1.本发明涉及一种数据处理方法,特别是涉及一种可视化数据叙事方法、介质及电子设备。
背景技术:
2.可视化数据叙事是以可视化的方式对一些列有意义连接的叙事片段进行展示的一种叙事形式。该叙事形式有利于用户对叙事内容的理解和记忆,因而在数据驱动的叙事过程中经常使用。然而,发明人在实际应用中发现,现有的可视化数据叙事都是通过人工方式生成的,而可视化数据叙事在生成过程中需要用户具备较好的数据分析、可视化以及脚本编写等能力,这对于普通用户来说很难完成。
技术实现要素:
3.鉴于以上所述现有技术的缺点,本发明的目的在于提供一种可视化数据叙事方法、介质及电子设备,用于解决现有技术中可视化数据叙事都是通过人工方式生成的问题。
4.为实现上述目的及其他相关目的,本发明的第一方面提供一种可视化数据叙事方法;所述可视化数据叙事方法包括:获取基础数据;根据所述基础数据获取一数据事实集合;所述数据事实集合中包含至少2个数据事实;获取所述数据事实集合中至少2个数据事实的重要性;获取所述数据事实集合中至少2个数据事实之间的关联;获取一起点数据事实;根据所述数据事实的重要性以及所述数据事实之间的关联对所述起点数据事实进行扩展,并生成可视化的数据叙事。
5.于所述第一方面的一实施例中,所述数据事实的定义字段包括但不限于:类型、子空间、分类维度、度量维度和/或焦点。
6.于所述第一方面的一实施例中,对所述起点数据事实进行扩展,并生成可视化的数据叙事的一种实现方法包括但不限于:生成所述起点数据事实的关联数据事实作为当前数据事实;对所述当前数据事实进行扩展,重复此步骤直到满足终止条件;其中,对所述当前数据事实进行扩展的一种实现方法包括但不限于:生成所述当前数据事实的文本描述及其可视化图表;将所述当前数据事实的文本描述及其可视化图表添加到所述可视化的数据叙事中;获取所述当前数据事实的关联数据事实,并将其作为新的当前数据事实。
7.于所述第一方面的一实施例中,获取所述当前数据事实的关联数据事实的一种实现方法包括但不限于:从所述数据事实集合中,获取至少2个与所述当前数据事实相关联的数据事实作为备选数据事实;获取所述备选数据事实的奖励值,并根据所述奖励值从所述备选数据事实中选取所述当前数据事实的关联数据事实。
8.于所述第一方面的一实施例中,获取所述备选数据事实的奖励值的一种实现方法包括:获取当前数据叙事;其中,所述当前数据叙事是指所述起点数据事实与所述备选数据事实之间的所有数据事实所构成的数据叙事;获取所述当前数据叙事的多样性、逻辑性和/或完整性;获取所述当前数据叙事包含的信息量;根据所述当前数据叙事的多样性、逻辑
性、完整性和/ 或所述当前数据叙事包含的信息量,获取所述备选数据事实的奖励值。
9.于所述第一方面的一实施例中,对所述当前数据事实进行扩展这一步骤的执行时间大于一时间阈值,或所述可视化的数据叙事满足特定的数据条件,或所述可视化的数据叙事满足特定的叙事条件。
10.于所述第一方面的一实施例中,所述可视化数据叙事方法还包括:根据所述数据事实的重要性确定所述数据事实的可视化图表在显示区域的尺寸,进而实现对所述可视化的数据叙事进行布局。
11.于所述第一方面的一实施例中,对所述可视化的数据叙事进行布局的一种实现方法包括但不限于:通过优化一目标函数以实现对所述可视化的数据叙事进行布局。
12.于所述第一方面的一实施例中,获取所述数据事实的重要性的一种实现方法包括但不限于:获取所述数据事实的显著性;获取所述数据事实包含的信息量;根据所述数据事实的显著性和所述数据事实包含的信息量,获取所述数据事实的重要性。
13.于所述第一方面的一实施例中,所述可视化数据叙事方法还包括:显示一编辑器界面;所述编辑器界面包括配置子界面、数据事实子界面和/或可视化子界面;其中,配置子界面用于提示用户输入所述基础数据和配置信息,数据事实子界面用于提示用户输入编辑指令,可视化子界面用于显示所述可视化的数据叙事。
14.本发明的第二方面提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被执行时实现第一方面所述的可视化数据叙事方法。
15.本发明的第三方面提供一种电子设备;所述电子设备包括:存储器,其上存储有计算机程序;处理器,与所述存储器通信相连,用于在调用所述计算机程序时实现第一方面所述的可视化数据叙事方法;显示器,与所述存储器和所述处理器通信相连,用于显示所述可视化数据叙事方法的gui交互界面。
16.如上所述,本发明所述可视化数据叙事方法、介质及电子设备的一个技术方案具有以下有益效果:
17.所述可视化数据叙事方法能够基于基础数据获取一数据事实集合,进而获取所述数据事实集合中至少2个数据事实的重要性及其之间的关联,在此基础上,所述可视化数据叙事根据所述数据事实的重要性以及所述数据事实之间的关联对所述起点数据事实进行扩展,并生成可视化的数据叙事。该过程可以通过相应电子设备实现,在实现过程中基本无需人工参与,因此,即便用户不具备数据分析、可视化和/或脚本编写方面的能力,也可以通过本发明所述可视化叙事方法生成期望的可视化数据叙事。
附图说明
18.图1显示为本发明所述可视化数据叙事方法于一具体实施例中的流程图。
19.图2显示为本发明所述可视化数据叙事方法于一具体实施例中步骤s15的流程图。
20.图3a显示为本发明所述可视化数据叙事方法于一具体实施例中步骤s16的流程图。
21.图3b显示为本发明所述可视化数据叙事方法于一具体实施例中步骤s162的流程图。
22.图3c~图3g显示为本发明所述可视化数据叙事方法于一具体实施例中获取的数
据事实的文本描述及其可视化图表的示例图。
23.图3h显示为本发明所述可视化数据叙事方法于一具体实施例中获取的可视化数据叙事的示例图。
24.图4显示为本发明所述可视化数据叙事方法于一具体实施例中获取关联数据事实的流程图。
25.图5显示为本发明所述可视化数据叙事方法于一具体实施例中步骤s42的流程图。
26.图6显示为本发明所述可视化数据叙事方法于一具体实施例中获取数据事实的重要性的流程图。
27.图7a~7c显示为本发明所述可视化数据叙事方法于一具体实施例中采用的布局方案示例图。
28.图8显示为本发明所述电子设备于一具体实施例中的结构示意图。
29.元件标号说明
30.800
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
电子设备
31.810
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
存储器
32.820
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
处理器
33.830
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
显示器
34.s11~s16
ꢀꢀꢀꢀꢀꢀ
步骤
35.s151~s153
ꢀꢀꢀꢀ
步骤
36.s161~s162
ꢀꢀꢀꢀ
步骤
37.s1621~s1623
ꢀꢀ
步骤
38.s41~s42
ꢀꢀꢀꢀꢀꢀ
步骤
39.s421~s424
ꢀꢀꢀꢀ
步骤
40.s61~s63
ꢀꢀꢀꢀꢀꢀ
步骤
具体实施方式
41.以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
42.需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,图示中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
43.现有的可视化数据叙事基本都是通过人工方式生成的,而可视化数据叙事在生成过程中需要用户具备较好的数据分析、可视化以及脚本编写等能力,这对于普通用户来说很难完成。针对这一问题,本发明提供一种可视化数据叙事方法。所述可视化数据叙事方法能够基于基础数据获取一数据事实集合,进而获取所述数据事实集合中至少2个数据事实的重要性及其之间的关联,在此基础上,所述可视化数据叙事根据所述数据事实的重要性
以及所述数据事实之间的关联对所述起点数据事实进行扩展,并生成可视化的数据叙事。该过程可以通过相应电子设备实现,在实现过程中基本无需人工参与,因此,即便用户不具备数据分析、可视化和/或脚本编写方面的能力,也可以通过本发明所述可视化叙事方法生成期望的可视化数据叙事。
44.请参阅图1,于本发明的一实施例中,所述可视化数据叙事方法包括:
45.s11,获取基础数据;其中,所述基础数据是指包含有信息的数据,可以由用户直接提供,也可以由电子设备从文本、图片、音频、视频等多种形式的文件中自动提取。广义来讲,所有包含有信息的数据均可以作为所述基础数据;优选地,所述基础数据仅包含与用户感兴趣的数据叙事相关的数据,因而基于所述基础数据获取的数据事实也为用户感兴趣的数据事实。特别地,所述基础数据可以通过表格形式进行记录,例如,用表格的每一行记录一个基础数据,此时,根据该表格的总行数即可获得所述基础数据的总数。
46.s12,根据所述基础数据获取一数据事实集合;所述数据事实集合中包含至少2个数据事实。其中,所述数据事实是生成所述可视化的数据叙事的基本单位,每个数据事实携带有至少一条完整的信息。具体应用中,可以通过对所述基础数据进行提取、组合和/或编辑等操作获取所述数据事实。例如,当所述基础数据为一段视频时,可以将该视频划分成多个有意义的视频片段,通过提取各视频片段所包含的信息即可生成相应的数据事实。再例如,在关于汽车销量的数据叙事中,本实施例获取的一个数据事实为“suv和mpv在销量上存在 6764065的差异”;获取的另一个数据事实为“汽车总销量逐年降低”。
47.s13,获取所述数据事实集合中至少2个数据事实的重要性。所述数据事实的重要性用于描述所述数据事实相对于数据叙事的重要程度,且数据事实的重要性与数据叙事的叙事能力有关。所述数据事实的重要性可以根据实际需求进行定义,例如:可以定义所述重要性与数据事实包含的信息量正相关,此时,所述数据事实的重要性越高则所述数据事实包含的信息量越大;也可以定义所述重要性与用户的感兴趣程度成正比,此时,所述数据事实的重要性越高则所述数据事实包含的内容越容易被用户所接受。
48.s14,获取所述数据事实集合中至少2个数据事实之间的关联,其中,所述数据事实之间的关联与所述数据叙事的逻辑性有关。具体地,两个数据事实之间的关联越强,则二者之间的逻辑性越强,越有利于用户对这两个数据事实的理解和记忆。
49.s15,获取一起点数据事实。其中,所述起点数据事实为所述可视化的数据叙事的起点。例如,所述起点数据事实可以根据所述数据事实的重要性从所述数据事实集合中选取,也可以随机生成。
50.s16,根据所述数据事实的重要性以及所述数据事实之间的关联对所述起点数据事实进行扩展,并生成可视化的数据叙事。所述可视化的数据叙事可以通过对数据叙事进行可视化实现,其中,数据叙事包括数据事实以及数据事实之间的关联,例如,最简单的数据叙事可以通过以下公式进行描述:s={f1,r1,...,f
n-1
,r
n-1
,fn};其中,fi为第i个数据事实,ri表示fi与其下一个数据事实之间的关联,f1为数据叙事s的起点数据事实,fn为数据叙事s的终点数据事实。
51.根据以上描述可知,本实施例所述可视化数据叙事方法能够基于基础数据获取一数据事实集合,进而获取所述数据事实集合中至少2个数据事实的重要性及其之间的关联,在此基础上,所述可视化数据叙事根据所述数据事实的重要性以及所述数据事实之间的关
联对所述起点数据事实进行扩展,并生成可视化的数据叙事。该过程可以通过相应电子设备实现,在实现过程中基本无需人工参与,因此,即便用户不具备数据分析、可视化和/或脚本编写方面的能力,也可以通过本发明所述可视化叙事方法生成期望的可视化数据叙事。。
52.于本发明的一实施例中,对于两个数据事实fi和f
i 1
,二者之间的关联例如可以为并列关联(rs)、时间关联(r
t
)、转折关联(rc)、因果关联(ra)、递进关联(re)或泛化关联 (rg)。
53.具体地,对于数据事实fi及其下一个数据事实f
i 1
,若二者在逻辑上彼此平行,且内容相互关联,则认为fi和f
i 1
存在并列关联。
54.对于数据事实fi及其下一个数据事实f
i 1
,所述时间关联用于表示fi和f
i 1
之间的先后关系或顺序关系。
55.对于数据事实fi及其下一个数据事实f
i 1
,所述转折关联用于表示fi和f
i 1
之间相反的逻辑关系。例如,fi为“销售一个产品的趋势增加”,f
i 1
为“另一个产品的趋势减少”,则fi和f
i 1
之间存在转折关联;再例如,fi为“一个产品的销售数量与它的价格成正相关”,f
i 1
为“对于另一种产品,其销售数量与它的价格成负相关”,则fi和f
i 1
之间存在转折关联。
56.对于数据事实fi及其下一个数据事实f
i 1
,所述因果关联用于表示fi和f
i 1
之间的因果关系。例如,若f
i 1
是由fi引起的,则fi和f
i 1
之间存在因果关联。
57.对于数据事实fi及其下一个数据事实f
i 1
,若f
i 1
是在fi的基础上增加了更多的详细信息得到的,则fi和f
i 1
之间存在递进关联。
58.对于数据事实fi及其下一个数据事实f
i 1
,若f
i 1
是在fi的基础上删除了部分信息得到的,则fi和f
i 1
之间存在泛化关联。可以看出,所述泛化关联与所述递进关联相反。
59.需要说明的是,以上仅示例性的列出了6种关联,实际应用中可以根据实际需求对所述关联进行修改,或增加新的关联。
60.于本发明的一实施例中,所述数据事实的定义字段包括但不限于类型(type)、子空间(subspace)、分类维度(breakdown)、度量维度(measure)和/或焦点(focus)。如表1 所示,显示为常见的几种数据事实对应的定义字段。其中,“*”表示相应定义字段下的所有数据,
“×”
表示该字段未定义。接下来将对这几种定义字段进行详细介绍。
61.所述子空间字段用于表示数据事实的数据范围,由一组数据过滤器通过以下形式进行定义:{{f1=v1},...,{fk=vk}},其中,fi和vi分别表示一个过滤器的类型及其取值。例如,f1表示车型,v1为suv,则该过滤器表示suv车;f2表示产地,v2为国产,则该过滤器表示国产车;此时,由{{f1=v1}}定义的子空间表示所有的suv,由{{f1=v1},{f2=v2}}定义的子空间为所有国产suv。默认的,所述子空间字段对应的数据范围为整个数据集。
62.所述分类维度是一组时间字段t或分类字段c,基于所述时间或分类字段,所述子空间字段对应的数据范围进一步被划分为至少2个分组。例如,若子空间由{{f1=v1}}定义,表示所有的suv;当所述分类维度为“生产年份”这一时间字段时,则该子空间被进一步划分为至少2个分组,其中每个分组对应“某一年份生产的suv”;当所述分类维度为“车辆型号”这一分类字段时,则该子空间被进一步划分为至少2个分组,其中每个分组对应“一种型号的suv”。
63.所述度量维度是一个数据字段,该数据字段的数量为n,其中n为任意数值。基于该数据字段,通过整合所述子空间字段对应的数据范围或所述分类维度对应的分组能够得到
一系列的统计数值,例如:数据和、平均值、最小值和/或最大值。例如,所述度量维度可以为“汽车销量”,通过对该度量维度进一步汇总能够得到“汽车总销量”、“汽车平均年销量”等统计数值。
64.所述焦点字段用于指示所述子空间字段对应的数据范围中一个或多个需要特别关注的数据项,该数据项即为所述数据事实的焦点。
65.尽管本实施例仅定义了上述5种字段,某些数据事实也可能具有派生值字段。例如,当数据事实为“趋势”类型时,其派生值字段包括“上升”或“下降”;当数据事实为“差值”类型时,其派生值字段包括两个特定数值之间的差值;当数据事实为“关联”类型时,其派生值字段包括相关系数。所述派生值字段有助于帮助用户进一步了解所述数据事实。
66.接下来将用1个数据事实的实例来说明上述5种定义字段。第一个数据事实为{分布(类型),suv车型(子空间),品牌(分类维度),销量(度量维度),宝马(焦点)},该数据事实表示:不同品牌的suv车辆的销量分布情况,其中宝马需要重点关注。
67.本实施例通过将所述数据事实的字段配置为类型、子空间、分类维度、度量维度和/或焦点,使得所述数据事实的格式更加规范,有利于所述电子设备快速高效地对所述数据事实进行处理,从而提升所述可视化的数据叙事的生成速度。
68.表1常见的数据事实字段
[0069][0070]
请参阅图2,于本发明的一实施例中,获取所述起点数据事实的一种实现方法例如为:
[0071]
s151,获取不同类型的数据事实用作起点数据事实的频率,其中,该频率可以通过统计现有的数据叙事获得。
[0072]
s152,根据所述频率随机获取至少2个数据事实;其中,可以通过随机选取的方式从所述数据事实集合中获取至少2个数据事实。优选地,获取的数据事实均与用户感兴趣的叙事内容相关。例如,在上述10种类型的数据事实中,若“数值”类型的数据事实用作起点数据事实的频率最高,且用户感兴趣的叙事内容为汽车销量,则本步骤随机获取至少2个与汽车销量相关的“数值”类型的数据事实。
[0073]
s153,从步骤s152获取的数据事实中,选取重要性最高的一个数据事实作为所述
起点数据事实。具体地,分别计算步骤s152获取的各数据事实的重要性,从中选取重要性最高的一个数据事实作为所述起点数据事实。需要说明的是,选取重要性最高的一个数据事实作为所述起点数据事实仅为本实施例的优选实施方案,用户也可以根据实际需求选取其他数据事实作为所述起点数据事实,此处不做限制。
[0074]
请参阅图3a和3b,于本发明的一实施例中,对所述起点数据事实进行扩展,并生成可视化的数据叙事的一种实现方法例如为:
[0075]
s161,生成所述起点数据事实的关联数据事实作为当前数据事实。例如,可以根据所述数据事实集合中至少2个数据事实之间的关联,从所述数据事实集合中获取至少2个与所述起点数据事实相关联的数据事实作为所述起点数据事实的关联数据事实。
[0076]
s162,对所述当前数据事实进行扩展,重复此步骤直到满足终止条件。
[0077]
本实施例中,对所述当前数据事实进行扩展的实现方法例如为:
[0078]
s1621,生成所述当前数据事实的文本描述及其可视化图表。具体地,根据所述当前数据事实的类型选择一种图表,并将所述当前数据事实中的数据以该图表的形式进行显示,即可获得当前数据事实的可视化图表。所述图表例如为柱状图、折线图、对照图等,此处不作限制。具体应用中,可以通过统计现有可视化数据叙事中各种类型的数据事实所采用的图表类型的频率来选取所述图表。
[0079]
s1622,将所述当前数据事实的文本描述及其可视化图表添加到所述可视化的数据叙事中。具体地,通过将所述可视化图表、所述文字描述按照相应的顺序进行排列,即可获得所述可视化的数据叙事。其中,所述排列顺序由备选数据事实之间的关联决定。
[0080]
s1623,获取所述当前数据事实的关联数据事实,并将其作为新的当前数据事实。
[0081]
请参阅图3c~图3g,显示为本实施例中获取的至少2个数据事实的文本描述及其可视化图表。图3h显示为本实施例生成的一个可视化的数据叙事的示例图。
[0082]
于本发明的一实施例中,所述当前数据事实的文本描述可以根据预设语法生成。接下来将对不同类型的数据事实相应的预设语法进行介绍,其中,si为子空间,bi为分类维度,mi为度量维度,xi为焦点,vd为派生值,相应取值参见表1;agg(mi)表示对度量维度mi的整合,例如:总数、求和、平均值、最大值、最小值等。
[0083]
当数据事实的类型为“数值”时,相应的预设语法为:在si范围内,agg(mi)的数值是vd。
[0084]
当数据事实的类型为“差值”时,相应的预设语法为:在si范围内,x1和x2在agg(mi) 上的差值是vd;其中,x1和x2分别为2个焦点字段指定的焦点。例如,在中国,宝马和奥迪在总销量上的差值为vd。
[0085]
当数据事实的类型为“占比”时,相应的预设语法为:在si范围内,xi在agg(mi)中所占的百分比为vd。
[0086]
当数据事实的类型为“趋势”时,相应的预设语法为:在si范围内,agg(mi)在bi(si)上呈现vd趋势,且xi需要重点关注。
[0087]
当数据事实的类型为“分类”时,相应的预设语法为:在si范围内,有vd种bi,分别包括{c1,c2,
…
,cn},且xi需要重点关注。其中,{c1,c2,
…
,cn}为预设的分类条件。
[0088]
当数据事实的类型为“分布”时,相应的预设语法为:在si范围内,agg(mi)在bi(si)上的分布,且xi需要重点关注。
[0089]
当数据事实的类型为“排名”时,相应的预设语法为:通过在si范围内对不同的bi(si) 进行agg(mi)的排名,排名最高的三个bi(si)是x0、x1和x2。
[0090]
当数据事实的类型为“关联”时,相应的预设语法为:在si范围内,mi[1]和mi[2]之间的相关系数为vd。其中,mi[1]和mi[2]分别为数据事实中的两个度量维度。
[0091]
当数据事实的类型为“极值”时,相应的预设语法为:在si范围内,agg(mi)上的vd值为xi。
[0092]
当数据事实的类型为“异常”时,相应的预设语法为:在si范围内,与bi(si)中的其他数据相比,xi的agg(mi)为一异常值。
[0093]
需要说明的是,本实施例仅示例性的给出了文本描述的生成方法,具体应用中也可以根据需求采用其他方式生成所述数据事实的文本描述。
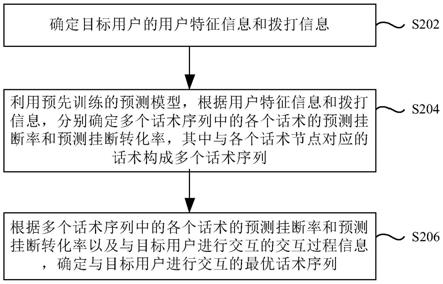
[0094]
请参阅图4,于本发明的一实施例中,获取所述当前数据事实的关联数据事实的一种实现方法例如为:
[0095]
s41,从所述数据事实集合中,获取至少2个与所述当前数据事实相关联的备选数据事实。例如,可以选取所述数据事实集合中,与所述当前数据事实相关联的至少2个数据事实作为所述备选数据事实。
[0096]
s42,获取所述备选数据事实的奖励值,并根据所述奖励值从所述备选数据事实中选取所述当前数据事实的关联数据事实。例如,可以从所述备选数据事实中选取奖励值最高的数据事实作为所述当前数据事实的关联数据事实。所述数据事实的奖励值的计算方法可以通过常用的奖励值计算方法实现,也可以由用户根据经验预先设定,具体获取方式本实施例不做限制。
[0097]
需要说明的是,所述起点数据事实的关联数据事实的生成方式与s41~s42类似,此处不作赘述。
[0098]
请参阅图5,于本发明的一实施例中,对于任意一个备选数据事实,获取所述备选数据事实的奖励值的一种实现方法例如为:
[0099]
s421,获取当前数据叙事。其中,所述当前数据叙事是指所述起点数据事实到所述备选数据事实的路径上的所有数据事实所构成的数据叙事。如前所述,数据叙事可以通过数据事实及其之间的关联进行描述,因此,当前数据叙事si可以表示为{f0,r0,f1,...,f
i-1
,r
i-1
,fi},其中,所述起点数据事实f0到所述备选数据事实fi的路径上的所有数据事实为f1,f2,
…
,f
i-1
。
[0100]
s422,获取所述当前数据叙事的多样性、逻辑性和/或完整性。
[0101]
s423,获取所述当前数据叙事包含的信息量。
[0102]
s424,根据所述当前数据叙事的多样性、逻辑性、完整性和/或所述当前数据叙事包含的信息量,获取所述备选数据事实的奖励值。由此可知,所述备选数据事实的奖励值由所述当前数据叙事的多样性、逻辑性、完整性和所述当前数据叙事包含的信息量中的一个或者至少 2个参数决定。
[0103]
接下来将以备选数据事实fi及其对应的当前数据叙事si为例,对上述过程进行详细介绍。具体地,所述备选数据事实fi的奖励值reward(si)的一种计算方法例如为: reward(si)={γ1×
d(si) γ2×
l(si) γ3×
c(si)}
×
h(si);其中,si为起点数据事实f0、所述数据事实fi以及二者之间的所有数据事实构成的当前数据叙事,γ1、γ2和γ3分别为三个权重
值, d(si)表示当前数据叙事si的多样性,l(si)表示所述当前数据叙事si的逻辑性,c(si)表示所述当前数据叙事si的完整性,h(si)为所述当前数据叙事si所包含的信息量。需要说明的是,所述奖励值的计算方法并不唯一,上述公式仅示例性的说明了一种计算方法,具体应用中可以根据实际需求选取其他的方式计算所述奖励值。
[0104]
本实施例中,γ1、γ2和γ3分别为三个权重值,用于平衡当前数据叙事si的多样性、逻辑性和完整性,用户可以通过调整相应权重值的比例来获取期望的数据叙事。其中,γ1、γ2和γ3的数据范围均为0~1之间的任意数,且三者之和为1。特别地,当γi取0时,表示在所述奖励值的计算过程中不考虑γi对应的因素,例如:若γ1=0,则所述奖励值仅与所述当前数据叙事包含的信息量、所述当前数据叙事的逻辑性和所述当前数据叙事的完整性有关。
[0105]
h(si)为所述当前数据叙事si所包含的信息量,在本实施例中用作所述奖励值计算的基础。具体地,其中,is(fi)为所述备选数据事实fi的重要性;p(fi)表示备选数据事实fi发生的概率。
[0106]
d(si)表示所述当前数据叙事si的多样性,丰富的多样性能够使得当前数据叙事si更加生动和吸引人。d(si)的计算公式例如为:其中,n表示在当前数据叙事si生成过程中使用的数据事实的类型的数量,其最大值为10;pi表示第i种类型的数据事实在所述当前数据叙事si中所占的比例。在上述公式中,min(|si|,10)表示|si|和 10之间的较小值,用于激励在生成所述当前数据叙事si的过程中使用更多类型的数据事实,其中,|si|为所述当前数据叙事si的长度,用于激励在生成所述当前数据叙事si的过程中均匀的使用不同类型的数据事实。因此,d(si)能够充分反映所述当前数据叙事si的多样性,且d(si)越大则所述当前数据叙事si的多样性越丰富。
[0107]
l(si)表示所述当前数据叙事si的逻辑性,更高的逻辑性意味着当前数据叙事si更加有条理且更容易阅读。逻辑性被定义为关联ri之间的平均似然值,其中ri表示每个数据事实fi与其下一个数据事实f
i 1
之间的关联。l(si)的一种计算方法例如为在该公式中,p(ri|fi)表示备选数据事实fi与其下一个数据事实f
i 1
之间的关联为ri的概率,其值可以通过对现有的数据叙事进行统计获得。例如,若fi为“数值”类型的数据事实,ri为因果关联,经统计多个现有的数据叙事获取的“数值”类型的数据事实的数量为a,其中,有b 个“数值”类型的数据事实与其下一个数据事实之间存在因果关联,则p(ri|fi)=b/a。
[0108]
c(si)表示所述当前数据叙事si的完整性,完整性越强表示当前数据叙事si更能代
表所述基础数据。c(si)的一种计算方式例如为:其中,分子表示在所述当前数据叙事si的生成过程中用到的基础数据的数量,n表示所述基础数据的总数。特别地,当所述基础数据以表格形式进行记录时,通过统计表格内相应行的数量即可获得该分子和分母。
[0109]
需要说明的是,上述计算方法得到的奖励值reward(si),不仅可以用来获取备选数据事实fi的奖励值,还可以对所述当前数据叙事si进行评价。此外,所述多样性、逻辑性、完整性和所述信息量的计算方法并不唯一,上述公式仅示例性的说明了一种计算方法,具体应用中可以根据实际需求选取其他的方式进行计算。
[0110]
于本发明的一实施例中,所述终止条件包括:对所述当前数据事实进行扩展这一步骤的执行时间大于一时间阈值,或所述可视化的数据叙事满足特定的数据条件,或所述可视化的数据叙事满足特定的叙事条件。其中,所述特定的数据条件例如为所述可视化的数据叙事包含的可视化图表的数量达到一阈值,所述特定的叙事条件例如为述可视化的数据叙事包含的信息量达到一阈值。
[0111]
于本发明的一实施例中,所述可视化数据叙事方法还包括:根据所述数据事实的重要性确定所述数据事实的可视化图表在显示区域的尺寸,进而实现对所述可视化的数据叙事进行布局。
[0112]
具体地,所述可视化数据叙事方法应用的电子设备包括:笔记本电脑/掌上电脑、智能手机以及打印设备。其中,所述笔记本电脑/掌上电脑的显示区域相对较大,因此,对所述可视化的数据叙事进行布局时可以采用故事线模式进行布局,所述故事线模式例如图3h所示的可视化的数据叙事。智能手机的显示区域相对较小,在对所述可视化的数据叙事进行布局时,优选为每次为用户呈现一幅数据事实的可视化图表,用户可以通过滑动手机等方式切换需要显示的数据事实的可视化图表。打印设备要考虑输出页面的尺寸以及打印效果,因此,对打印设备需要根据输出页面的尺寸单独设计布局方式以显示所述可视化的数据叙事。
[0113]
在上述三种布局方式中,对所述可视化的数据叙事进行布局时需要充分考虑所述数据事实的重要性、所述数据事实的可视化图表的宽度、所述数据事实的可视化图表的高度和/或显示区域的尺寸来实现对所述可视化的数据叙事进行布局,从而保证所述可视化的数据叙事的可视化效果和叙事效果。
[0114]
特别地,对于打印设备,于本发明的一实施例中,对所述可视化的数据叙事进行布局的实现方法包括但不限于:通过优化一目标函数以实现对所述可视化的数据叙事进行布局。所述目标函数例如为:其中,w(f
ij
)和h(f
ij
)分别表示第i行第j列的数据事实f
ij
的可视化图表的宽度和高度,in(f
ij
)为所述数据事实f
ij
归一化的重要性, a为所述显示区域的尺寸。对所述目标函数进行求解可以利用现有方法实现,例如:贪心算法,具体求解方法此处不做赘述。
[0115]
需要说明的是,上述目标函数仅为一个示例,具体应用中可以根据实际需求对该示例进行调整或创建其他的目标函数来实现对所述可视化的数据叙事的布局。
[0116]
请参阅图6,于本发明的一实施例中,获取所述数据事实的重要性的一种实现方法例如为:
[0117]
s61,获取所述数据事实的显著性;其中,所述显著性用于表示在当前事实类型下,所述数据事实在统计中的显著性水平,与所述数据事实的类型相关。
[0118]
s62,获取所述数据事实包含的信息量;其中,所述信息量表示该数据事实出现在当前数据中所产生的信息多少的量度,与所述数据事实发生的概率相关。
[0119]
s63,根据所述数据事实的显著性和所述数据事实包含的信息量,获取所述数据事实的重要性。
[0120]
具体地,所述数据事实的重要性的计算方法例如可以为:is(fi)=s(fi)
×
i(fi);其中,is(fi) 为数据事实fi的重要性;i(fi)表示所述数据事实fi所包含的信息量,且i(fi)与所述数据事实 fi发生的概率相关;s(fi)表示所述数据事实fi的显著性,且s(fi)与所述数据事实fi的类型相关。
[0121]
需要说明的是,所述数据事实的重要性的计算方法并不唯一,上述公式仅示例性的说明了一种重要性的计算方法,具体应用中可以根据实际需求选取其他的方式计算所述数据事实的重要性。
[0122]
具体地,i(fi)=-log2(p(fi))为所述数据事实fi的自信息,用于表示数据事实fi所包含的信息量,其单位为bit。
[0123]
p(fi)=p(mi|ti)
×
p(bi|ti)
×
p(si)
×
p(xi|si),表示数据事实fi发生的概率;其中,p(mi|ti) 表示类型为ti时度量维度为mi的概率,p(bi|ti)表示类型为ti时分类维度为bi的概率,p(xi|si) 表示子空间为si时焦点为xi的概率,上述三个概率值可以通过表1获得。例如,当数据事实的类型为“数值”时,p(mi|ti)=1/n,其中n为度量维度的所有可能取值;类似的,当数据事实的类型为“差值”时,p(bi|ti)=1/(c t),其中,c表示分类维度为分类字段时所有分组的数量,t表示分类维度为时间字段时所有分组的数量。此外, p(xi|si)=count(xi)/count(si),其中count(xi)表示焦点的数量,该数量由焦点字段决定; count(si)表示所述子空间字段对应的数据范围内所包含的数据项的总数。优选地,在用户未指定所述焦点字段时,所述子空间字段对应的数据范围内所包含的所有数据项均为焦点,即: p(xi|si)=1。
[0124]
p(si)表示使用过滤器{f1=v1,f2=v2,...,fk=vk}来定义所述子空间的概率。具体地,其中,c(m,i)为数学中的组合,即从m个数据中不重复的选取i个数据的组合,表示定义所述子空间的所有可能情况;因此,其中的第一项表示使用过滤器{f1=v1,f2=v2,...,fk=vk}来定义所述子空间仅仅是多种定义方式中的一种,其中的第二项表示使用v1,v2,...,vk作为不同过滤器取值的概率,该项可以直接由满足每个过滤条件的数据比例的乘积给出,即fj=vj。
[0125]
s(fi)表示所述数据事实fi的显著性,其数据范围为[0,1]。对于不同类型的数据事
实fi,其显著性的定义各不相同,实际应用中可以根据需求对所述显著性进行定义。例如,当所述数据事实fi的类型为“数值”时,所述显著性s(fi)为所述数据事实fi的概率p(fi)。又例如,当所述数据事实fi的类型为“差值”时,所述显著性s(fi)与两个焦点之间的差值有关,所述差值越大则所述显著性s(fi)越高,具体公式可以根据实际需求进行定义;特别地,当两个焦点之间的差值为最大值时,s(fi)=1。
[0126]
需要说明的是,所述信息量和/或所述显著性的计算方式并不唯一,具体应用中可以根据实际需求选取其他方式计算所述信息量is(fi)和所述显著性s(fi)。
[0127]
于本发明的一实施例中,所述可视化数据叙事方法还包括:显示一编辑器界面;所述编辑器界面包括配置子界面、数据事实子界面和/或可视化子界面;其中,配置子界面用于提示用户输入所述基础数据和配置信息,数据事实子界面用于提示用户输入编辑指令,可视化子界面用于显示所述可视化的数据叙事。
[0128]
请参阅图7a,显示为本实施例涉及的一个配置子界面示例,用户可以通过所述配置子界面上传基础数据、设置数据叙事的终止条件和/或调整奖励值的计算方法。请参阅图7b,显示为本实施例涉及的一个数据事实子界面的示例,在所述数据事实子界面,用户可以根据自己的喜好移除数据事实或者调整所述数据事实的叙事顺序。请参阅图7c,显示为本实施例涉及的一个可视化子界面,所述可视化子界面用于显示所述可视化的数据叙事。
[0129]
基于以上对所述可视化数据叙事方法的描述,本发明还提供一种计算机可读存储介质,其上存储有计算机程序。该计算机程序被执行时实现本发明所述的可视化数据叙事方法。
[0130]
基于以上对所述可视化数据叙事方法的描述,本发明还提供一种电子设备。请参阅图8,所述电子设备800包括:存储器810,其上存储有计算机程序;处理器820,与所述存储器810通信相连,用于在调用所述计算机程序时实现本发明所述可视化数据叙事方法;显示器 830,与所述存储器810和所述处理器820通信相连,用于显示所述可视化数据叙事方法的 gui交互界面。
[0131]
本发明所述的可视化数据叙事方法的保护范围不限于本实施例列举的步骤执行顺序,凡是根据本发明的原理所做的现有技术的步骤增减、步骤替换所实现的方案都包括在本发明的保护范围内。
[0132]
本发明所述可视化数据叙事方法能够基于基础数据获取一数据事实集合,进而获取所述数据事实集合中至少2个数据事实的重要性并获取备选数据事实,在此基础上,所述可视化数据叙事方法根据所述备选数据事实生成所述可视化的数据叙事。该过程可以通过相应电子设备实现,在实现过程中基本无需人工参与,因此,即便用户不具备数据分析、可视化和/或脚本编写方面的能力,也可以通过本发明所述可视化叙事方法生成期望的可视化数据叙事。
[0133]
综上所述,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
[0134]
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。