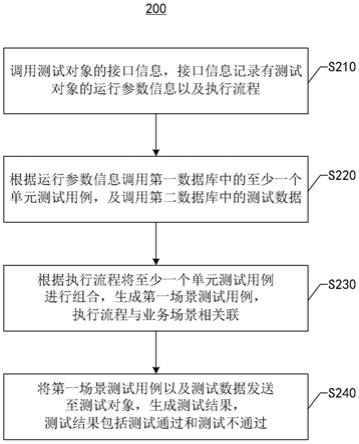
1.本发明涉及一种利用人工神经网络和支持向量回归模型预测风力发电方法。
背景技术:
2.风力发电的随机性使得风力发电在电力系统中所占份额的增加受到限制,并对风力发电的市场整合提出了挑战,这主要是因为如今新建的风电场需要应对更加动态的定价机制。在这个新环境中,先进的投标策略需要从风力发电参与者,引进新元素来支持风力发电和解决内在的变化影响被认为是一个先决条件。
3.储能就是这样一种新颖的元素,既可以支持更高的风能渗透率,又可以确保风电场在优化的运行条件和收益下的调度。另一方面,储能技术,主要是电池技术,直到现在才有了发展前景,可能会降低成本,从而可能使这个解决方案成本风能应用的更广泛的频谱,而不仅仅是一些利基市场方面的(如离网和岛电力系统占主导地位的石油发电建议增加操作成本,可以证明风力发电和能源存储的耦合。与此同时,在过去的几年里,对于利用人工智能(ai)和机器学习(ml)对能源部门各种类型的问题和应用进行高级预测技术的研究,包括风力发电预测,科学兴趣大幅增长。在这种背景下,预测技术的发展允许在联合风电储能方案中实施预测控制,有助于优化运行和降低成本,并支持开发有效的风电园区参与电力市场的投标策略。通过应用支持持续优化调度的不同时间间隔和预测范围,可以产生短期和长期预测,这些预测甚至可以有效地延长到未来一天。使用软能源应用实验室团队开发的内部软件工具,通过开发各种集成人工智能预测技术和算法,为预测应用量身定制,在当前工作中研究了风力发电预测的不同方面。更准确地说,通过使用现有风电厂的实际运行数据,我们首先应用人工神经网络(anns)对未来24小时内的风力发电进行个人预测。在评估两种单独技术的性能后,我们继续将它们结合起来,以创建一个集成模型,目的是通过聚类产生最优的预测结果,而不需要一直测试。
技术实现要素:
4.本发明的目的是提供一种利用人工神经网络和支持向量回归模型预测风力发电方法。
5.上述的目的通过以下的技术方案实现:一种利用人工神经网络和支持向量回归模型预测风力发电方法,该方法包括如下步骤:(1)处理和使用一个正在运行的风电场的实际数据,以便测试预测模型在风电场预测风力发电的水平;(2)使用预测软件工具,训练ann和svr模型,在非详尽训练的背景下,每小时考虑24小时前的预测范围;(3)利用典型的评估指标对案例进行评估,评估神经网络和支持向量回归模型的个体表现;
(4)通过聚类将神经网络与支持向量机结合,在非穷举模型训练的假设下得到最优的风电预测结果。
6.所述的利用人工神经网络和支持向量回归模型预测风力发电方法,该方法包括如下步骤:预测工具是一个基于encog ml框架的自动化ai平台,能够解决回归问题,如风力发电的预测,ml方法的可用范围仅限于两种ml方法;所采用的ml方法有支持向量机和神经网络,后者采用前馈或递归网络的形式。svr的主要思想是在所有训练模式中,寻找一个与实际训练目标ε偏差最大的函数f(x)。公差ε的范围设置为0.1;为了处理不存在函数的能力与精度ε,近似的所有训练对svr模型适应软边缘损失函数概念通过使用松弛变量的约束优化问题;此外,在目标函数中引入了常数c,以惩罚那些松弛变量的使用。常数c是hyperparameter影响函数f (x),其价值受制于试验使用对数步骤和适当的值是高度依赖于训练模式的训练集,以防分离在n维空间非线性的方法,而不是找一个更高的学位曲线,一个可能会增加n .这是由于这一事实制定只需要测试数据的点积,因此n,甚至一个转换函数,都是多余的。为此,可以用核函数直接代替点积;在开发的工具中,使用径向基函数核,或高斯核:其中x(测试向量)和x'(支持向量)是要投射到新的向量空间中的向量,而是超参数,表示所选支持向量的影响半径的倒数;对于anns来说,前馈网络和递归网络的主要区别在于,前者允许信息从输入到输出,而后者则允许信息双向传播。后者是通过一个额外的神经元层来实现的,称为上下文层,它存储隐藏单元的值。上下文层的内容在下一阶段的输入中反馈到隐含层,为网络提供“记忆”。
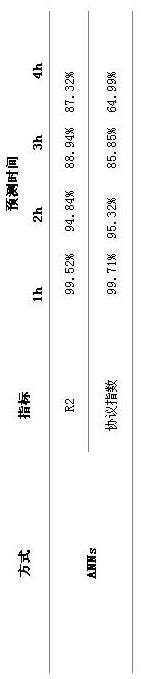
7.本发明的有益效果:1.本发明anns和svr模型在不同预测范围的基础上进行了测试,并使用运行的一个风电厂的实际风速和风力发电测量数据作为案例研究。模型使用内部预测工具进行测试,得到的结果反映了svr方法的整体较好拟合,特别是对于时间跨度超过6小时的预测。同时,努力优化风力发电的预测的组合预测方法,通过聚类预测领域,让预测的方法得到了改进,而且 svr方法已经足够甚至24小时使用。
8.2.本发明由于所应用的模型在预测发电峰值和最小值方面表现得更好,支持向量回归法的应用被证明是更有效的。然而,在一定的发电区域内,即使svr的性能总体上优于anns,但anns和svr的组合结果(集合模型)似乎是最好的方法。一个例子是如下图所示,通过集群介绍了两种方法的结合,即在1500千瓦和3800千瓦之间的平均预测使用。最后,随着预测地平线的增加,人工神经网络提供更准确的预测风力发电。另一方面,即使对于前一天的预测,一个良好调整的svr似乎也能给出非常满意的结果(99.60%的r2, 98.99%的一致性指数和334kw的平均绝对误差)。
9.附图说明:附图1是本发明的anns对不同预测视域的预测精度图。
10.附图2是本发明的anns预测结果展示图。
11.附图3是本发明测试方法3小时的预测精度图。
12.具体实施方式:实施例1:预测工具是一个基于encog ml框架的自动化ai平台,能够解决回归问题,如风力发电的预测。ml方法的可用范围仅限于两种ml方法(anns和svr),而对于模型的超参数优化,可以执行随机搜索或网格搜索。网格搜索指的是循环使用固定的参数值集(在用户界面中定义)。随机搜索是指根据之前一次试验的结果更新参数值。在这种情况下,可以使用不同的特征预测组合作为输入,以形成一组“数据”案例,这些数据案例也会根据期望的预测范围(长度和步长)自动扩展。测试和验证分区以及每个特性的历史数据(反向数据)。同样,对于每一个“数据”案例,该工具都会根据用户界面上定义的偏好生成一组“模型”案例。通过这种方式,可以探索不同ml方法的性能以及所涉及的每个超参数的影响。
13.实施例2:所采用的ml方法有支持向量机(svr)和神经网络(ann),后者采用前馈或递归网络的形式。svr的主要思想是在所有训练模式[23]中,寻找一个与实际训练目标ε偏差最大的函数f(x)。公差ε的范围设置为0.1。为了处理不存在函数的能力与精度ε,近似的所有训练对svr模型适应“软边缘”损失函数概念通过使用松弛变量的约束优化问题(即寻找一个超平面,将数据之间的距离最大化支持向量和超平面)。此外,在目标函数中引入了常数c,以惩罚那些松弛变量的使用。常数c是hyperparameter影响函数f (x),其价值受制于试验使用对数步骤和适当的值是高度依赖于训练模式的训练集,以防分离在n维空间非线性的方法,而不是找一个更高的学位曲线,一个可能会增加n .这是由于这一事实制定只需要测试数据的点积,因此n,甚至一个转换函数,都是多余的。为此,可以用核函数直接代替点积。在开发的工具中,使用径向基函数核,或高斯核:其中x(测试向量)和x'(支持向量)是要投射到新的向量空间中的向量,而是超参数,表示所选支持向量的影响半径的倒数。
[0014]
对于anns来说,前馈网络和递归网络(在我们的例子中是elman网络)的主要区别在于,前者允许信息从输入到输出,而后者则允许信息双向传播。后者是通过一个额外的神经元层来实现的,称为上下文层,它存储隐藏单元的值。上下文层的内容在下一阶段的输入中反馈到隐含层,为网络提供“记忆”。
[0015]
案例研究和训练数据集为了应用所描述的方法和sealab的内部预测工具。研究的风场总共使用了10台750千瓦的风力涡轮机。一个近2.5年运行的详细数据集已经提供,包括所有10个风力涡轮机的实际风能生产的测量,以及风速和枢纽高度的风向。为此,下图提供了一个具有代表性的风速和风力发电测量样本,估计风场长期平均风速为~9.3m/s,导致平均容量因子超过38%。
[0016]
对特定的测量集进行处理,从而产生一个干净的数据集,用于训练所使用的不同预测模型。如前所述,测试了不同的预测范围,即提前1到24小时,而对模型的训练使用了41个特征和60.000条记录。这些是登记到每个风力涡轮机的测量(即风速,风向,发电量,环境温度)和一个时间指示器。
[0017]
对于使用ml方法进行风力发电预测,正如所料,模型的性能随着预测范围的增大
而逐渐衰减。为此,在当前的案例研究中,发现elman模型足够准确,直到6小时,结果提前24小时是由87%和索引的r2协议等于65%,这大大提高了与之前相比,类似的研究中,基于人工神经网络的使用。生成的预测结果如下图所示,分别以时间序列(静态和移动)的形式呈现,可以将预测结果与原始风电输出值(地面真实值)进行直接比较。
[0018]
同时,由于所应用的模型在预测发电峰值和最小值方面表现得更好,支持向量回归法的应用被证明是更有效的。然而,在一定的发电区域内,即使svr的性能总体上优于anns,但anns和svr的组合结果(集合模型)似乎是最好的方法。一个例子是如下图所示,通过集群介绍了两种方法的结合,即在1500千瓦和3800千瓦之间的平均预测使用。最后,随着预测地平线的增加,人工神经网络提供更准确的预测风力发电。另一方面,即使对于前一天的预测,一个良好调整的svr似乎也能给出非常满意的结果(99.60%的r2, 98.99%的一致性指数和334kw的平均绝对误差)。
[0019]
实施例3:案例研究和训练数据集:为了应用所描述的方法和sealab的内部预测工具。研究的风场总共使用了10台750千瓦的风力涡轮机。一个近2.5年运行的详细数据集已经提供,包括所有10个风力涡轮机的实际风能生产的测量,以及风速和枢纽高度的风向。为此,下图提供了一个具有代表性的风速和风力发电测量样本,估计风场长期平均风速为~9.3m/s,导致平均容量因子超过38%。
[0020]
对特定的测量集进行处理,从而产生一个干净的数据集,用于训练所使用的不同预测模型。如前所述,测试了不同的预测范围,即提前1到24小时,而对模型的训练使用了41个特征和60.000条记录。这些是登记到每个风力涡轮机的测量(即风速,风向,发电量,环境温度)和一个时间指示器。
[0021]
对于使用ml方法进行风力发电预测,正如所料,模型的性能随着预测范围的增大而逐渐衰减。为此,在当前的案例研究中,发现elman模型足够准确,直到6小时,结果提前24小时是由87%和索引的r2协议等于65%,这大大提高了与之前相比,类似的研究中,基于人工神经网络的使用。生成的预测结果如下图所示,分别以时间序列(静态和移动)的形式呈现,可以将预测结果与原始风电输出值(地面真实值)进行直接比较。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。