1.本发明涉及查询服务技术领域,尤其涉及一种应用于千万级数据量实时查询的优化方法。
背景技术:
2.随着政务服务一体化的进程的不断推进,各级政务服务平台区域成熟,随着时间积累,系统内数据量越来越大,由于前期缺乏针对大量历史数据一些预见性的策略和应对措施,导致原本一些正常的功能出现数据查询缓慢甚至超时的情况。数据量达到千万级后,系统访问量稍微一高很可能导致数据库连接池溢出,系统拓机的情况。
3.针对目前这种情况,大部分政务服务系统会采用两种措施,一种是进行数据的归档,定期将历史数据拿出存到归档数据库,此过程成本最少,系统也能迅速恢复到之前的服务效果,但是全量数据查询非常困难。另外一种是进行分库分表的改造,对数据量大的表进行拆分,此方法既能使系统恢复到之前的服务效果,又能提供比较友好的全量查询,但是成本高昂,涉及到系统架构和基础元数据的改动,关联的功能都需要相应的做出整改。
4.政务服务系统中存在一类表,它们的查询和插入同样重要,不断有新的数据插入进来,又不断对外提供数据全量查询服务,在数据量小的时候各项功能均正常,但是随着时间的推进,数据量越来越大,大量的读写操作一个大表的压力越来越大。造成新数据插入效率低,查数据缓慢的现象。
技术实现要素:
5.针对现有系统已经成熟稳定,架构和oracle数据库元数据结构相对固化,改造难度大成本高的情况下,本发明提供了一种应用于千万级数据量实时查询的优化方法,利用一种成本比较低的的方式,解决千万级数据量查询缓慢的问题,并且对其他功能不会产生连带影响。
6.本发明的技术方案是:
7.一种应用于千万级数据量实时查询的优化方法,
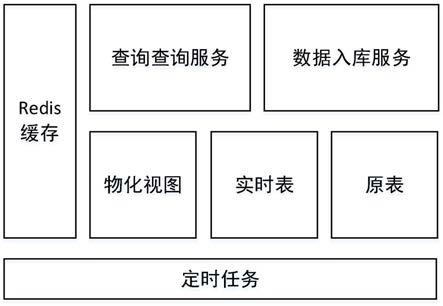
8.1)在原系统数据库基础上通过创建物化视图和实时表实现局部读写分离;
9.2)通过整合redis缓存,将不同参数的查询结果放到缓存,重复查询使用缓存。
10.进一步的,
11.在原表基础上新建定时更新的物化视图和实时表:物化视图存储原表今天以前的数据,每天凌晨进行增量更新或者全量更新今天之前的数据;实时表跟原表一样时间实时插入在同一个事务中保持数据一致性,系统中新建定时任务每天凌晨删除实时表今天之前的数据。
12.再进一步的,
13.物化视图和实时表数据的并集与原表数据完全吻合,使用物化视图和实时表代替原表为查询服务提供支持,历史数据的查询直接通过物化视图查询。
14.把一个物化视图分为一个以上的物化视图,对数据进行水平拆分。
15.进进一步的,
16.将相同查询参数的查询结果放入缓存,重复查询直接从缓存中读取数据
17.在原表数据中插入事务逻辑,添加实时表的插入逻辑,系统集成定时任务,每天凌晨对实时表的数据进行清理,清理当天之前的所有数据,保持实时表的数据不会跟物化表的数据存在重复。
18.再进一步的,
19.查询服务受到请求后,需要把查询分成两步:一步是历史数据查询,组装查询参数首先查看redis中是否存在此查询参数的数据,如果有则直接拿到数据,如果没有则进入物化视图查询逻辑拿到数据并放入缓存;另外一步是实时表实时数据查询,此过程根据查询参数直接连接数据库查询数据。
20.最后查询服务需要通过数据处理逻辑整合两个步骤的数据,最后返回查询服务的结果。
21.本发明适用于已经持续运行一段时间并且数据量达到千万级的基于oracle数据库的政务服务系统,对特定的几个关注度比较高的查询统计功能或者接口做针对性的优化改动,而不影响其他系统内部功能。
22.通过物化视图和新建实时表实现伪读写分离和伪水平切分,通过在物化视图建立索引提高物化视图查询效率,通过集成redis缓存,将查询结果保存到缓存中,提高接口的服务性能。
23.本发明的有益效果是
24.采用本发明,提高总体查询效率,减轻数据库负担,进一步提高服务相应效率效率。同时并没有改变原来的存储结构,也不会对关联的其他功能产生影响,只需要很少的改动就能快速解决问题,一方面提高了查询效率和对外数据服务的效率,另一方面提高了系统的稳定性。
附图说明
25.图1为发明的整体逻辑结构图;
26.图2为数据查询数据流程图。
具体实施方式
27.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
28.本发明的主要目的是基于目前的系统架构和oracle数据库结构,在尽量避免影响关联功能,尽量少的功能改造的前提下,使用物化视图、新建索引和实时表、添加定时任务和整合redis缓存的方式。针对关注度比较高的查询统计功能和接口做针对性优化,既能满足系统对全量数据快速查询的需求,又不影响原有功能的正常运行,是一种低成本的解决方案。
29.(一)数据库“伪读写分离”与“伪水平切分”30.物化视图是包括一个查询结果的数据库对象,它是远程数据的的本地副本,或者用来生成基于数据表求和的汇总表。物化视图存储基于远程表的数据,也可以称为快照。物化视图,说白了,就是物理表,只不过这张表通过oracle的内部机制可以定期更新,将一些大的耗时的表连接用物化视图实现,会提高查询的效率。
31.物化视图的刷新,刷新的模式有两种:on demand和on commit,on demand指物化视图在用户需要的时候进行刷新,可以手工通过dbms_mview.refresh等方法来进行刷新,也可以通过job定时进行刷新。on commit指出物化视图在对基表的dml操作提交的同时进行刷新。
32.由于表的数据量很大而且会有大量的实时数据更新,自动刷新会给数据库造成极大的负担,所以选用on demand方式中指定时间刷新的方式,刷新的方法有四种:fast、complete、force和never。fast刷新采用增量刷新,只刷新自上次刷新以后进行的修改。complete刷新对整个物化视图进行完全的刷新。如果选择force方式,则oracle在刷新时会去判断是否可以进行快速刷新,如果可以则采用fast方式,否则采用complete的方式。never指物化视图不进行任何刷新。
33.例子,创建名称为“histury_view”的物化视图,刷新方式为全部刷新,刷新时间为每天凌晨2点:
[0034][0035]
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(insert、update、delete),而从数据库处理select查询操作。
[0036]
数据量只增不减,历史数据又必须要留存,非常容易成为性能的瓶颈,而要解决这样的数据库瓶颈问题,读写分离也会逐渐遇到瓶颈,此时应该使用水平切分,通过算法,将数据库进行分割的架构。一个水平切分集群中的每个数据库,通常称为一个“分片”。每一个分片中的数据没有重合,所有分片中的数据并集组成全部数据。
[0037]
对于已经成熟的系统来说,要进行“读写分离”和“水平切分”是非常困难的,但是可以借鉴其思路。在原表基础上新建定时更新的物化视图和实时表:物化视图存储原表今天以前的数据,每天凌晨进行增量更新或者全量更新今天之前的数据;实时表跟原表一样时间实时插入在同一个事务中保持数据一致性,系统中新建定时任务每天凌晨删除实时表今天之前的数据。
[0038]
此时物化视图和实时表数据的并集与原表数据完全吻合,使用物化视图和实时表代替原表为特定的查询服务提供支持,物化视图主要实现了“伪读写分离”,历史数据的查询直接通过物化视图查询,降低原表写操作带来的影响。实时表存储当日数据,大大减少数据量,此时的实时表写操作对读操作的影响可以忽略不计。
[0039]
但是随着数据量不断累积,物化视图的数据积累到一定程度后通过添加索引的方式也无法继续优化查询效率。所以要把一个物化视图分为多个物化视图,对数据进行水平拆分,实现数据库“伪水平切分”结构。
[0040]
(二)redis缓存整合与查询服务功能实现
[0041]
redis(remote dictionary server),即远程字典服务,是一个开源的使用ansi c语言编写、支持网络、可基于内存亦可持久化的日志型、key
‑
value数据库,并提供多种语言的api。它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set
‑‑
有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。
[0042]
定时任务对于目前比较常用的基于spring的web系统框架来说并不复杂,主要有两种方式:一是基于注解的定时任务,一种是基于配置的任务调度框架quartz,但都使用到了cron表达式,cron表达式是一个字符串,字符串以5或6个空格隔开,分为6或7个域,每一个域代表一个含义。
[0043]
例子,每天凌晨2点:
[0044][0045]
对于物化视图的历史数据查询,系统中存在大量的重复查询,查询结果也是不会发生变化的,引入redis缓存旨在通过将相同查询参数的查询结果放入缓存,重复查询直接从缓存中读取数据,极大程度减轻数据库压力,增强系统稳定性,并提供高效的查询服务。
[0046]
为了保证数据的一致性,需要更改原表数据插入事务逻辑,添加实时表的插入逻辑,系统集成定时任务,每天凌晨对实时表的数据进行清理,清理当天之前的所有数据,保持实时表的数据不会跟物化表的数据存在重复。
[0047]
查询服务受到请求后,需要把查询分成两步:一步是历史数据查询,组装查询参数首先查看redis中是否存在此查询参数的数据,如果有则直接拿到数据,如果没有则进入物化视图查询逻辑拿到数据并放入缓存;另外一步是实时表实时数据查询,此过程根据查询参数直接连接数据库查询数据。最后查询服务需要通过数据处理逻辑整合两个步骤的数据,最后返回查询服务的结果。
[0048]
以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。