技术特征:
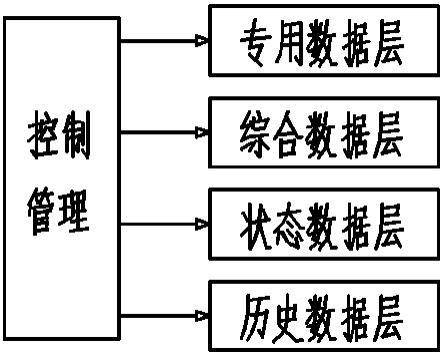
1.一种基于大数据技术的业扩报装档案挖掘分析方法,包括业扩报装档案数据仓库的建立和业扩报装档案数据挖掘处理方法;其特征是:在建立业扩报装档案数据仓库的基础上,利用组合预测模型对业扩报装数据进行处理;在利用遗传算法对k均值聚类进行改进后,进行数据挖掘以获取归档数据之间的关系。2.根据权利要求1所述的一种基于大数据技术的业扩报装档案挖掘分析方法,其特征是:所述业扩报装档案数据仓库采用维表法建立,由状态数据层、历史数据层、综合数据层、专用数据层和控制管理组成;所述状态数据层,存储最新的详细数据,当数据从外部进入数据仓库时,首先将其直接放入该层;它可以由通用数据库进行处理,这类数据也称为系统的基础数据;所述历史数据层,决策存储在历史数据层和综合数据层所需的信息是基础数据反映的总体趋势或随时间变化的趋势,对基础数据进行分类、分解、汇总和处理,以获取信息;基础数据在时间控制机制下生成历史数据,并将其放入历史数据层,供当前数据层、综合数据层和专题数据层调用;所述综合数据层,在综合机制下,对基础数据进行整合提取,生成综合数据,并将其放入综合数据层,包括各种统计数据、指标、评价计算结果、预测分析数据;所述专用数据层,存储行业的扩展数据,即通过存储数据分析技术对基础数据进行处理形成的特殊数据;所述控制管理,除上述四个数据层外,决策支持还需要使用电力业务部门的外部数据,这些数据共同构成数据仓库的信息源;在控制管理中,通过建立提取器,将来自信息源、影响数据仓库的数据信息转化为数据仓库模式;当信息源中的数据发生变化时,集成器过滤、汇总信息并将其与其他信息合并,以将新信息集成到数据仓库中。3.根据权利要求1所述的一种基于大数据技术的业扩报装档案挖掘分析方法,其特征是:所述业扩报装档案数据挖掘处理方法采用组合预测模型对数据进行处理,获取档案数据中的深层次关系;神经网络组合器选择输入层、隐层和输出层三层bp网络结构,采用sigmoid函数作为激活函数;采用自适应学习率的改进bp算法,学习率调整公式为:
ꢀꢀꢀꢀꢀ
(1)在公式(1)中,η(k)是步骤的学习速率;e(k)是网络的k阶跃误差,在调整学习速率时,首先检查权重的校正是否能够减小误差函数;如果误差减小,则学习率太小,应适当提高;否则,应降低学习速度,使学习速度随误差而变化,使学习步长增长并趋于稳定,加快神经网络的收敛速度;具体计算步骤如下:(1) 读取神经网络的结构信息和数据信息;
(2) 初始化神经网络的隐层权重v
p
、输出层权重w
p
、隐层权重ψ、输出层阈值φ、分配给的随机值[-1,1]、学习率和动量因子的初始值;(3) 输入样本数据,输入输出数据规范化;(4) 选择一个样本;实际输出y,对网络的输出进行了正向计算,并给出了输出h
p
的计算公式,网络的实际输出是向前计算的,隐藏层和输出层的输出y
i
的计算公式如下:
ꢀꢀꢀ
(2)公式(2)中f(x)为s形函数;m为隐藏层节点数,通过经验公式检验隐藏层数,确定:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)在公式(3)中,p是训练样本数,是输入层的节点数,在隐藏层,采用garch模型对业务报表的扩展文件数据进行处理;garch(1,1)模型表达式如下:
ꢀꢀꢀꢀꢀꢀꢀ
(4)在公式(4)中,α0、α1和β均为常数,α0›
1,α1≥1,β≥0 ,h
t 是z
t
的一个条件变量;(5) 计算输出层的误差,统计样本的均方误差;(6) 修正学习率、反向修正权重和阈值;如果满足误差精度,则输出结果;否则,转至步骤(4);根据上述过程,采用组合预测模型对数据进行处理,将处理后的业扩报装数据组成一个数据集,并根据聚类挖掘原理对业扩报装档案数据进行分析。4.根据权利要求3所述的一种基于大数据技术的业扩报装档案挖掘分析方法,其特征是:所述业扩报装档案数据分析,针对经典k-means算法的不足,采用遗传算法对其进行改进,并利用改进的dgk-means算法对电力业务扩展中应用和安装的文件数据进行挖掘和分析;dgk均值算法的具体描述如下:(1) 首先,对业扩报装档案数据进行了编码;对于本专利中的应用,聚类的数量是一个整数,并且使用8个字节进行编码;(2) 设置遗传参数:群体大小q、交叉概率p
c
、变异概率p
q
、新一代g中新染色体的比例以及最大迭代次数t;(3) 随机生成初始种群,使用随机函数生成q初始种群;(4) 计算人口中每个个体的适应度;适应度是评价编码个体优劣的一个参数,即聚类数的优劣,用来判断得到的聚类数是否符合数据的分布特征;聚类步骤如下:1) 根据上述密度初始中心选择方法进行初始聚类,聚类数为q;2)每个核心数据代表一个簇,计算簇内数据的平均值,得到该簇的新簇中心;计算公式如下:
ꢀꢀꢀꢀꢀꢀꢀꢀ
(5)公式(5)中,x
j
为各聚类的核心数据;|c
i
|是群集中的数据总量;3)分别计算聚类结果的适合度;计算公式如下:
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
ꢀꢀꢀ
(7)
ꢀꢀꢀꢀ
(8)在上述公式中,c
i
是i簇的中心点;db
c
表示整个数据集的集群之间的距离;d
c
是数据集的簇内距离;d(c
i
,c
j
)是两点之间的欧氏距离;k为聚类数;num
i
是i集群中包含的数据点数量;p
i,j
是i集群的j点,c
i
是i簇的中心点;减少簇的数量,并合并具有最接近簇间距的两个簇;新合成的簇的中心是原始两个簇的所有数据对象的平均值;(5) 对于每个迭代,计算数据集群结果的适合度;经过选择、交叉和变异,获得新的个体;重复这些步骤,直到达到最大迭代次数;以新一代群体中最大适应度的k值作为最优k值和初始中心,并输出结果;根据上述算法的聚类挖掘结果,根据不同的用户需求、用户群体以及数据之间的关联度,对业扩报装数据进行了划分,并分析了不同的电力服务需求与业扩报装之间的关系,为今后相关服务效率的提高提供支持。
技术总结
本发明提出的是一种基于大数据技术的业扩报装档案挖掘分析方法。包括业扩报装档案数据仓库的建立和业扩报装档案数据挖掘处理方法;在建立业扩报装档案数据仓库的基础上,利用组合预测模型对业扩报装数据进行处理;在利用遗传算法对k均值聚类进行改进后,进行数据挖掘以获取归档数据之间的关系。所述业扩报装档案数据仓库采用维表法建立,由状态数据层、历史数据层、综合数据层、专用数据层和控制管理组成。所述业扩报装档案数据挖掘处理方法采用组合预测模型对数据进行处理,获取档案数据中的深层次关系。本发明具有较高的数据处理效率,缩短业扩报装时间,提高企业的经济效益。适宜作为一种基于大数据技术的业扩报装档案挖掘分析方法应用。掘分析方法应用。掘分析方法应用。
技术研发人员:高宁 曾玲 梁海洪 沈晓舟 张博 左越 张蓓 董阳 付临 周鑫 刘蕤 付海东
受保护的技术使用者:国网辽宁省电力有限公司 国家电网有限公司
技术研发日:2021.12.01
技术公布日:2022/2/18
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。