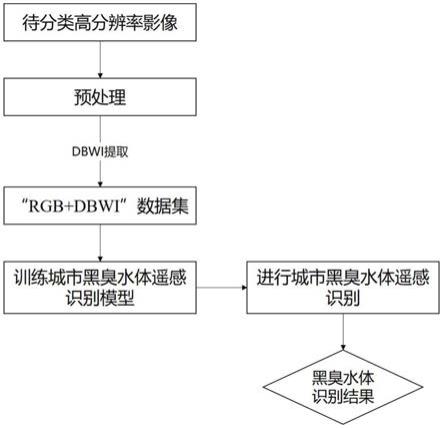
基于yolo v3的探地雷达图像目标检测方法
技术领域
1.本发明涉及雷达图像处理方法技术领域,尤其涉及一种基于yolo v3的探地雷达图像目标检测方法。
背景技术:
2.探地雷达作为一种基于高频电磁波的无损探测设备,当电磁波在地下介质传播时,遇到地下目标的电性差异分界面时会产生双曲线形状的反射线,称为双曲波。通过双曲波的波形、振幅强度和时间变化等特性可以推断出地下目标的空间位置、结构、形态和埋藏深度等重要信息。因此这对于理解地下目标的特点具有重要的指示作用。但是由于系统噪声和地下介质的不均匀性,会导致生成的图像非常复杂。
技术实现要素:
3.本发明所要解决的技术问题是如何提供一种可以更好的提取出特征,提高检测效果的基于yolo v3的探地雷达图像目标检测方法。
4.为解决上述技术问题,本发明所采取的技术方案是:一种基于yolo v3的探地雷达图像目标检测方法,其特征在于包括如下步骤:
5.采用探地雷达设备采集相关的地质图像,并进行数据准备;
6.对采集到的图像进行预处理;
7.使用网络darknet
‑
53来提取特征;
8.图像处理方法为数据先经过preprocess_true_boxes()函数处理,然后输入到模型,损失函数是yolo_loss(),网络最后一个卷积层的输出作为函数yolo_head()的输入,然后再使用函数yolo_eval()得到目标检测结果。
9.进一步的技术方案在于,进行数据准备的方法如下:
10.预测特征图的anchor框集合:3个尺度的特征图,每个特征图3个anchor框,共9个框,从小到大排列;框1
‑
3在大尺度52x52特征图中使用,框4
‑
6是中尺度26x26,框7
‑
9是小尺度13x13;大尺度特征图用于检测小物体,小尺度检测大物体;9个anchor来源于边界框的k
‑
means聚类;
11.图片输入尺寸:默认为416x416,选择416的原因是:图片尺寸满足32的倍数,在darknet网络中,执行5次步长为2卷积,降采样;
12.在最底层时,特征图尺寸需要满足为奇数,以保证中心点落在唯一框中。
13.进一步的技术方案在于,对采集到的图像进行预处理的方法如下:
14.灰度化:灰度化,在rgb模型中,如果r=g=b时,则彩色表示一种灰度颜色,其中r=g=b的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值灰度范围为0
‑
255;采用分量法、最大值法、平均值法或加权平均法对彩色图像进行灰度化;
15.几何变换:图像几何变换又称为图像空间变换,通过平移、转置、镜像、旋转、缩放对采集的图像进行处理,用于改正图像采集系统的系统误差和仪器位置的随机误差;使用
最近邻插值、双线性插值或双三次插值算法,使得输出图像的像素被映射到输入图像的整数坐标上;
16.图像增强:增强图像中的有用信息,它可以是一个失真的过程,其目的是要改善图像的视觉效果,针对给定图像的应用场合,有目的地强调图像的整体或局部特性,将原来不清晰的图像变得清晰或强调某些感兴趣的特征,扩大图像中不同物体特征之间的差别,抑制不感兴趣的特征,使之改善图像质量、丰富信息量,加强图像判读和识别效果,满足某些特殊分析的需要。
17.进一步的技术方案在于,所述yolov3所使用的主干特征提取网络为darknet
‑
53,darknet
‑
53包括连续的3
×
3和1
×
1卷积层,一共有53个卷积层,所以称它为darknet
‑
53,
18.darknet53具有一个重要特点是使用了残差网络residual,darknet53中的残差卷积就是首先进行一次卷积核大小为3x3、步长为2的卷积,该卷积会压缩输入进来的特征层的宽和高,此时可以获得一个特征层,将该特征层命名为layer;之后我们再对该特征层进行一次1x1的卷积和一次3x3的卷积,并把这个结果加上layer,此时便构成了残差结构;通过不断的1x1卷积和3x3卷积以及残差边的叠加,大幅度的加深网络;
19.darknet
‑
53的每一个卷积部分使用darknetconv2d结构,每一次卷积时进行l2正则化,完成卷积后进行batchnormalization标准化与leakyrelu;leaky relu则是给所有负值赋予一个非零斜率,以数学的方式可以表示为:
[0020][0021]
进一步的技术方案在于,yolov3的解码过程分为两步:
[0022]
先将每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心;
[0023]
然后再利用先验框和h、w结合计算出预测框的宽高,得到整个预测框的位置。
[0024]
进一步的技术方案在于,所述darknet
‑
53网络进行训练的方法如下:
[0025]
1)计算loss所需参数;
[0026]
2)对于yolo v3的模型来说,网络最后输出的内容就是三个特征层每个网格点对应的预测框及其种类,即三个特征层分别对应着图片被分为不同size的网格后,每个网格点上三个先验框对应的位置、置信度及其种类;
[0027]
输出层的shape分别为(13,13,75),(26,26,75),(52,52,75),最后一个维度为75是因为是基于voc数据集的,它的类为20种,yolo v3只有针对每一个特征层存在3个先验框,所以最后维度为3x25;
[0028]
如果使用的是coco训练集,类则为80种,最后的维度应该为255=3x85,三个特征层的shape为(13,13,255),(26,26,255),(52,52,255)
[0029]
3)loss的计算过程:
[0030]
得到pred和target后,进行如下步骤:
[0031]3‑
1)判断真实框在图片中的位置,判断其属于哪一个网格点去检测;
[0032]3‑
2)判断真实框和哪个先验框重合程度最高;
[0033]3‑
3)计算该网格点应该有怎么样的预测结果才能获得真实框;
[0034]3‑
4)对所有真实框进行处理;
[0035]3‑
5)获得网络应该有的预测结果,将其与实际的预测结果对比。
[0036]
进一步的技术方案在于,preprocess_true_boxes()函数包括如下参数:
[0037]
true_boxes:实际框的位置和类别,维度为boxes_num
×
5,boxes_num表示一张图片中有几个实际框,第二个维度[x1,y1,x2,y2,class],class是绝对数字值;
[0038]
input_shape:网络的输入的图片的尺寸;
[0039]
anchors:通过generate_anchors.py,利用k
‑
means聚类,统计出这个数据集中的大部分目标的宽高,统计出的anchors类似于下面这样的6个元素的list,每个元素中的两个数值代表box的宽,高.anchors=[an0,an1,an2,an3,an4,an5]=[[81.112.],[114.158.],[146.202.],[187.259.],[255.349.],[486.670.]]。
[0040]
进一步的技术方案在于,preprocess_true_boxes()函数的处理方法如下:
[0041]
step1:构造标注数据true_boxes.维度为[batch_size,4,5];
[0042]
step2:构造boxes_xy,boxes_wh;
[0043]
计算每个box的中心点boxes_xy和宽高boxes_wh,计算原则为:cent_x=(x1 x2)/2,w=x2
‑
x1;
[0044]
step3:根据boxes_xy,boxes_wh更新true_boxes中的值,并做归一化;
[0045]
step4:构造网络回归目标y_true,shape=[[y_true1],[y_true2]],y_true1的维度为[batch_size,13,13,3,4 1 num_classes],y_true2的维度为[batch_size,26,26,3,8];
[0046]
step5:遍历同一个batch_size中的每张图片。
[0047]
采用上述技术方案所产生的有益效果在于:所述方法首先采用探地雷达设备采集到相关的地质图像,并进行数据准备;然后对采集到的图像进行预处理;再次搭建一个新的网络darknet
‑
53用来提取特征;最后经过preprocess_true_boxes()函数处理,再使用函数yolo_eval()得到结果;所述方法可以更好的提取出特征,提高检测效果。
附图说明
[0048]
下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0049]
图1是本发明实施例所述方法的流程图;
[0050]
图2是本发明实施例所述方法中darknet
‑
53的网络结构示意图;
具体实施方式
[0051]
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0052]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
[0053]
如图1所示,本发明实施例公开了一种基于yolo v3的探地雷达图像目标检测方法,包括如下步骤:
[0054]
s1:采用探地雷达设备采集相关的地质图像,并进行数据准备;
[0055]
s2:对采集到的地质图像进行预处理;
[0056]
s3:搭建一个新的网络模型darknet
‑
53来于地质图像提取特征;
[0057]
s4:图像处理方法为数据先经过preprocess_true_boxes()函数处理,然后做一些处理输入到模型,模型的损失函数是yolo_loss(),网络最后一个卷积层的输出作为函数yolo_head()的输入,然后再使用函数yolo_eval()得到处理后的结果。
[0058]
yolo v3网络模型具有如下特点:
[0059]
使用残差网络residual,残差卷积就是进行一次3x3、步长为2的卷积,然后保存该卷积layer,再进行一次1x1的卷积和一次3x3的卷积,并把这个结果加上layer作为最后的结果,残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
[0060]
提取多特征层进行目标检测,一共提取三个特征层,特征层的shape分别为(13,13,75),(26,26,75),(52,52,75),最后一个维度为75是因为该图是基于voc数据集的,它的类为20种,yolo v3只有针对每一个特征层存在3个先验框,所以最后维度为3x25;
[0061]
如果使用的是coco训练集,类则为80种,最后的维度应该为255=3x85,三个特征层的shape为(13,13,255),(26,26,255),(52,52,255);
[0062]
其采用反卷积umsampling2d设计,逆卷积相对于卷积在神经网络结构的正向和反向传播中做相反的运算,其可以更多更好的提取出特征。
[0063]
进一步的,采用探地雷达设备采集到相关的地质图像,并进行数据准备的具体方法为:
[0064]
1)数据准备:预测特征图的anchor框集合:3个尺度的特征图,每个特征图3个anchor框,共9个框,从小到大排列;框1
‑
3在大尺度52x52特征图中使用,框4
‑
6是中尺度26x26,框7
‑
9是小尺度13x13;大尺度特征图用于检测小物体,小尺度检测大物体;9个anchor来源于边界框的k
‑
means聚类。
[0065]
2)图片输入尺寸,默认为416x416,选择416的原因是:图片尺寸满足32的倍数,在darknet网络中,执行5次步长为2卷积,降采样。在最底层时,特征图尺寸需要满足为奇数,如13,以保证中心点落在唯一框中。如果为偶数时,则中心点落在中心的4个框中,导致歧义。
[0066]
进一步的,对采集到的图像进行预处理具体为:
[0067]
灰度化:
[0068]
在rgb模型中,如果r=g=b时,则彩色表示一种灰度颜色,其中r=g=b的值叫灰度值,因此,灰度图像每个像素只需一个字节存放灰度值(又称强度值、亮度值),灰度范围为0
‑
255。一般有分量法、最大值法、平均值法和加权平均法四种方法对彩色图像进行灰度化。
[0069]
几何变换:
[0070]
图像几何变换又称为图像空间变换,通过平移、转置、镜像、旋转、缩放等几何变换对采集的图像进行处理,用于改正图像采集系统的系统误差和仪器位置(成像角度、透视关
系乃至镜头自身原因)等随机误差。此外,还需要使用灰度插值算法,因为按照这种变换关系进行计算,输出图像的像素可能被映射到输入图像的非整数坐标上。通常采用的方法有最近邻插值、双线性插值和双三次插值。
[0071]
图像增强:
[0072]
增强图像中的有用信息,可以是一个失真的过程,其目的是要改善图像的视觉效果,针对给定图像的应用场合,有目的地强调图像的整体或局部特性,将原来不清晰的图像变得清晰或强调某些感兴趣的特征,扩大图像中不同物体特征之间的差别,抑制不感兴趣的特征,使之改善图像质量、丰富信息量,加强图像判读和识别效果,满足某些特殊分析的需要。图像增强算法可分成两大类:空间域法和频率域法。
[0073]
进一步的,模型搭建用了一个新的网络来提取特征,融合了yolo v2、darknet
‑
19以及其他新型残差网络,包括连续的3
×
3和1
×
1卷积层,当然,其中也添加了一些shortcut connection,整体体量也更大。因为一共有53个卷积层,所以称它为darknet
‑
53,如图2所示。具体为:
[0074]
yolov3所使用的主干特征提取网络为darknet
‑
53,具有两个重要特点:
[0075]
1)darknet53具有一个重要特点是使用了残差网络residual,darknet53中的残差卷积就是首先进行一次卷积核大小为3x3、步长为2的卷积,该卷积会压缩输入进来的特征层的宽和高,此时可以获得一个特征层,将该特征层命名为layer。之后再对该特征层进行一次1x1的卷积和一次3x3的卷积,并把这个结果加上layer,此时便构成了残差结构。通过不断的1x1卷积和3x3卷积以及残差边的叠加,便大幅度的加深了网络。残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
[0076]
2)darknet
‑
53的每一个卷积部分使用了darknetconv2d结构,每一次卷积时进行l2正则化,完成卷积后进行batchnormalization标准化与leakyrelu。普通的relu是将所有的负值都设为零,leaky relu则是给所有负值赋予一个非零斜率。以数学的方式我们可以表示为:
[0077][0078]
从特征获取预测结果的过程可以分为两个部分,分别是:
[0079]
构建fpn特征金字塔进行加强特征提取。
[0080]
利用yolo head对三个有效特征层进行预测。
[0081]
a、构建fpn特征金字塔进行加强特征提取
[0082]
在特征利用部分,yolov3提取多特征层进行目标检测,一共提取三个特征层。
[0083]
三个特征层位于主干部分darknet53的不同位置,分别位于中间层,中下层,底层,三个特征层的shape分别为(52,52,256)、(26,26,512)、(13,13,1024)。
[0084]
在获得三个有效特征层后,利用这三个有效特征层进行fpn层的构建,构建方式为:
[0085]
13x13x1024的特征层进行5次卷积处理,处理完后利用yolohead获得预测结果,一部分用于进行上采样umsampling2d后与26x26x512特征层进行结合,结合特征层的shape为
(26,26,768)。
[0086]
结合特征层再次进行5次卷积处理,处理完后利用yolohead获得预测结果,一部分用于进行上采样umsampling2d后与52x52x256特征层进行结合,结合特征层的shape为(52,52,384)。
[0087]
结合特征层再次进行5次卷积处理,处理完后利用yolohead获得预测结果。
[0088]
特征金字塔可以将不同shape的特征层进行特征融合,有利于提取出更好的特征。
[0089]
b、利用yolo head获得预测结果
[0090]
利用fpn特征金字塔,可以获得三个加强特征,这三个加强特征的shape分别为(13,13,512)、(26,26,256)、(52,52,128),然后我们利用这三个shape的特征层传入yolo head获得预测结果。
[0091]
yolo head本质上是一次3x3卷积加上一次1x1卷积,3x3卷积的作用是特征整合,1x1卷积的作用是调整通道数。
[0092]
对三个特征层分别进行处理,假设我们预测是的voc数据集,我们的输出层的shape分别为(13,13,75),(26,26,75),(52,52,75),最后一个维度为75是因为该图是基于voc数据集的,它的类为20种,yolov3针对每一个特征层的每一个特征点存在3个先验框,所以预测结果的通道数为3x25;
[0093]
如果使用的是coco训练集,类则为80种,最后的维度应该为255=3x85,三个特征层的shape为(13,13,255),(26,26,255),(52,52,255)
[0094]
其实际情况就是,输入n张416x416的图片,在经过多层的运算后,会输出三个shape分别为(n,13,13,255),(n,26,26,255),(n,52,52,255)的数据,对应每个图分为13x13、26x26、52x52的网格上3个先验框的位置。
[0095]
预测结果的解码:
[0096]
通过上述步骤可以获得三个特征层的预测结果,shape分别为:
[0097]
(n,13,13,255);
[0098]
(n,26,26,255);
[0099]
(n,52,52,255);
[0100]
每一个有效特征层将整个图片分成与其长宽对应的网格,如(n,13,13,255)的特征层就是将整个图像分成13x13个网格;然后从每个网格中心建立多个先验框,这些框是网络预先设定好的框,网络的预测结果会判断这些框内是否包含物体,以及这个物体的种类。
[0101]
由于每一个网格点都具有三个先验框,所以上述的预测结果可以reshape为:
[0102]
(n,13,13,3,85);
[0103]
(n,26,26,3,85);
[0104]
(n,52,52,3,85);
[0105]
其中的85可以拆分为4 1 80,其中的4代表先验框的调整参数,1代表先验框内是否包含物体,80代表的是这个先验框的种类,由于coco分了80类,所以这里是80。如果yolov3只检测两类物体,那么这个85就变为了4 1 2=7。即85包含了4 1 80,分别代表x_offset、y_offset、h和w、置信度、分类结果。但是这个预测结果并不对应着最终的预测框在图片上的位置,还需要解码才可以完成。
[0106]
yolov3的解码过程分为两步:
[0107]
第一步:先将每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心。
[0108]
第二步:然后再利用先验框和h、w结合计算出预测框的宽高,这样就能得到整个预测框的位置。
[0109]
得到最终的预测结果后还要进行得分排序与非极大抑制筛选。
[0110]
这一部分基本上是所有目标检测通用的部分。其对于每一个类进行判别:
[0111]
1)取出每一类得分大于self.obj_threshold的框和得分。
[0112]
2)利用框的位置和得分进行非极大抑制。
[0113]
进一步的,在原图上进行绘制,获得预测框在原图上的位置,这些预测框都是经过筛选的,这些筛选后的框可以直接绘制在图片上,获得结果。
[0114]
训练部分主要包括如下步骤:
[0115]
1)计算loss所需参数;
[0116]
2)对于yolo v3的模型来说,网络最后输出的内容就是三个特征层每个网格点对应的预测框及其种类,即三个特征层分别对应着图片被分为不同size的网格后,每个网格点上三个先验框对应的位置、置信度及其种类。
[0117]
输出层的shape分别为(13,13,75),(26,26,75),(52,52,75),最后一个维度为75是因为是基于voc数据集的,它的类为20种,yolo v3只有针对每一个特征层存在3个先验框,所以最后维度为3x25;
[0118]
如果使用的是coco训练集,类则为80种,最后的维度应该为255=3x85,三个特征层的shape为(13,13,255),(26,26,255),(52,52,255)
[0119]
3)loss的计算过程,
[0120]
得到pred和target后,需要进行如下步骤。
[0121]3‑
1)判断真实框在图片中的位置,判断其属于哪一个网格点去检测。
[0122]3‑
2)判断真实框和哪个先验框重合程度最高。
[0123]3‑
3)计算该网格点应该有怎么样的预测结果才能获得真实框
[0124]3‑
4)对所有真实框进行处理。
[0125]3‑
5)获得网络应该有的预测结果,将其与实际的预测结果对比。
[0126]
进一步的,步骤s4中图像处理方法具体为:
[0127]
数据先经过preprocess_true_boxes()函数处理,然后做一些处理输入到模型,损失函数是yolo_loss(),网络最后一个卷积层的输出作为函数yolo_head()的输入,然后再使用函数yolo_eval()得到结果。
[0128]
1)preprocess_true_boxes(true_boxes,input_shape,anchors,num_classes),这个函数得到detectors_mask(最佳预测的anchor boxes,每一个true boxes都对应一个anchorboxes)
[0129]
参数:
[0130]
true_boxes:实际框的位置和类别,维度为boxes_num
×
5,boxes_num表示一张图片中有几个实际框,第二个维度[x1,y1,x2,y2,class],class是绝对数字值,比如person:0,dog:1,horse:2;
[0131]
input_shape:网络的输入的图片的尺寸,一般选择为[416,416];
[0132]
anchors:通过generate_anchors.py,利用k
‑
means聚类,统计出这个数据集中的大部分目标的宽高,也就是说我现在的训练数据集合中,大部分的检测目标的宽和高,我这里主要看的tiny_yolo,统计出的anchors类似于下面这样的6个元素的list,每个元素中的两个数值代表box的宽,高.anchors=[an0,an1,an2,an3,an4,an5]=[[81.112.],[114.158.],[146.202.],[187.259.],[255.349.],[486.670.]];
[0133]
具体过程:
[0134]
step1:构造标注数据true_boxes.维度为[batch_size,4,5]
[0135]
step2:构造boxes_xy,boxes_wh
[0136]
计算每个box的中心点boxes_xy和宽高boxes_wh,计算原则为:cent_x=(x1 x2)/2,w=x2
‑
x1;
[0137]
step3:根据boxes_xy,boxes_wh更新true_boxes中的值,并做归一化;
[0138]
step4:构造网络回归目标y_true,shape=[[y_true1],[y_true2]],y_true1的维度为[batch_size,13,13,3,4 1 num_classes],y_true2的维度为[batch_size,26,26,3,8];
[0139]
step5:遍历同一个batch_size中的每张图片,假设现在咱们先遍历图片1.jpg;
[0140]
可以看出y_true的构造过程,其基础元素的构成为[x,y,w,h,class,score]的形式,共有batch_size*n*n*anchornum=4*[13
×
13
×
3 26
×
26
×
3]=10140个这样的基础元素,其大部分元素的值都是0,若一个batch 4张图片中有8个目标,则y_true的18252个基本元素中,只有8个不为0,剩下的18252
‑
8=18244个基本元素都是0;对单独一张图片来说,y_true共有batch_size*n*n*anchornum=13
×
13
×
3 26
×
26
×
3=2535个box,也就是说网络会预测出2535个box与其对应,相对于retinanet或其他的one
‑
stage网络预测出几万个box,yolo的计算量会小很多,所以会比较快。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。