技术特征:
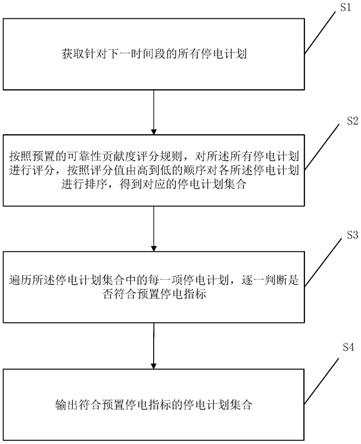
1.一种重复数据判断方法,其包括以下步骤:s1:获取待检索数据库的数据库表;所述数据库表中包括:数据id、数据的业务字段;所述数据id为标记该条目数据的唯一id;所述业务字段为表示该条目数据的实质内容的数据;数据的所述业务字段相同,则表明存在数据重复;其特征在于,其还包括以下步骤:s2:获取数据库中的检索用表,确认所述检索用表是否存在;如果所述检索用表不存在,则实施步骤s3;否则实施步骤s4;s3:为所述数据库表中存储的所有数据,建立一个所述检索用表;所述检索用表存储的内容包括:数据id、数据id对应的数据哈希值、重复状态、创建时间;所述检索用表中的所述数据id为所述数据库表中所述数据id的子集;在所述检索用表中,每一条所述数据id与其他字段分别为1:1关系;所述数据哈希值为基于所述数据id对应的数据的所述业务字段使用哈希函数生成;所述创建时间为数据存入所述待检索数据库的时间;所述重复状态的值包括:重复、不重复;s4:比对所述数据库表、所述检索用表;如果所述数据库表中的所述数据id与所述检索用表中的所述数据id不一致,则实施步骤s5,进行本轮数据重复检索操作;否则结束本次操作;s5:获取存在于所述数据库表中,但不存在于所述检索用表中的所有所述数据id,记做:待处理数据id;向所述检索用表中,插入所有所述待处理数据id对应的数据哈希值;s6:在所述检索用表中,查找重复数据;所述查找重复数据的步骤包括:a1:将所述检索用表中的所有所述数据id,以所述数据哈希值进行排序;a2:以所述数据哈希值为区分,将所有所述所述数据id分组;找到所有所述数据id个数大于1的组,记做重复数据组;其余的数据记做:无重复数据;a3:获取每组所述重复数据组,对其包括的所述数据id以所述创建时间进行排序;除所述创建时间最早的所述数据id以外,将其他所有所述数据id对应的所述重复状态字段设置为:重复;a4:所有所述无重复数据对应的所述重复状态字段设置为:不重复;a5:按照数据的所述创建时间将所有数据分组,找到其中所有的重复状态字段为重复的数据,即得到该批次上传到所述待检索数据库的数据中的重复数据。2.根据权利要求1所述一种重复数据判断方法,其特征在于:所述数据哈希值的生成方法为:获取数据的所有所述业务字段,将所有的所述业务字段直接拼接成字符串,然后计算出此字符串的哈希值。
3.根据权利要求1所述一种重复数据判断方法,其特征在于:步骤s1实施之前,预设一个数据重复检索定时方式,按照所述重复检索定时方式,循环实施步骤s1~s6;所述重复检索定时方式包括:设置定时启动时间、设置重复检索相隔时间t;所述定时启动时间包括一个或者多个具体的时间,每天的所述定时启动时间到达后,实施一轮步骤s1~s6;所述重复检索相隔时间t为两次所述数据重复检索操作之间的间隔时间,上一次的数据重复检索操作中步骤s6结束t时间后,开始实施下一轮重复数据判断方法中的步骤s1;当所述重复检索定时方式选择所述定时启动时间时,如果因为数据量过大,导致前一次数据重复检索操作还未完成,下一次定时启动时间已经到达,则顺延下一次所述数据重复检索操作的开始时间到前次数据重复检索操作的结束时间。4.根据权利要求1所述一种重复数据判断方法,其特征在于:步骤s5中,所述插入数据哈希值操作的步骤包括:b1:建立临时表;所述临时表包括:数据id、数据哈希值;b2:将所有的所述待处理数据id存入所述临时表中;b3:为所述临时表中的每一条所述待处理id,基于其对应的业务字段生成其对应的所述数据哈希值,并存入所述临时表;将所述临时表中的所述待处理id、所述数据哈希值批量存入所述检索用表中;b4:当所有的所述待处理id的所述数据哈希值都被存入到所述检索用表中后,删除所述临时表。5.根据权利要求4所述一种重复数据判断方法,其特征在于:步骤b3中将所述数据哈希值批量存入所述检索用表的过程,包括以下步骤:c1:预设一个分页处理阈值m;所述分页处理阈值m表示每次生成所述数据哈希值的数据的条目数;c2:每次获取m条所述待处理数据id,基于所述所述数据库表,得到其对应数据的所述业务字段,分别生成所述数据哈希值;c3:将每个所述数据哈希值存入所述临时表中;c4:将本次m条所述待处理数据id对应的所述数据哈希值一起存入到所述检索用表中;c5:循环执行步骤c2~c4,直至所有的待处理数据id对应的所述数据哈希值,都被存入到所述检索用表中。
技术总结
本发明提供一种重复数据判断方法,其可以高效的完成大数据中的重复数据统计的工作,同时对服务器硬件性能要求也很低。本专利技术方案中,基于数据的业务字段生成数据哈希值,通过数据哈希值的比对,找到所有的重复数据;每次进行比对是通过比对数据库表、检索用表,找到二者不一致的数据ID,作为待处理数据ID,然后成批次的对待处理数据ID生成数据哈希值,通过分别对数据哈希值排序、同哈希值的数据之间通过创建时间排序,找到待处理数据ID中与待检索数据库中原有数据重复的数据。索数据库中原有数据重复的数据。索数据库中原有数据重复的数据。
技术研发人员:郭彦涛 程亮 曹红艳
受保护的技术使用者:江苏未至科技股份有限公司
技术研发日:2021.10.28
技术公布日:2022/2/18
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。