基于双线性ffm和多头注意力机制的广告点击率预估方法
技术领域
1.本发明涉及数据挖掘技术领域,特别是涉及一种基于双线性ffm和多头注意力机制的广告点击率预估方法。
背景技术:
2.随着电子商务的发展,互联网广告已成为一种新媒介广告进入人们的生活。通常,广告主在投放广告之前,希望了解网站上某广告位的已投放广告的点击率,并根据了解的点击率来制定预订广告位的决策。为给广告主提供预定广告位置决策的依据,可以对某广告位置上所投放的广告的点击率进行预估,以供广告主参考。现有技术进行广告点击率预估通常采用的方法是:用待预估广告的历史数据训练出预估模型,上述历史数据包括待预估广告的特征和实际点击率,将待预估广告的特征作为预估模型的输入,将预估模型的输出结果作为待预估广告的预估点击率。其中,模型进行点击率预估的精度,即预估的准确率依赖于模型针对输入数据特征的泛化能力,即对原始特征进行隐含特征提取的能力,其中隐含特征包含原始特征的交叉组合特征和原始特征的深层特征。
3.互联网广告点击率预估方法根据所使用基础算法不同,主要分为基于机器学习模型的预估方法和基于深度神经网络模型的预估方法。其中,基于机器学习模型的预估方法主要利用逻辑回归,矩阵分解,gbdt等方式对互联网广告数据进行点击率预估,随着网络用户不断地增加,无法应对互联网广告数据量大的问题。
4.目前基于深度学习的互联网广告点击率预估方法的研究刚刚起步,其中深度学习的点击率预估模型主要分为串行结构和并行结构。串行结构主要通过深度神经网络(下称dnn)提取训练数据的高阶特征,并行结构能够融合不同的模型分别进行训练数据的低阶和高阶特征的提取,从而实现互联网广告的点击率预估,该方法提高了在复杂场景下的点击率预估精度。例如,guo等人于2017年5月在ijcai发表了一篇题为“deepfm:a factorization
‑
machine based neural network for ctrprediction”的文章(guo h,tang r,ye y,et al.deepfm:a factorization
‑
machine based neural network for ctr prediction[j].arxiv preprint arxiv:1703.04247,2017.),公开了一种宽线性模型与深度神经网络模型相结合的互联网广告点击率预估方法,首先利用编码模型将稀疏的原始特征编码为因子分解模型所需的数据格式,然后利用因子分解模型对原始特征进行两两交叉组合得到交叉特征向量,并对该特征向量进行线性组合学习,得到特征的相关性,然后利用映射层将高维稀疏的类别特征映射为低维稠密的向量,与其他原始连续特征拼接,输入到多层神经网络中,输出学习到的新特征,最后将两个模型的输出进行拼接,实现点击率预估,得到互联网广告点击率预估结果。该方法完成了数据相关性学习和泛化学习,实现了与原始数据有共性的特征和具有多样性的特征的提取,但是该方法深度模块仅使用两层全连接网络,模型泛化能力不足,无法有效获取原始数据的深层特征,导致点击率预估精度降低。例如,微博张俊林等人于2018年10月提出了deepffm模型,该模型在deepfm模型的基础上使用了ffm代替了fm进行低阶特征的组合。
[0005]
在deepfm和deepffm两个模型中,低阶特征组合部分使用了fm或ffm。fm模型训练速度快,但是效果没有ffm好。而ffm在fm的基础上引入了域,使得ffm的常数量增长,这这参数里在大规模数据在线部署的情况下显然是不能接受的,因此ffm虽然效果好,但是由于参数量太大,难以在线上部署和实现。在高阶特征组合部分都使用了dnn,但dnn使用乘积的方式进行隐式提取特征组合的方式进行高阶特征组合,导致组合所得的高阶特征可解释性差,效果一般。
技术实现要素:
[0006]
本发明为了解决以上至少一种技术缺陷,提供一种基于双线性ffm和多头注意力机制的广告点击率预估方法,有效提升广告点击率预估的效果和可解释性。
[0007]
为解决上述技术问题,本发明的技术方案如下:
[0008]
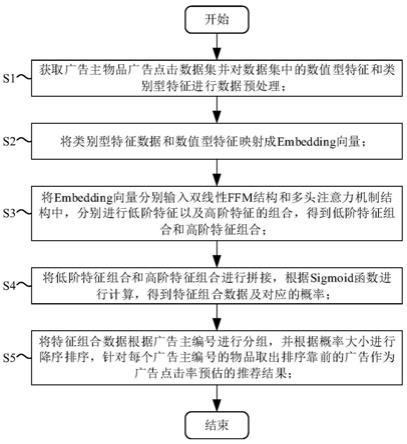
基于双线性ffm和多头注意力机制的广告点击率预估方法,包括以下步骤:
[0009]
s1:获取广告主物品广告点击数据集并对数据集中的数值型特征和类别型特征进行数据预处理。
[0010]
s2:将类别型特征数据和数值型特征映射成embedding向量;
[0011]
s3:将embedding向量分别输入双线性ffm结构和多头注意力机制结构中,分别进行低阶特征以及高阶特征的组合,得到低阶特征组合和高阶特征组合;
[0012]
s4:将低阶特征组合和高阶特征组合进行拼接,根据sigmoid函数进行计算,得到特征组合数据及对应的概率;
[0013]
s5:将特征组合数据根据广告主编号进行分组,并根据概率大小进行降序排序,针对每个广告主编号的物品取出排序靠前的广告作为广告点击率预估的推荐结果。
[0014]
上述方案中采用了双线性ffm模型,实现了在fm的基础上加入少量参数达到了接近ffm的效果,其参数量约是ffm的1/38;针对高阶特征组合部分,采用了多头注意力机制结构代替dnn显式地进行高阶特征组合,通过注意力机制计算得到组合特征向量之间的相关性,提升了本方法的效果和可解释性。
[0015]
其中,在步骤s1中,以criteo数据集作为基础,随机抽取其中部分数据作为广告主物品广告点击数据集,其中,包括用于训练双线性ffm结构和多头注意力机制结构的训练集和用于验证双线性ffm结构和多头注意力机制结构训练结果的验证集。
[0016]
其中,在步骤s1中,数据集包括类别型特征数据和数值型特征,对数据集处理的过程具体为:
[0017]
对类别型特征数据,针对其每个特征采用众数的方法进行缺失值填充;
[0018]
对数值型特征,针对其每个特征采用上一条未缺失的数据来进行填充;并对数值型特征进行标准化处理,从而降低数据集的方差。
[0019]
其中,在步骤s2中,首先将类别型特征数据在双线性ffm结构中转换成独热编码向量,再通过矩阵w
embedding
进行映射成低秩稠密的向量并与数值型特征向量拼接组成embedding向量,具体表示为:
[0020]
o
i
=onehot(data)
[0021]
e
i
=o
i
·
w
embedding
[0022]
其中,data表示类别型特征数据;onehot()表示独热编码处理;e
i
表示第i个
embedding向量;w
embedding
表示embedding矩阵。
[0023]
其中,在所述步骤s3中,embedding向量e
i
的低阶特征组合y
low
具体表示为:
[0024][0025]
其中,w0是偏置项;x
i
、x
j
分别是第i个和第j个特征向量,w
i
是一维特征向量e
i
的权重系数;s
i
、s
j
分别表示特征向量x
i
、x
j
的隐向量;w为隐向量s
i
、s
j
共享参数矩阵,用于表示特征向量x
i
、x
i
交互的信息。
[0026]
其中,在所述步骤s3中,共享参数矩阵w的构造方法有如下三种:
[0027]
1)所有类别型特征数据共享一个参数矩阵,则参数量为k
×
k,其中k为嵌入向量的维度;
[0028]
2)将类别型特征数据划分为多个域,每个域中的类别型特征数据共享一个参数矩阵,则参数量为p
×
k
×
k,其中p为域的数量;
[0029]
3)将类别型特征数据划分为多个域,每两个域的类别型特征数据共享一个参数矩阵,则参数量为p
×
p
×
k
×
k。
[0030]
其中,在步骤s3中,高阶特征组合的步骤具体包括以下步骤:
[0031]
在多头注意力机制结构中,随机初始化三个满足高斯分布的矩阵,分别为查询权重矩阵w
query
、键查询矩阵w
key
、值权重矩阵w
value
并将这三个矩阵作为特征交叉层中注意力子空间h中的转换向量将embedding向量e
i
经过的注意力子空间h的转换向量将e1,e2,
…
,e
i
分别映射成向量组k=[k1,k2,
…
,k
i
]、v=[v1,v2,
…
,v
i
]以及向量q
i
;
[0032]
计算向量q
i
分别与向量组k1,k2,
…
,k
i
进行相似度计算,将相似度进行归一化后得到注意力权重
[0033]
将注意力权重与向量组v1,v2,
…
,v
i
进行加权求和,得到embedding向量e
i
在注意力子空间h下的组合特征向量
[0034]
将组合特征向量进行拼接操作,得到嵌入特征向量e
i
在多头自注意力机制下的组合特征向量
[0035]
在多头注意力机制结构中迭加多层特征交叉层,对组合特征向量进行迭加,得到高阶特征组合y
high
。
[0036]
其中,在步骤s3中,在多头注意力机制结构的每个特征交叉层,均设置有残差连接层,其用于保留低阶特征,使得高阶特征组合中保留有不同阶次的特征。
[0037]
其中,步骤s4中,通过sigmoid函数进行计算的表达式具体为:
[0038]
y=sig moid(y
low
y
high
)
[0039]
其中,y表示特征组合数据及对应的概率。
[0040]
其中,步骤s5中,特征组合数据的输出采用广告召回表的形式输出,其以广告主编号进行分组,并根据概率大小进行降序排序,针对每个广告主编号的物品取出排序前k个广告作为广告点击率预估的推荐结果。
[0041]
上述方案中,本方案采用了采用了双线性ffm模型,双线性ffm是在fm的基础上引
入了共享参数矩阵来表征特征之间交互的信息,从而实现了在fm的基础上加入少量参数达到了接近ffm的效果;针对高阶特征组合部分,采用了多头注意力机制结构代替dnn显式地进行高阶特征组合,通过注意力机制计算得到组合特征向量之间的相关性,提升了本方法的效果和可解释性,为营销人员制定广告营销策略提供了理论依据和参考基础。
[0042]
与现有技术相比,本发明技术方案的有益效果是:
[0043]
本发明提出了基于双线性ffm和多头注意力机制的广告点击率预估方法,采用了双线性ffm模型,实现了在fm的基础上加入少量参数达到了接近ffm的效果;针对高阶特征组合部分,采用了多头注意力机制结构代替dnn显式地进行高阶特征组合,通过注意力机制计算得到组合特征向量之间的相关性,提升了本方法的效果和可解释性。
附图说明
[0044]
图1为本发明所述方法的流程示意图;
[0045]
图2为本发明一实施例中基于多头自注意力机制的特征组合过程示意图;
[0046]
图3为本发明一实施例中多头注意力机制网络示意图;
[0047]
图4为本发明一实施例中本方法所述模型总体结构图;
[0048]
图5为本发明一实施例中广告召回与排序流程图。
具体实施方式
[0049]
附图仅用于示例性说明,不能理解为对本专利的限制;
[0050]
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
[0051]
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0052]
下面结合附图和实施例对本发明的技术方案做进一步的说明。
[0053]
实施例1
[0054]
如图1所述,基于双线性ffm和多头注意力机制的广告点击率预估方法,包括以下步骤:
[0055]
s1:获取广告主物品广告点击数据集并对数据集中的数值型特征和类别型特征进行数据预处理;
[0056]
s2:将类别型特征数据和数值型特征映射成embedding向量;
[0057]
s3:将embedding向量分别输入双线性ffm结构和多头注意力机制结构中,分别进行低阶特征以及高阶特征的组合,得到低阶特征组合和高阶特征组合;
[0058]
s4:将低阶特征组合和高阶特征组合进行拼接,根据sigmoid函数进行计算,得到特征组合数据及对应的概率;
[0059]
s5:将特征组合数据根据广告主编号进行分组,并根据概率大小进行降序排序,针对每个广告主编号的物品取出排序靠前的广告作为广告点击率预估的推荐结果。
[0060]
在具体实施过程中,本方法采用了双线性ffm模型,实现了在fm的基础上加入少量参数达到了接近ffm的效果,其参数量约是ffm的1/38;针对高阶特征组合部分,采用了多头注意力机制结构代替dnn显式地进行高阶特征组合,通过注意力机制计算得到组合特征向
量之间的相关性,提升了本方法的效果和可解释性。
[0061]
更具体的,在步骤s1中,以criteo数据集作为基础,随机抽取其中部分数据作为广告主物品广告点击数据集,其中,包括用于训练双线性ffm结构和多头注意力机制结构的训练集和用于验证双线性ffm结构和多头注意力机制结构训练结果的验证集。
[0062]
在具体实施过程中,以criteo数据集作为本发明的数据集,该数据是点击率预估领域的工业级数据集。它包括45840617条数据,所有的数据都具有39个特征,每条数据包含标签值label。在39个特征中,有13个为数值型特征表示,取值范围为i1~i13,另外26个为类别型特征表示为c1~c26。其中,标签值label值表示该条广告是否被点击,1表示点击,0表示没有被点击。因为经过了脱敏和加密处理,所有的数据均为数字,且不能明显看出每个特征所表示的具体含义。
[0063]
更具体的,在步骤s1中,对数据集处理的过程具体为:
[0064]
类别型特征数据,针对其每个特征采用众数的方法进行缺失值填充;
[0065]
对数值型特征,针对其每个特征采用上一条未缺失的数据来进行填充;并对数值型特征进行标准化处理,从而降低数据集的方差。
[0066]
在具体实施过程中,先随机抽取数据集中2000万条数据作为实验对象,按8:2的比例进行划分训练集和验证集,其中1600万条数据作为训练集参与训练,400万条数据进行验证本方法的表现。接着,对数值型特征i1~i13和类别型特征c1~c26给予不同的填充方法。针对数值型特征,采用上一条未缺失的数据进行填充。针对类别型型特征,对每一个特征采用众数的方法来填充,即找到每个特征的中出现次数最多的值,如果存在几个众数的情况,则选择第一个众数。
[0067]
更具体的,在步骤s2中,首先将类别型特征数据在双线性ffm结构中转换成独热编码向量,再通过矩阵w
embedding
进行映射成低秩稠密的向量并与数值型特征向量拼接组成embedding向量,具体表示为:
[0068]
o
i
=onehot(data)
[0069]
e
i
=o
i
·
w
embedding
[0070]
其中,data表示类别型特征数据;onehot()表示独热编码处理;e
i
表示第i个embedding向量;w
enbedding
表示embedding矩阵。
[0071]
更具体的,在所述步骤s3中,embedding向量e
i
的低阶特征组合y
low
具体表示为:
[0072][0073]
其中,w0是偏置项;x
i
、x
j
分别是第i个和第j个特征向量,w
i
是一维特征向量e
i
的权重系数;s
i
、s
j
分别表示特征向量x
i
、x
j
的隐向量;w为隐向量s
i
、s
j
共享参数矩阵,用于表示特征向量x
i
、x
j
交互的信息。
[0074]
在具体实施过程中,双线性ffm是在fm的基础上引入了共享参数矩阵,使原来的二权项权重由s
i
s
j
变为s
i
ws
i
,进而可以表征特征之间交互的信息,从而实现了在fm的基础上加入少量参数达到了接近ffm的效果。
[0075]
更具体的,在所述步骤s3中,共享参数矩阵w的构造方法有如下三种:
[0076]
1)所有类别型特征数据共享一个参数矩阵,则参数量为k
×
k,其中k为嵌入向量的维度;
[0077]
2)将类别型特征数据划分为多个域,每个域中的类别型特征数据共享一个参数矩阵,则参数量为p
×
k
×
k,其中p为域的数量;
[0078]
3)将类别型特征数据划分为多个域,每两个域的类别型特征数据共享一个参数矩阵,则参数量为p
×
p
×
k
×
k。
[0079]
更具体的,在步骤s3中,如图2所示,高阶特征组合的步骤具体包括以下步骤:
[0080]
在多头注意力机制结构中,随机初始化三个满足高斯分布的矩阵,分别为查询权重矩阵w
query
、键查询矩阵w
key
、值权重矩阵w
value
并将这三个矩阵作为特征交叉层中注意力子空间h中的转换向量将embedding向量e
i
经过的注意力子空间h的转换向量将e1,e2,
…
,e
i
分别映射成向量组k=[k1,k2,
…
,k
i
]、v=[v1,v2,
…
,v
i
]以及向量q
i
;
[0081]
计算向量q
i
分别与向量组k1,k2,
…
,k
i
进行相似度计算,将相似度进行归一化后得到注意力权重
[0082]
将注意力权重与向量组v1,v2,
…
,v
i
进行加权求和,得到embedding向量e
i
在注意力子空间h下的组合特征向量
[0083]
将组合特征向量进行拼接操作,得到嵌入特征向量e
i
在多头自注意力机制下的组合特征向量
[0084]
在多头注意力机制结构中迭加多层特征交叉层,对组合特征向量进行迭加,得到高阶特征组合y
high
。
[0085]
在具体实施过程中,上述进行高阶特征组合的实施中,其数学表达形式如下:
[0086][0087][0088][0089][0090]
式中,为注意力子空间h下的归一化权重分数,φ
(h)
(x)为可选的相似度计算函数。
[0091]
在具体实施过程中,φ
(h)
(x)可以选择jaccard相关系数,余弦相似度,皮尔森相关系数,欧几里德距离等方法。本发明选择向量内积的方式进行相似度计算,表达式如下:
[0092]
φ
(h)
(q
i
,k
i
)=<q
i
,k
i
>
[0093]
接着,将注意力权重与向量组v1,v2,
…
,v
i
进行加权求和,得到向量e
i
在注意力子空间h下的组合特征向量具体表示为:
[0094][0095]
最后,将向量进行拼接操作,得到多头自注意力机制下的组合特征向量
[0096]
[0097]
上述过程只是在一层交互层中产生组合特征向量的过程,要想组合高阶特征,必须通过迭代多层交互层进行连接。具体如下:
[0098]
如图3所示,
⑥
是特征组合层,其工作过程如上述多头自注意力机制下的组合特征向量的产生过程一样。通过迭代多层interacting layer,即可得到高阶组合特征。更具体的,在步骤s3中,在多头注意力机制结构的每个特征交叉层,均设置有残差连接层,如图3中
⑤
所示,表示残差连接,其作用是保留低阶特征,使得在组合高阶特征时能够得到不同阶次的特征。
[0099]
进一步地,上述过程表示如下:
[0100][0101][0102]
l
i 1=
σ(l
i
b)
[0103]
其中表示经过残差连接和交互层进行组合的组合特征向量,l
i
表示第i层所组合得到的高阶特征向量组。l
i 1
表示第i 1层所组合得到的高阶特征向量组。
[0104]
在具体实施过程中,如图4所示,低阶特征组合的wide部分采用所述的双线性ffm结构,高阶特征组合的deep部分采用所述的多头自注意力机制网络结构。假设ffm结构输出的低阶特征为y
low
,多头自注意力机制网络结构输出的高阶特征为y
high
。将y
low
和y
low
进行拼接,输入到sigmoid函数里面,得到特征组合及其概率。所述过程的数学表示如下:
[0105]
y=sig moid(y
low
y
high
)
[0106]
其中,y表示特征组合数据及对应的概率。
[0107]
更具体的,步骤s5中,如图5所示,特征组合数据的输出采用广告召回表的形式输出,其以广告主编号进行分组,并根据概率大小进行降序排序,针对每个广告主编号的物品取出排序前k个广告作为广告点击率预估的推荐结果。
[0108]
在具体实施过程中,本方案采用了采用了双线性ffm模型,双线性ffm是在fm的基础上引入了共享参数矩阵来表征特征之间交互的信息,得到更多有效的二阶组合特征,使得模型的“记忆能力”得到增强,从而提高广告点击率预测的准确度,实现了在fm的基础上加入少量参数达到了接近ffm的效果;针对高阶特征组合部分,采用了多头注意力机制结构代替dnn显式地进行高阶特征组合,通过注意力机制计算得到组合特征向量之间的相关性,提升了本方法的效果和可解释性,为营销人员制定广告营销策略提供了理论依据和参考基础。
[0109]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。