1.本发明涉及身份识别认证技术领域,具体涉及一种多方位身份识别认证系统与方法。
背景技术:
2.在进行在线业务办理期间,需要通过身份识别认证来确认操作者的身份,目前的身份识别认证包括短信码认证、身份证认证和人脸识别验证等。传统的的人脸识别认证技术,容易被采用照片等方式破解,安全性不高。为了提高安全性,随后出现了活体检测,通过引入如摇头、眨眼等动作进行,但如今这一检测也存在一定的漏洞,可通过3d打印机制作人脸面具进行破解,也可通过制作头部模型将相应的正脸照片贴在模型前侧,侧脸照片贴在模型的两边,在活体检测提示摇头时转动模型即可通过部分活体检测。
技术实现要素:
3.本发明的目的是针对现有技术存在的不足,提供一种多方位身份识别认证系统与方法。
4.为实现上述目的,在第一方面,本发明提供了一种多方位身份识别认证系统,包括终端和服务器,在进入身份识别认证流程后,所述服务器随机生成一段认证信息,并将所述认证信息与预置的引导信息一同发送至所述终端;
5.所述终端包括信息输出部件,其在接收到服务器发送的认证信息和引导信息后,控制所述信息输出部件将所述认证信息和引导信息输出,以供待认证人员获知该认证消息的内容,所述引导信息包括引导该待认证人员阅读所述认证消息;
6.所述终端还包括摄像头,用以在接收到服务器发送的认证信息和引导信息后,获取待认证人员的视频数据;
7.所述终端还包括通信模块,用以接收所述服务器发送的认证信息和引导信息,并用以将所述视频数据发送至服务器;
8.所述服务器从视频数据中提取连续的若干帧第一图像数据,并基于所述第一图像数据进行人脸识别认证;
9.在人脸识别认证通过以后,所述服务器还以设定时间间隔提取若干第二图像图像数据,并基于人脸识别将所述第二图像数据与第一图像数据进行对比,如在设定阈值以上,再将所述第二图像数据之间进行图像相似度对比,如所述相似度在设定阈值以下,则输出身份识别认证通过结果。
10.进一步的,所述终端还包括受话器,用以获取待认证人员阅读所述认证消息时的语音数据,所述通信模块将所述语音数据发送至服务器,所述服务器基于语音识别将所述语音数据与认证信息进行对比,以判断所述语音数据与认证信息是否一致,如一致,则输出身份识别认证通过结果。
11.进一步的,所述服务器基于口型识别模型对所述视频数据的口型进行识别,并将
识别结果与语音数据同步对比,以判断所述语音数据是否由当前视频中的人员发出。
12.进一步的,所述信息输出部件包括显示屏,所述认证信息和引导信息均以文字的方式显示在显示屏上。
13.进一步的,所述信息输出部件包括显示屏和扬声器,所述认证信息以文字的方式显示在显示屏上,所述引导信息以语音的方式由扬声器输出。
14.在第二方面,本发明提供了一种多方位身份识别认证方法,应用在上述述的终端和服务器组成的系统中,包括:
15.在进入身份识别认证流程后,所述服务器随机生成一段认证信息,并将所述认证信息与预置的引导信息一同发送至所述终端;
16.所述终端通过通信模块接收所述服务器发送的认证信息和引导信息,在接收到服务器发送的认证信息和引导信息后,所述终端控制其信息输出部件将所述认证信息和引导信息输出,以供待认证人员获知该认证消息的内容,所述引导信息包括引导该待认证人员阅读所述认证消息;
17.在接收到服务器发送的认证信息和引导信息后,所述终端控制其摄像头获取待认证人员的视频数据,并通过通信模块将所述视频数据发送至服务器;
18.所述服务器从视频数据中提取连续的若干帧第一图像数据,并基于所述第一图像数据进行人脸识别认证;
19.在人脸识别认证通过以后,所述服务器还以设定时间间隔提取若干第二图像图像数据,并基于人脸识别将所述第二图像数据与第一图像数据进行对比,如在设定阈值以上,再将所述第二图像数据之间进行图像相似度对比,如所述相似度在设定阈值以下,则输出身份识别认证通过结果。
20.进一步的,所述终端通过受话器获取待认证人员阅读所述认证消息时的语音数据,所述通信模块将所述语音数据发送至服务器,所述服务器基于语音识别将所述语音数据与认证信息进行对比,以判断所述语音数据与认证信息是否一致,如一致,则输出身份识别认证通过结果。
21.进一步的,所述服务器基于口型识别模型对所述视频数据的口型进行识别,并将识别结果与语音数据同步对比,以判断所述语音数据是否由当前视频中的人员发出。
22.进一步的,所述认证信息和引导信息均以文字的方式显示在终端的显示屏上。
23.进一步的,所述认证信息以文字的方式显示在终端的显示屏上,所述引导信息以语音的方式由终端的扬声器输出。
24.有益效果:本发明在认证期间通过向待认证人员的终端发送认证信息,并引导待认证人员阅读该认证信息,通过摄像头和受话器采集待认证人员的视频数据和语音数据,并基于人脸识别、图像对比、口型识别和语音识别多个方位进行身份识别认证,确保认证准确性的同时,还可防止不法人员轻松破解。
附图说明
25.图1是本发明实施例的多方位身份识别认证方法的流程示意图。
具体实施方式
26.下面结合附图和具体实施例,进一步阐明本发明,本实施例在以本发明技术方案为前提下进行实施,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围。
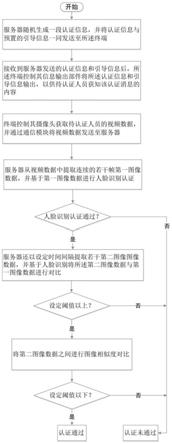
27.如图1所示,本发明实施例提供了一种多方位身份识别认证系统,包括终端和服务器,在进入身份识别认证流程后,服务器随机生成一段认证信息,并将认证信息与预置的引导信息一同发送至终端。具体来说,认证信息可以是一句或者几句完整的语句,这些语句所表达的意思与业务本身可以完全不相关,也可以是毫无规律的多个字。
28.终端包括信息输出部件,终端在接收到服务器发送的认证信息和引导信息后,控制信息输出部件将认证信息和引导信息输出,以供待认证人员获知该认证消息的内容,引导信息包括引导该待认证人员阅读认证消息。具体来说,信息输出部件可以采用显示屏,认证信息和引导信息均以文字的方式显示在显示屏上。引导信息可以是“请阅读以下内容”等。信息输出部件也可以采用显示屏和扬声器,认证信息优选以文字的方式显示在显示屏上,引导信息以语音的方式由扬声器输出。
29.终端还包括摄像头,摄像头用以在接收到服务器发送的认证信息和引导信息后,获取待认证人员的视频数据。该视频数据具体可以为设定时长,该设定时长可以满足大多数人阅读语速需求,确保在该设定时长内可轻松完成阅读认证消息。
30.终端还包括通信模块,通信模块用以接收服务器发送的认证信息和引导信息,并用以将视频数据发送至服务器,满足与服务器之间的正常交互功能。
31.服务器在接收到视频数据后,服务器从视频数据中提取连续的若干帧第一图像数据,并基于第一图像数据进行人脸识别认证。第一图像数据一般可从视频数据中的前部分提取,此时,待认证人员未进行阅读认证信息,面部特征和表情等不会因为发生太大变化,提高人脸识别认证的准确性。
32.在人脸识别认证通过以后,服务器还以设定时间间隔提取若干第二图像图像数据,并基于人脸识别将第二图像数据与第一图像数据进行对比,如在设定阈值以上,可保证认证期间待认证人员没有更换,再将第二图像数据之间进行图像相似度对比,由于待认证人员处于阅读状态,其眼睛、嘴巴以及皱纹等面部状态必然会产生一定的变化,从而出现不同时段的第二图像数据是不完全一致的,如相似度在设定阈值以下,则输出身份识别认证通过结果。如果相似度在设定阈值之上,则说明当前出现在视频中的待认证人员可能是照片或头部模型等。第二图像数据可以是间隔提取的多组,优选均匀覆盖整个视频之中。
33.本发明实施例的终端还包括受话器,用以获取待认证人员阅读认证消息时的语音数据,通信模块将受话器采集的语音数据发送至服务器,服务器基于语音识别将语音数据与认证信息进行对比,以判断语音数据与认证信息是否一致,如一致,则输出身份识别认证通过结果。结合语音识别判断后,可进一步提高身份识别认证的精度。
34.服务器在接收到以上视频数据和语音数据后,可以基于口型识别模型对视频数据的口型进行识别,并将识别结果与语音数据同步对比,以判断语音数据是否由当前视频中的人员发出。由此可进一步提高身份识别认证的精度,避免采用人头模型等破解。
35.基于以上实施例可以看出,本发明还提供了一种多方位身份识别认证方法,应用在终端和服务器组成的系统中,包括:
36.在进入身份识别认证流程后,服务器随机生成一段认证信息,并将认证信息与预
置的引导信息一同发送至终端。具体来说,认证信息可以是一句或者几句完整的语句,这些语句所表达的意思与业务本身可以完全不相关,也可以是毫无规律的多个字。
37.终端通过通信模块接收所述服务器发送的认证信息和引导信息,在接收到服务器发送的认证信息和引导信息后,终端控制其信息输出部件将认证信息和引导信息输出,以供待认证人员获知该认证消息的内容,引导信息包括引导该待认证人员阅读认证消息。具体来说,信息输出部件可以采用显示屏,认证信息和引导信息均以文字的方式显示在显示屏上。引导信息可以是“请阅读以下内容”等。信息输出部件也可以采用显示屏和扬声器,认证信息优选以文字的方式显示在显示屏上,引导信息以语音的方式由扬声器输出。
38.在接收到服务器发送的认证信息和引导信息后,终端控制其摄像头获取待认证人员的视频数据,并通过通信模块将视频数据发送至服务器。。该视频数据具体可以为设定时长,该设定时长可以满足大多数人阅读语速需求,确保在该设定时长内可轻松完成阅读认证消息。
39.服务器在接收到视频数据后,服务器从视频数据中提取连续的若干帧第一图像数据,并基于所述第一图像数据进行人脸识别认证。第一图像数据一般可从视频数据中的前部分提取,此时,待认证人员未进行阅读认证信息,面部特征和表情等不会因为发生太大变化,提高人脸识别认证的准确性。
40.在人脸识别认证通过以后,服务器还以设定时间间隔提取若干第二图像图像数据,并基于人脸识别将第二图像数据与第一图像数据进行对比,如在设定阈值以上,可保证认证期间待认证人员没有更换,再将第二图像数据之间进行图像相似度对比,由于待认证人员处于阅读状态,其眼睛、嘴巴以及皱纹等面部状态必然会产生一定的变化,从而出现不同时段的第二图像数据是不完全一致的,如相似度在设定阈值以下,则输出身份识别认证通过结果。如果相似度在设定阈值之上,则说明当前出现在视频中的待认证人员可能是照片或头部模型等。第二图像数据可以是间隔提取的多组,优选均匀覆盖整个视频之中。
41.本发明实施例通过终端的受话器获取待认证人员阅读认证消息时的语音数据,通信模块将受话器采集的语音数据发送至服务器,服务器基于语音识别将语音数据与认证信息进行对比,以判断语音数据与认证信息是否一致,如一致,则输出身份识别认证通过结果。结合语音识别判断后,可进一步提高身份识别认证的精度。
42.在接收到以上视频数据和语音数据后,服务器还可以基于口型识别模型对视频数据的口型进行识别,并将识别结果与语音数据同步对比,以判断语音数据是否由当前视频中的人员发出。由此可进一步提高身份识别认证的精度,避免采用人头模型等破解。
43.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,其它未具体描述的部分,属于现有技术或公知常识。在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。