结束时间和所述第二时间长度的结束时间的差值,作为所述历史迁移信息对应的时滞阶数。
13.其中,根据所述符合预设回归条件的候选历史迁移信息,生成样本迁移信息,包括:在所述符合预设回归条件的候选历史迁移信息中,确定时滞阶数相同的所述候选历史迁移信息;在时滞阶数相同的所述候选历史迁移信息中,确定至少一组候选历史迁移信息的组合;每个组合中的候选历史迁移信息至少对应一个来源地区;在属于同一组合的候选历史迁移信息中,将相同时间段对应的用户数量进行求和运算,生成所述组合对应的样本迁移信息。
14.其中,根据所述样本迁移信息以及所述事件信息,确定事件预测模型,包括:针对每个所述样本迁移信息,将所述样本迁移信息以及所述事件信息输入预设的初始预测模型,并确定所述初始预测模型的拟合度;其中,每个所述样本迁移信息由至少一个来源地区对应的候选历史迁移信息生成的;将拟合度最大并且输入的样本迁移信息对应的来源地区最多的初始预测模型确定为事件预测模型;其中,所述预设确定条件包括:所述初始预测模型的拟合度大于预设的第一确定阈值并且所述初始预测模型的拟合度在所有初始预测模型中最大,输入所述初始预测模型的样本迁移信息对应的来源地区的数量大于预设的第二确定阈值并且在所有样本迁移信息中最多。
15.其中,根据所述事件信息以及预设的回归模型,在所述多个来源地区分别对应的候选历史迁移信息中,筛选出符合预设模型回归条件的候选历史迁移信息,包括:针对每个所述候选历史迁移信息,对所述候选历史迁移信息进行预设平稳性检验以及预设的正态性
检验,得到所述候选历史迁移信息对应的平稳指数以及分布类型;确定平稳指数处于预设平稳区间并且分布类型为正态分布的候选历史迁移信息作为模型自变量;将所述事件信息作为模型因变量输入到所述回归模型中;针对每个所述模型自变量,将所述模型自变量输入所述回归模型,确定所述回归模型的模型参数,在所述模型参数处于预设参数区间的情况下,将所述模型自变量确定为符合预设模型回归条件的候选历史迁移信息。
16.其中,在将所述模型自变量输入所述回归模型之前,还包括:如果模型自变量的数量小于预设的数量阈值,则在平稳指数未处于预设平稳区间或者分布类型不是正态分布的候选历史迁移信息中,对所述候选历史迁移信息中的部分信息进行所述平稳性检验以及所述正态性检验,得到所述部分信息对应的平稳指数以及分布类型;确定平稳指数处于预设平稳区间并且分布类型为正态分布的部分信息作为模型自变量。
17.其中,所述回归模型包括:为每个所述来源地区对应设置的单回归模型和自回归模型;将所述模型自变量输入所述回归模型,确定所述回归模型的参数模型,在所述模型参数处于预设参数区间的情况下,将所述模型自变量确定为符合预设模型回归条件的候选历史迁移信息,包括:确定所述模型自变量对应的来源地区;将所述模型自变量输入所述来源地区对应的单回归模型和自回归模型中;分别对所述单回归模型和所述自回归模型执行预设的显著性检验;在所述单变量回归模型和所述自回归模型都通过所述显著性检验的情况下,确定所述单回归模型对应的拟合度;在所述单变量回归模型对应的拟合度处于预设拟合度区间的情况下,将所述模型自变量确定为符合预设模型回归条件的历史迁移信息。
18.其中,在利用目标迁移信息以及所述事件预测模型执行事件信息预测之前,还包括:获取历史迁移信息或者当前迁移信息;将所述历史迁移信息或者当前迁移信息输入预设的迁移走势预测模型,获取所述迁移走势预测模型输出的未来时间区间对应的未来迁移信息,将所述未来时间区间对应的未来迁移信息作为目标迁移信息。
19.本发明实施例还提供了一种事件预测模型的确定装置,包括:获取模块,用于获取多个来源地区分别对应的历史迁移信息;第一确定模块,用于在每个所述来源地区对应的历史迁移信息中,确定与事件信息的相关系数最大的历史迁移信息,作为所述来源地区对应的候选历史迁移信息;筛选模块,用于根据所述事件信息以及预设的回归模型,在所述多个来源地区分别对应的候选历史迁移信息中,筛选出符合预设模型回归条件的候选历史迁移信息;生成模块,用于根据所述符合预设回归条件的候选历史迁移信息,生成样本迁移信息;第二确定模块,用于根据所述样本迁移信息以及所述事件信息,确定事件预测模型,以便利用目标迁移信息以及所述事件预测模型执行事件信息预测。
20.本发明实施例还提供了一种事件预测模型的确定设备,所述事件预测模型的确定设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现上述任一项所述的事件预测模型的确定方法。
21.本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有事件预测模型的确定程序,所述事件预测模型的确定程序被处理器执行时实现上述任一项所述的事件预测模型的确定方法。
22.本发明实施例的有益效果如下:
23.在本实施例中,针对每个来源地区,确定该来源地区与事件信息相关程度最高的历史迁移信息作为候选历史迁移信息;在多个来源地区分别对应的候选历史迁移信息筛选
出符合模型回归条件的候选历史迁移信息,筛选出能够使得事件预测模型更加稳健的候选历史迁移信息;利用符合预设回归条件的候选历史迁移信息,生成样本迁移信息,使得样本迁移信息融合不同来源地区的信息;使用样本迁移信息以及事件信息挑选最优的初始预测模型作为事件预测模型。通过本实施例的方法可以确定预测准确度较高的事件预测模型,通过该事件预测模型使得迁移信息与事件信息产生联系,通过该事件预测模型预测迁移信息对应的事件信息。
附图说明
24.此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
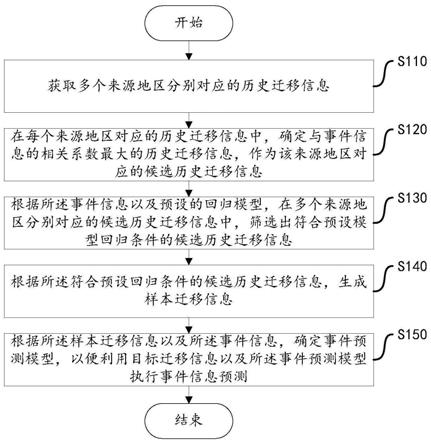
25.图1是根据本发明一实施例的事件预测模型的确定方法的流程图;
26.图2是根据本发明一实施例的采集聚合操作的步骤流程图;
27.图3是根据本发明一实施例的筛选候选历史迁移信息的步骤流程图;
28.图4是根据本发明一实施例的筛选候选历史迁移信息的具体步骤流程图;
29.图5是根据本发明一实施例的历史迁移信息与河流污染信息的时差相关分析结果的示意图;
30.图6是根据本发明一实施例的样本迁移信息的生成步骤流程图;
31.图7是根据本发明一实施例的事件预测模型的确定步骤流程图;
32.图8是根据本发明一实施例的未来迁移信息的预测步骤流程图;
33.图9是根据本发明一实施例的未来迁移信息的预测示意图;
34.图10是根据本发明一实施例的事件预测模型的确定装置的结构图;
35.图11是根据本发明一实施例的事件预测模型的确定设备的结构图。
具体实施方式
36.为使本发明的目的、技术方案和优点更加清楚,以下结合附图及具体实施例,对本发明作进一步地详细说明。
37.根据本发明的实施例,提供了一种事件预测模型的确定方法。如图1所示,为根据本发明一实施例的事件预测模型的确定方法的流程图。
38.步骤s110,获取多个来源地区分别对应的历史迁移信息。
39.历史迁移信息为在目标地区发生的目标事件的事件成因。目标事件例如是:空气污染事件、公共卫生事件、春运滞留事件等。
40.每个来源地区对应的历史迁移信息是指:在第一预设时间长度的每个时间段内,从该来源地区进入目标地区的用户数量。
41.第一预设时间长度可以是经验值或者实验值。该第一预设时间长度的起始时间可以根据需求而定。
42.进一步地,每个来源地区对应的历史迁移信息可以为迁移序列;迁移序列中的每个元素为:在第一预设时间长度内的一个时间段,该来源地区进入目标地区的用户数量。例如:第一预设时间长度为一周,一周包括7天,获取一周7天中每天对应的用户数量,该用户数量为从来源地区进入目标地区的用户数量,迁移序列中的一个元素对应一天的用户数
量。
43.每个来源地区可以对应多个历史迁移信息,每个历史迁移信息对应的第一预设时间长度的起始时间不同。例如:来源地区对应当前时间的前一周的迁移序列,前二周的迁移序列和前三周的迁移序列。
44.步骤s120,在每个来源地区对应的历史迁移信息中,确定与事件信息的相关系数最大的历史迁移信息,作为该来源地区对应的候选历史迁移信息。
45.事件信息是指在第二预设时间长度内的多个时间段分别对应的目标事件数据。第二预设时间长度与第一预设时间长度的时长相等。第二预设时间长度的起始时间与第一预设时间长度的起始时间可以相同,也可以不相同。
46.目标事件数据为目标事件的事件结果。例如:空气污染事件造成的空气污染指数,公共卫生事件出现的发病人数,春运滞留事件出现的滞留人数。
47.相关系数,用于表示历史迁移信息与事件信息之间的相关程度。相关系数越大,历史迁移信息与事件信息之间的相关程度越高。相关系数越小,历史迁移信息与事件信息之间的相关程度越低。候选历史迁移信息作为后续用于确定事件预测模型的基础数据。
48.具体而言,获取第二预设时间长度内的多个时间段分别对应的目标事件数据并生成事件信息;针对每个所述来源地区对应的多个历史迁移信息,计算所述事件信息分别与每个所述历史迁移信息的相关系数,并且确定与所述事件信息的相关系数最大的历史迁移信息,作为候选历史迁移信息。
49.进一步地,事件信息可以为事件序列;事件序列中的每个元素为:第二预设时间长度内的一个时间段分别对应的目标事件数据。例如:事件序列为一周内每天的空气污染指数,事件序列的每个元素对应一天的空气污染指数。
50.由于每个来源地区可以对应多个历史迁移信息,所以针对每个来源地区,确定一个与事件信息的相关系数最大的历史迁移信息,将该历史迁移信息作为候选历史迁移信息。其中,如果来源地区对应一个历史迁移信息,则将该历史迁移信息确定为与该事件序列的相关系数最大的历史迁移信息。
51.步骤s130,根据所述事件信息以及预设的回归模型,在多个来源地区分别对应的候选历史迁移信息中,筛选出符合预设模型回归条件的候选历史迁移信息。
52.回归模型,用于筛选符合预设模型回归条件的候选历史迁移信息。回归模型为多元线性回归模型。
53.模型回归条件,包括:候选历史迁移信息的平稳指数处于预设平稳区间并且分布类型为正态分布,候选历史迁移信息和事件信息输入回归模型之后,使回归模型的模型参数大于预设参数阈值。
54.平稳区间的范围可以为经验值,或者为通过实验获得的值。
55.回归模型的模型参数,包括但不限于:拟合度。
56.步骤s140,根据所述符合预设回归条件的候选历史迁移信息,生成样本迁移信息。
57.样本迁移信息是由至少一个来源地区对应的符合预设模型回归条件的候选历史迁移信息生成的。
58.步骤s150,根据所述样本迁移信息以及所述事件信息,确定事件预测模型,以便利用目标迁移信息以及所述事件预测模型执行事件信息预测。
59.样本迁移信息的数量为多个;每个样本迁移信息由至少一个来源地区对应的候选历史迁移信息生成的;针对每个样本迁移信息,将该样本迁移信息以及事件信息输入预设的初始预测模型,并确定初始预测模型的拟合度;将拟合度最大并且输入的样本迁移信息对应的来源地区最多的初始预测模型确定为事件预测模型。
60.在本实施例中,针对每个来源地区,确定该来源地区与事件信息相关程度最高的历史迁移信息作为候选历史迁移信息;在多个来源地区分别对应的候选历史迁移信息筛选出符合模型回归条件的候选历史迁移信息,筛选出能够使得事件预测模型更加稳健的候选历史迁移信息;利用符合预设回归条件的候选历史迁移信息,生成样本迁移信息,使得样本迁移信息融合不同来源地区的信息;使用样本迁移信息以及事件信息挑选最优的初始预测模型作为事件预测模型。通过本实施例的方法可以确定预测准确度较高的事件预测模型,通过该事件预测模型使得迁移信息与事件信息产生联系,通过该事件预测模型预测迁移信息对应的事件信息。
61.下面对本发明实施例的事件预测模型的确定方法进行进一步地描述。
62.在获取多个来源地区分别对应的历史迁移信息之前,还需要进行信息采集和聚合操作,以便生成多个来源地区分别对应的历史迁移信息。
63.在本实施例中,多次执行采集聚合操作,下面针对每次采集聚合操作执行的步骤进行描述。
64.如图2所示,为根据本发明一实施例的采集聚合操作的步骤流程图。
65.步骤s210,采集第一预设时间长度内的多个时间段分别对应的历史用户信息;所述历史用户信息包括:进入所述目标地区的用户的来源地区。
66.在每次执行采集聚合操作中,所述第一预设时间长度的起始时间不同。
67.每个时间段可以对应多个历史用户信息。
68.例如:在第一次执行采集聚合操作时,采集第一周内每天对应的多个历史用户信息;在第二次执行采集聚合操作时,采集第二周内每天对应的多个历史用户信息;在第三次执行采集聚合操作时,采集第三周内每天对应的多个历史用户信息。
69.具体而言,历史用户信息包括但不限于:移动运营商的信令数据,移动app(application,应用程序)的历史报点数据,历史电商订单信息以及历史支付地址信息。移动app的历史报点数据是指移动app所在设备的定位信息。进一步地,移动运营商的信令数据可以确定用户对应的归属位置寄存器,根据该归属位置寄存器所在的地区作为用户的来源地区。根据移动app的历史报点数据,历史电商订单信息以及历史支付地址信息,可以确定用户在一段时间内的地区变化,将用户保持时间最长的地区作为用户的来源地区。
70.步骤s220,在所述第一预设时间长度内的多个时间段分别对应的历史用户信息中,聚合时间段相同并且来源地区相同的所述历史用户信息。
71.步骤s230,根据聚合结果生成每个来源地区对应的历史迁移信息;其中,所述历史迁移信息用于表示在所述第一预设时间长度的每个时间段内,从所述历史迁移信息对应的来源地区进入所述目标地区的用户数量。
72.在完成信息采集后,按照来源地区的不同,对每个时间段对应的多个历史用户信息进行聚合处理;确定时间段相同并且来源地区相同的多个历史用户信息的数量,将该数量作为该来源地区在该时间段对应的用户数量。将该来源地区在多个时间段分别对应的用
户数量作为历史迁移信息中的元素,进而得到该来源地区在本次采集聚合操作中对应的历史迁移信息。
73.进一步地,来源地区可以为省级行政区。在考虑进入北京市的人流对公共卫生事件或者空气污染事件的影响时,可以生成北京市以外的33个省级行政区(来源地区)分别对应的历史迁移信息,记为x
i,t
,i(=1,2,
…
,33),i表示来源地区编码,每个来源地区编码对应一个省级行政区,t表示第一时间长度的起始时间。
74.在多次执行采集聚合操作之后,针对每个来源地区,可以得到该来源地区对应的多个历史迁移信息,每个历史迁移信息来自一次采集聚合操作。
75.在本实施例中,为了对历史迁移信息和事件信息进行更好的分析,历史迁移信息的生成时间可以早于事件信息的发生时间。例如:事件信息的发生时间在2020.7.6~2020.7.12,那么可以采集2020.6.22~2020.6.28的历史用户信息,2020.6.29~2020.7.5的历史用户信息,确定2020.6.22~2020.6.28时间区间内每个来源地区对应的历史迁移信息以及2020.6.29~2020.7.5时间区间内每个来源地区对应的历史迁移信息。这样,就可以在确定事件预测模型时,可以获取2020.6.22~2020.6.28时间区间内每个来源地区对应的历史迁移信息以及2020.6.29~2020.7.5时间区间内每个来源地区对应的历史迁移信息。在2020.6.22~2020.6.28时间区间内每个来源地区对应的历史迁移信息中,确定每个来源地区与事件信息相关程度最大的历史迁移信息,作为每个来源地区对应的候选历史迁移信息;在2020.6.29~2020.7.5时间区间内每个来源地区对应的历史迁移信息中,确定每个来源地区与事件信息相关程度最大的历史迁移信息,作为每个来源地区对应的候选历史迁移信息。
76.下面对如何在多个来源地区分别对应的候选历史迁移信息中,筛选出符合预设模型回归条件的候选历史迁移信息进行进一步地描述。
77.图3为根据本发明一实施例的筛选候选历史迁移信息的步骤流程图。
78.步骤s310,针对每个候选历史迁移信息,对所述候选历史迁移信息进行预设平稳性检验以及预设的正态性检验,得到所述候选历史迁移信息对应的平稳指数以及分布类型。
79.平稳性检验可以使用adf(augmented dickey-fuller test)检验。
80.正态性检验可以使用j-b(jarque-bera)检验。
81.为了建立稳定的回归模型,需要对每个候选历史迁移信息进行平稳性检验以及正态性检验,以便确定该候选历史迁移信息是否平稳且符合正太分布。
82.步骤s320,确定平稳指数处于预设平稳区间并且分布类型为正态分布的候选历史迁移信息作为模型自变量。
83.平稳区间的两个端值可以为经验值或者通过实验获得值。
84.如果平稳性检验输出的平稳指数处于平稳区域,则说明候选历史迁移信息平稳。如果正态性检验输出的分布类型为正太分布,则说明候选历史迁移信息符合正太分布。
85.在将模型自变量输入回归模型之前,确定模型自变量的数量;如果模型自变量的数量小于预设的数量阈值,则在平稳指数未处于预设平稳区间或者分布类型不是正态分布的候选历史迁移信息中,对所述候选历史迁移信息中的部分信息进行所述平稳性检验以及所述正态性检验,得到所述部分信息对应的平稳指数以及分布类型;确定平稳指数处于预
设平稳区间并且分布类型为正态分布的部分信息作为模型自变量。
86.步骤s330,将所述事件信息作为模型因变量输入到所述回归模型中。
87.步骤s340,针对每个模型自变量,将所述模型自变量输入所述回归模型,确定所述回归模型的模型参数,在所述模型参数处于预设参数区间的情况下,将所述模型自变量确定为符合预设模型回归条件的候选历史迁移信息。
88.回归模型的模型类型包括但不限于:拟合度。
89.预设参数区域为拟合度区间。该拟合度区间的两个端值为经验值或者通过实验获得的值。例如:该拟合度区间为0.4至正无穷,也即是说,拟合度区间为大于0.4的范围。
90.回归模型包括:为每个来源地区对应设置的单回归模型和自回归模型。例如:为每个省对应设置一个单回归模型和一个自回归模型。
91.单回归模型可以通过以下公式来表示:
[0092][0093]
其中,y
t
表示事件信息;表示第i个来源地区对应的模型自变量,即平稳指数处于预设平稳区间并且分布类型为正态分布的候选历史迁移信息;pi表示第i个来源地区对应的时滞阶数,即该模型自变量对应的时滞阶数;c0表示预设的第一常数;ε
t
表示预设的第二常数。第一常数和第二常数都可以是经验值或者实验值。
[0094]
为了排除模型自变量自身的变化,在该单回归模型中引入y
t
的一阶自回归项y
t-1
。因此,第i个来源地区对应的自回归模型可以表示为如下公式:
[0095][0096]
其中,β1表示第三常数。第三常数可以为经验值或者实验值。
[0097]
下面对如何使用来源地区对应的单回归模型和自回归模型来筛选候选历史迁移信息进行描述。
[0098]
图4为根据本发明一实施例的筛选候选历史迁移信息的具体步骤流程图。
[0099]
步骤s410,确定模型自变量对应的来源地区。
[0100]
步骤s420,将所述模型自变量输入所述来源地区对应的单回归模型和自回归模型中。
[0101]
步骤s430,分别对所述单回归模型和所述自回归模型执行预设的显著性检验。
[0102]
该显著性检验可以是t检验。
[0103]
由于事件信息的波动性可能很大,而c0的显著性通常较低,所以在本实施例中主要参考ci的显著性。可以对单回归模型中的ci进行t检验,得到第一检验值;对自回归模型中的ci进行t检验,得到第二检验值;该第一检验值和第二检验值都为p值;如果第一检验值小于预设的第一检验阈值,则判定单回归模型通过显著性检验;如果第二检验值小于预设的第二检验阈值,则判定自回归模型通过显著性检验。
[0104]
第一检验阈值和第二检验阈值都可以是经验值或者实验值。例如:第一检验阈值和第二检验阈值都设置为0.005。
[0105]
步骤s440,在所述单变量回归模型和所述自回归模型都通过所述显著性检验的情况下,确定所述单回归模型对应的拟合度。
[0106]
该拟合度为单回归模型的调整r2。
[0107]
步骤s450,在所述单变量回归模型对应的拟合度处于预设拟合度区间的情况下,将所述模型自变量确定为符合预设模型回归条件的历史迁移信息。
[0108]
在一些场景之中,事件成因和事件结果可能存在时间差,所以,可以针对与事件信息的相关系数最大的历史迁移信息,确定历史迁移信息对应的第一时间长度与事件信息对应的第二时间长度之间的时间差。
[0109]
针对所述与事件信息的相关系数最大的历史迁移信息,确定所述历史迁移信息对应的第一时间长度的起始时间以及所述事件信息对应的第二时间长度的起始时间,将所述第一时间长度的起始时间和所述第二时间长度的起始时间的差值,作为所述历史迁移信息对应的时滞阶数;或者,针对所述与事件信息的相关系数最大的历史迁移信息,确定所述历史迁移信息对应的第一时间长度的结束时间以及所述事件信息对应的第二时间长度的结束时间,将所述第一时间长度的结束时间和所述第二时间长度的结束时间的差值,作为所述历史迁移信息对应的时滞阶数。
[0110]
例如:由于外地进城人流对河流环境的影响不是立即发生,各来源地区的进城人流数对河流环境污染指数的影响可能有时间滞后性,具体时滞阶数受水流速度、人流量等因素影响。时滞阶数p是事件信息y
t
与历史迁移信息x
i,t-p
的时差。如图5所示,为历史迁移信息与河流污染信息的时差相关分析结果的示意图。图5第一列为时滞阶数,第一行除第一个单元之外都为省份,其余部分表示事件信息y
t
与历史迁移信息x
i,t-p
的相关系数。从图5中可以看出,大部分省份在时滞阶数为5时,与事件信息y
t
与历史迁移信息x
i,t-p
的相关系数最高。
[0111]
下面对生成样本迁移信息的步骤进行进一步地描述。如图6所示,为根据本发明一实施例的样本迁移信息的生成步骤流程图。
[0112]
步骤s610,在符合预设回归条件的候选历史迁移信息中,确定时滞阶数相同的所述候选历史迁移信息。
[0113]
在多个来源地区分别对应的符合预设回归条件的候选历史迁移信息中,确定时滞阶数相同的所述候选历史迁移信息。
[0114]
如果事件预测模型只考虑一个来源地区的历史迁移信息,那么事件预测模型是不够稳健的,所以,本实施例将不同来源地区的时滞阶数相同的候选历史迁移信息进行组合相加,使得新得到的迁移信息结合不同来源地区的迁移特点,信息更全面,得到的事件预测模型更稳健。
[0115]
步骤s620,在时滞阶数相同的所述候选历史迁移信息中,确定至少一组候选历史迁移信息的组合。
[0116]
在本实施例中,每个组合中的候选历史迁移信息至少对应一个来源地区。
[0117]
如果时滞阶数相同的候选历史迁移信息对应了n个来源地区,则在组合后续历史迁移信息时,将会有2
n-1种组合方式。例如:15个时滞阶数相同的候选历史迁移信息可以组成32767个组合。
[0118]
步骤s630,在属于同一组合的候选历史迁移信息中,将相同时间段对应的用户数量进行求和运算,生成所述组合对应的样本迁移信息。
[0119]
由于候选历史迁移信息为迁移序列,所以,可以将属于同一组合的候选历史迁移信息中对应元素位置的用户数据进行求和,得到该组合对应的样本迁移信息。
[0120]
如果事件预测模型只考虑一个来源地区的历史迁移信息,那么事件预测模型是不够稳健的,所以,本实施例将不同来源地区的时滞阶数相同的候选历史迁移信息进行组合相加,使得新得到的样本迁移信息考虑不同来源地区的用户流量,从而确定出的事件预测模型的预测准确度较高。
[0121]
下面对确定事件预测模型的步骤进行进一步地描述。如图7所示,为根据本发明一实施例的事件预测模型的确定步骤流程图。
[0122]
步骤s710,针对每个样本迁移信息,将所述样本迁移信息以及所述事件信息输入预设的初始预测模型,并确定所述初始预测模型的拟合度。
[0123]
每个样本迁移信息由至少一个来源地区对应的候选历史迁移信息生成的。
[0124]
初始预测模型为回归模型。该回归模型可以通过以下公式来表示:
[0125][0126]
步骤s720,将拟合度最大并且输入的样本迁移信息对应的来源地区最多的初始预测模型确定为事件预测模型。
[0127]
进一步地,可以将符合预设确定条件的初始预测模型确定为事件预测模型。该预设确定条件包括:该初始预测模型的拟合度大于第一确定阈值并且该初始预测模型的拟合度在所有初始预测模型中最大,输入该初始预测模型的样本迁移信息对应的来源地区的数量大于第二确定阈值并且在所有样本迁移信息中最多。
[0128]
在确定事件预测模型之后,可以采集目标迁移信息,将目标迁移信息输入该事件预测模型,获取该事件预测模型输出的事件信息。
[0129]
目标迁移信息可以是历史迁移信息、当前迁移信息或者未来迁移信息。
[0130]
历史迁移信息是指历史迁移信息对应的第一预设时间长对应的结束时间早于当前时间。对于事件成因和事件结果存在时差的场景,可以使用历史迁移信息来预测当前时间以及当前时间之后的事件信息。
[0131]
当前迁移信息是指当前时间包含于当前迁移信息对应的第一预设时间长对应时间区间中。使用当前迁移信息可以预测未来一段时间的事件信息。
[0132]
未来迁移信息是指未来迁移信息对应的第一预设时间长对应的开始时间晚于当前时间。使用未来迁移信息可以预测时间更加长远的事件信息。
[0133]
下面对如何预测未来迁移信息的步骤进行描述。
[0134]
图8为根据本发明一实施例的未来迁移信息的预测步骤流程图。
[0135]
步骤s810,获取历史迁移信息或者当前迁移信息。
[0136]
步骤s820,将所述历史迁移信息或者当前迁移信息输入预设的迁移走势预测模型,获取所述迁移走势预测模型输出的未来时间区间对应的未来迁移信息,将所述未来时间区间对应的未来迁移信息作为目标迁移信息。
[0137]
迁移走势预测模型,为预先训练的预测模型。
[0138]
在训练阶段,可以设置训练数据集,训练数据集中包括多个训练样本。每个训练样本为一个第一历史迁移信息。每个训练样本对应一个标注信息,该标注信息为该历史迁移信息对应的真实的第二历史迁移信息。第一历史迁移信息对应的第一预设时间长度的结束时间早于第二历史迁移信息对应的第一预设时间长度的起始时间,即第一历史迁移信息早于第二历史迁移信息。使用训练样本训练迁移走势预测模型,直到迁移走势预测模型收敛
为止。
[0139]
如图9所示,为根据本发明一实施例的未来迁移信息的预测示意图。图9中,y_true表示输入迁移走势预测模型的历史迁移信息或者当前迁移信息,y_predict表示迁移走势预测模型输出的未来迁移信息。
[0140]
本发明实施例还提供了一种事件预测模型的确定装置。如图10所示,为根据本发明一实施例的事件预测模型的确定装置的结构图。
[0141]
该事件预测模型的确定装置包括:获取模块1010,第一确定模块1020,筛选模块1030,生成模块1040和第二确定模块1050。
[0142]
获取模块1010,用于获取多个来源地区分别对应的历史迁移信息。
[0143]
第一确定模块1020,用于在每个所述来源地区对应的历史迁移信息中,确定与事件信息的相关系数最大的历史迁移信息,作为所述来源地区对应的候选历史迁移信息。
[0144]
筛选模块1030,用于根据所述事件信息以及预设的回归模型,在所述多个来源地区分别对应的候选历史迁移信息中,筛选出符合预设模型回归条件的候选历史迁移信息。
[0145]
生成模块1040,用于根据所述符合预设回归条件的候选历史迁移信息,生成样本迁移信息。
[0146]
第二确定模块1050,用于根据所述样本迁移信息以及所述事件信息,确定事件预测模型,以便利用目标迁移信息以及所述事件预测模型执行事件信息预测。
[0147]
本发明实施例所述的装置的功能已经在上述方法实施例中进行了描述,故本实施例的描述中未详尽之处,可以参见前述实施例中的相关说明,在此不做赘述。
[0148]
本实施例提供一种事件预测模型的确定设备。如图11所示,为根据本发明一实施例的事件预测模型的确定设备的结构图。
[0149]
在本实施例中,所述事件预测模型的确定设备,包括但不限于:处理器1110、存储器1120。
[0150]
所述处理器1110用于执行存储器1120中存储的事件预测模型的确定程序,以实现上述的事件预测模型的确定方法。
[0151]
具体而言,所述处理器1110用于执行存储器1120中存储的事件预测模型的确定程序,以实现以下步骤:获取多个来源地区分别对应的历史迁移信息;在每个所述来源地区对应的历史迁移信息中,确定与事件信息的相关系数最大的历史迁移信息,作为所述来源地区对应的候选历史迁移信息;根据所述事件信息以及预设的回归模型,在所述多个来源地区分别对应的候选历史迁移信息中,筛选出符合预设模型回归条件的候选历史迁移信息;根据所述符合预设回归条件的候选历史迁移信息,生成样本迁移信息;根据所述样本迁移信息以及所述事件信息,确定事件预测模型,以便利用目标迁移信息以及所述事件预测模型执行事件信息预测。
[0152]
其中,在所述获取多个来源地区分别对应的历史迁移信息之前,包括:多次执行采集聚合操作;其中,每次执行所述采集聚合操作包括:采集第一预设时间长度内的多个时间段分别对应的历史用户信息;其中,在每次执行采集聚合操作中,所述第一预设时间长度的起始时间不同;所述历史用户信息包括:进入所述目标地区的用户的来源地区;在所述第一预设时间长度内的多个时间段分别对应的历史用户信息中,聚合时间段相同并且来源地区相同的所述历史用户信息;根据聚合结果生成每个来源地区对应的历史迁移信息;其中,所
述历史迁移信息用于表示在所述第一预设时间长度的每个时间段内,从所述历史迁移信息对应的来源地区进入所述目标地区的用户数量。
[0153]
其中,在每个所述来源地区对应的历史迁移信息中,确定与事件信息的相关系数最大的历史迁移信息,作为所述来源地区对应的候选历史迁移信息,包括:获取第二预设时间长度内的多个时间段分别对应的目标事件数据并生成事件信息;所述第二预设时间长度与所述第一预设时间长度的时长相等;针对每个所述来源地区对应的多个历史迁移信息,计算所述事件信息分别与每个所述历史迁移信息的相关系数,并且确定与所述事件信息的相关系数最大的历史迁移信息,作为候选历史迁移信息。
[0154]
其中,在每个所述来源地区对应的历史迁移信息中,确定与事件信息的相关系数最大的历史迁移信息之后,还包括:针对所述与事件信息的相关系数最大的历史迁移信息,确定所述历史迁移信息对应的第一时间长度的起始时间以及所述事件信息对应的第二时间长度的起始时间,将所述第一时间长度的起始时间和所述第二时间长度的起始时间的差值,作为所述历史迁移信息对应的时滞阶数;或者,针对所述与事件信息的相关系数最大的历史迁移信息,确定所述历史迁移信息对应的第一时间长度的结束时间以及所述事件信息对应的第二时间长度的结束时间,将所述第一时间长度的结束时间和所述第二时间长度的结束时间的差值,作为所述历史迁移信息对应的时滞阶数。
[0155]
其中,根据所述符合预设回归条件的候选历史迁移信息,生成样本迁移信息,包括:在所述符合预设回归条件的候选历史迁移信息中,确定时滞阶数相同的所述候选历史迁移信息;在时滞阶数相同的所述候选历史迁移信息中,确定至少一组候选历史迁移信息的组合;每个组合中的候选历史迁移信息至少对应一个来源地区;在属于同一组合的候选历史迁移信息中,将相同时间段对应的用户数量进行求和运算,生成所述组合对应的样本迁移信息。
[0156]
其中,根据所述样本迁移信息以及所述事件信息,确定事件预测模型,包括:针对每个所述样本迁移信息,将所述样本迁移信息以及所述事件信息输入预设的初始预测模型,并确定所述初始预测模型的拟合度;其中,每个所述样本迁移信息由至少一个来源地区对应的候选历史迁移信息生成的;将拟合度最大并且输入的样本迁移信息对应的来源地区最多的初始预测模型确定为事件预测模型;其中,所述预设确定条件包括:所述初始预测模型的拟合度大于预设的第一确定阈值并且所述初始预测模型的拟合度在所有初始预测模型中最大,输入所述初始预测模型的样本迁移信息对应的来源地区的数量大于预设的第二确定阈值并且在所有样本迁移信息中最多。
[0157]
其中,根据所述事件信息以及预设的回归模型,在所述多个来源地区分别对应的候选历史迁移信息中,筛选出符合预设模型回归条件的候选历史迁移信息,包括:针对每个所述候选历史迁移信息,对所述候选历史迁移信息进行预设平稳性检验以及预设的正态性检验,得到所述候选历史迁移信息对应的平稳指数以及分布类型;确定平稳指数处于预设平稳区间并且分布类型为正态分布的候选历史迁移信息作为模型自变量;将所述事件信息作为模型因变量输入到所述回归模型中;针对每个所述模型自变量,将所述模型自变量输入所述回归模型,确定所述回归模型的模型参数,在所述模型参数处于预设参数区间的情况下,将所述模型自变量确定为符合预设模型回归条件的候选历史迁移信息。
[0158]
其中,在将所述模型自变量输入所述回归模型之前,还包括:如果模型自变量的数
量小于预设的数量阈值,则在平稳指数未处于预设平稳区间或者分布类型不是正态分布的候选历史迁移信息中,对所述候选历史迁移信息中的部分信息进行所述平稳性检验以及所述正态性检验,得到所述部分信息对应的平稳指数以及分布类型;确定平稳指数处于预设平稳区间并且分布类型为正态分布的部分信息作为模型自变量。
[0159]
其中,所述回归模型包括:为每个所述来源地区对应设置的单回归模型和自回归模型;将所述模型自变量输入所述回归模型,确定所述回归模型的参数模型,在所述模型参数处于预设参数区间的情况下,将所述模型自变量确定为符合预设模型回归条件的候选历史迁移信息,包括:确定所述模型自变量对应的来源地区;将所述模型自变量输入所述来源地区对应的单回归模型和自回归模型中;分别对所述单回归模型和所述自回归模型执行预设的显著性检验;在所述单变量回归模型和所述自回归模型都通过所述显著性检验的情况下,确定所述单回归模型对应的拟合度;在所述单变量回归模型对应的拟合度处于预设拟合度区间的情况下,将所述模型自变量确定为符合预设模型回归条件的历史迁移信息。
[0160]
其中,在利用目标迁移信息以及所述事件预测模型执行事件信息预测之前,还包括:获取历史迁移信息或者当前迁移信息;将所述历史迁移信息或者当前迁移信息输入预设的迁移走势预测模型,获取所述迁移走势预测模型输出的未来时间区间对应的未来迁移信息,将所述未来时间区间对应的未来迁移信息作为目标迁移信息。
[0161]
本发明实施例还提供了一种计算机可读存储介质。这里的计算机可读存储介质存储有一个或者多个程序。其中,计算机可读存储介质可以包括易失性存储器,例如随机存取存储器;存储器也可以包括非易失性存储器,例如只读存储器、快闪存储器、硬盘或固态硬盘;存储器还可以包括上述种类的存储器的组合。
[0162]
当计算机可读存储介质中一个或者多个程序可被一个或者多个处理器执行,以实现上述的事件预测模型的确定方法。
[0163]
以上所述仅为本发明的实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。