1.本发明涉及频繁模式挖掘算法以及数据流挖掘系统。
2.高效用项集挖掘是频繁模式挖掘的一个重要分支。
背景技术:
3.频繁项集挖掘是数据挖掘领域的一个重要分支,它能够从数据集的所有事务中挖掘出出现频率超出用户设置阈值的项集。而随着频繁项集的广泛应用,人们发现,与频繁项集相比,一些非频繁项集能够创造更高的价值,针对该问题,学者提出了高效用项集挖掘的概念,高效用项集克服了频繁挖掘项集中没有考虑的出现频次,价格,利润,地区分布等等数据项权重信息的缺陷,其通过综合效用指标来评估项集的重要性。
4.目前模式增长的方法在数据流的高效用项集挖掘算法中较为有效,hum
‑
ut算法提出为滑动窗口中的数据建立全局头表,估算数据流效用值,利用全局头表和全局效用树挖掘高效用项集,但全局头表和效用树中仍包含了大量冗余数据项和低效用项集。针对该问题,ihum
‑
ut算法通过压缩全局头表大小来提高时间效率,shugrowth算法通过构建shu
‑
tree结构来优化挖掘过程,huisw算法则是通过构建huil
‑
tree来优化全局头表。
5.然而过多的候选项与冗余项常常导致所构造的数据结构(尤其是树形结构)的空间复杂性高,这使得挖掘过程中频繁递归,从而导致内存溢出并降低了算法效率。因此,修剪和过滤冗余项集是当前算法的主要优化目标之一。
6.在基于滑动窗口技术的算法中更多地是去构建更好的全局结构。当前的算法忽略了长期的历史数据对实际数据分析中未来数据流的挖掘具有一定的指导意义,这可以帮助算法有效地过滤冗余项和候选项。同时当前基于分布式框架下的高效用项集挖掘算法也较为稀缺,随着当前数据流越来越庞大的前提下,提高数据流挖掘算法的实时性与效率是十分具有挑战性的。
技术实现要素:
7.当前的模式增长算法不可避免地存在候选项集、冗余项过多,低效用数据无用化处理等问题,往往导致构建的高效用树型结构的空间复杂度较高,使得在挖掘过程中频繁递归创建子树,最终发生内存溢出、算法效率低下等问题。因此如何有效地筛选候选项集成为高效用项集挖掘算法的主要优化目标之一。
8.随着当前分布式系统与数据流引擎的发展,在处理大规模数据流的问题上已经有了较多的解决方案,其中不乏一些优秀的数据流引擎(spark streaming,storm,flink)。在实际的数据挖掘与分析过程中,长时间历史数据分析对于未来数据流的挖掘具备一定的参考价值,借助分布式的数据处理框架,因此本发明考虑通过分布式的挖掘任务设计,在有效的挖掘历史数据的同时,辅助优化当前数据流挖掘算法,实现单机向分布式的改造,降低挖掘的时间成本与存储成本,对大数据集表现出较好的可扩展性与稳定性,在此基础上本发明提出了基于历史效用表剪枝的数据流高效用项集挖掘算法。
9.本发明设计了一种分布式的高效用项集挖掘系统,在稳定进行历史挖掘数据的分析的同时,保证了当前数据流的高效用项集挖掘的实时性。同时本发明有效利用了历史挖掘数据的结果,构建了历史效用值表,并通过该表有效减少了数据流挖掘算法的冗余项,提高了数据流挖掘算法的效率。
10.为了实现上述的目的,本发明给出的方案是:
11.步骤1、历史效用值表的创建与更新;
12.步骤2、全局头表与全局树的构建,更新,优化;
13.步骤3、在优化后的全局数据结构上进行高效用项集挖掘;
14.步骤4、分布式的高效用项集挖掘系统;
15.有益效果
16.本发明在优化后的全局头表减少了效用值较低的数据项,假设当前有n个数据项,tn个事务,事务的平均长度为l,窗口大小为winsize,批大小为batchsize,在使用所有数据项时空间复杂度会达到o(winsize*batchsize*l),目前窗口大小和批大小保持不变的情况下,通过减少低效用的数据项可以减少事务的平均长度,同时也有效减少了全局树中的子树生成数量与递归次数,在此基础上有效提高了算法的时间与空间复杂度。
17.本发明在四类经典的挖掘数据集上进行对比实验,观察到了性能的显著提升。这也证实了历史效用值表的构建与分布式的高效用项集挖掘系统的构建对算法效率的提升。其针对目前数据流上的高效用项集挖掘算法的效率提升,保证算法的实时性,以及拓宽高效用项集挖掘算法的应用具有重大意义。
附图说明
18.附图是用来提动对本发明的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但不构成对本发明的限制。在附图中:
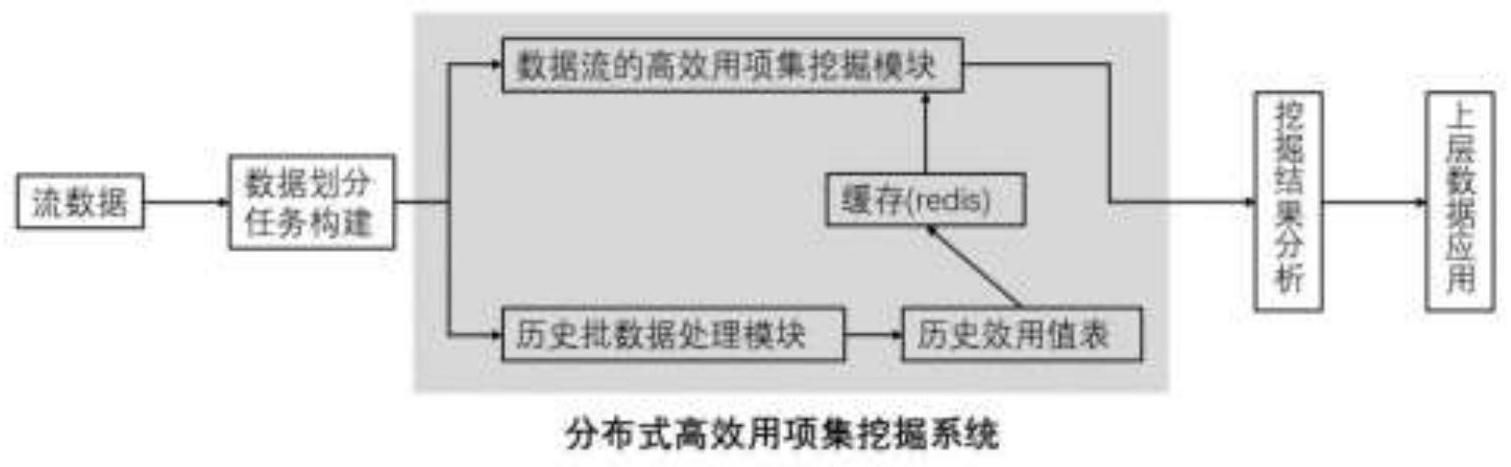
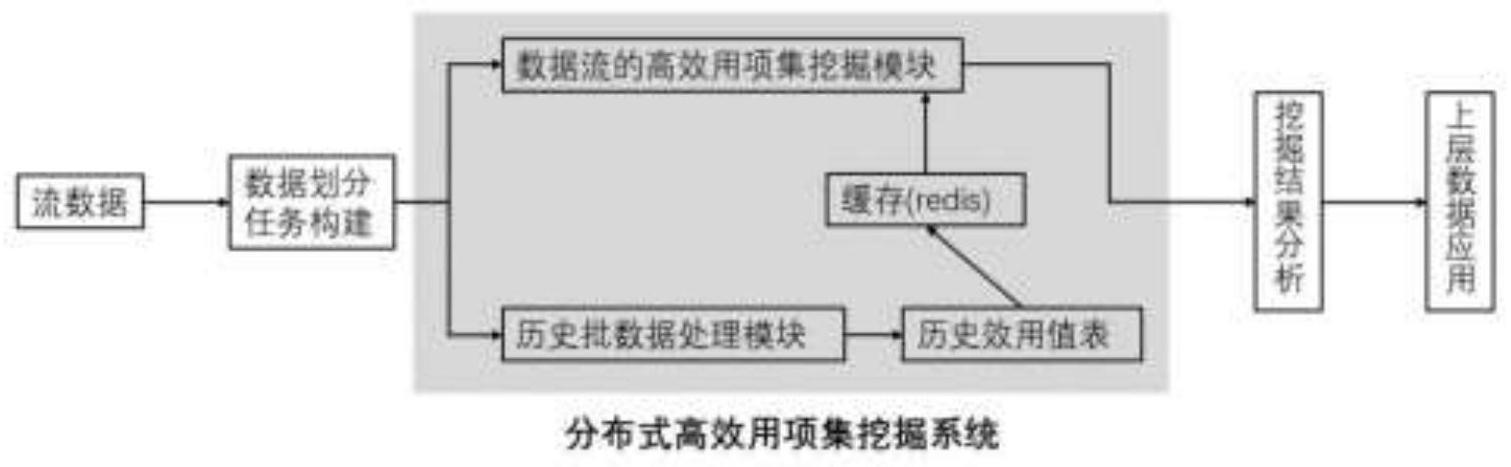
19.图1为分布式的高效用项集挖掘系统结构图;
20.图2为基于历史效用表剪枝的数据流高效用项集挖掘算法的技术路线图;
21.图3为步骤一历史效用值表创建、更新流程图;
22.图4为步骤二全局头表全局树的构建、更新、优化流程图;
23.图5为步骤三优化后的高效用项集挖掘说明图;
具体实施方式
24.为了使本发明实施例的目的、技术方案和优点更加清楚,下面将结合附图对本发明的具体实施方式进行清楚、完整的描述。应当理解的是,此处所描述的具体实施方法仅用于说明和解释本发明,并不用于限制本发明。
25.本发明系统实施过程如图2所示:
26.步骤1、历史效用值表的创建与更新;
27.步骤2、全局头表与全局树的构建,更新,优化;
28.步骤3、在优化后的全局数据结构上进行高效用项集挖掘;
29.步骤4、分布式的高效用项集挖掘系统;
30.各个步骤详述如下。
31.步骤1:历史效用值表的创建与更新,如图3所示
32.1.1历史效用值表的初始化
33.在当前缓存内没有效用值表时进行初始化,并根据不同阈值构建不同的历史效用值表,而每一个表项的设计如下:
34.item_index:表示当前数据项的索引
35.item_profit:表示当前数据项的外部效用值
36.item_utility:表示当前数据项的效用值均值
37.item_level:表示当前数据项的等级(在挖掘过程中用于参考)
38.根据上述数据项初始化得到历史效用值表,其中初始化后每一项的item_index为其数据项名称,item_profit更新为外部效用值,item_utility初始化为0,item_level也初始化为0,完成后的历史效用值表将继续用于步骤1.2中。
39.1.2历史效用值表的创建
40.在完成第一个滑动窗口的挖掘后,根据挖掘结果与计算的效用值均值,更新数据项中的item_utility,明显低于窗口事务权重效用值的记为低效用项集,将其item_level标记为
‑
1,而挖掘得到高效用多项集的item_level标记为2,得到的高效用一项集标记为1,以上的数据标记与更新均在步骤1.1所初始化的历史效用值表的基础上。
41.在完成第一次初始化与创建后,将数据项索引作为键,其余的项作为值保存至缓存中,该历史效用值表的名称为该事务项集的名称与最小效用阈值,步骤1.1与步骤1.2所产生的历史效用值表只对应某个数据集下某个最小效用阈值。
42.1.3历史效用值表的更新
43.向前滑动一个窗口并完成挖掘过程后,仍根据创建时的规则更新item_utility与item_level两项,所需要更新的历史效用值表根据缓存中的数据集名称与最小效用值阈值得到。
44.步骤2:全局头表与全局树的构建,更新,优化,如图4所示
45.2.1全局头表与全局树的初始化
46.全局头表在初始化的过程中需要包含所有数据项,头表中的每一个表项均为数据项在当前批次中的事务效用值均值(twu)。全局树由多个tn
‑
tree子树组成,tn
‑
tree中有三类结点,分别为:根结点(root)、一般结点、尾结点。根结点是一个空结点,它用于合并所有子结点,一般结点、尾结点中包含当前的数据项名称,父亲结点的指针,子结点的指针。尾结点比较特殊,除了保存上述的内容外,还需要保存当前事务的所有效用值,由二维数组构成。根据窗口大小需要创建n个数组,每个数组中根据顺序保存各数据项的效用值。步骤2.1中需要生成一个带有所有数据项的空全局头表与全局树根root。
47.2.2全局头表与全局树的构建更新
48.根据窗口大小,批大小依次读入数据流并填充全局头表,并根据上述tn
‑
tree规则构建子树并合并至全局树上,此处的全局头表为步骤2.1中初始化的空表,合并的全局树为2.1中产生的根节点root。需要注意的是在树型结构中具备相同前缀的事务项共用相同的树结点。在窗口向前滑动后,进行全局头表与全局树的更新,移除最旧批次的数据并加入最新批次的数据,仍根据上述规则进行头表与树的更新。
49.2.3全局头表与全局树的优化
50.当缓存中具备当前挖掘窗口中对应的历史效用值表时,需要根据历史效用值表的数据对全局头表进行重构,主要依据item_level来对全局头表进行优化。而这里的历史效用值表则主要由步骤1.1,步骤1.2产生,同时在滑动窗口向前滑动时需要触发步骤1.3对历史效用值表进行更新。
51.算法针对绝对的高效用数据项(item_level=1)以及潜在的高效用数据项(item_level=2)将其排序至表的头部,在后文构建树的过程中将优先进行挖掘,针对普通数据项(item_level=0)则仍按照字典序进行排序,而低效用的数据项(item_level=
‑
1)则做删减处理。为了尽可能地保证算法地查全率,对于低效用的数据项(item_level=
‑
1)会计算twu值,若明显高于当前窗口地最小效用值,仍会保留。同时根据全局头表的优化结果来调整全局树的结构,算法会针对绝对的高效用数据项(item_level=1)、潜在的高效用数据项(item_level=2)调整至尾结点优先进行挖掘。
52.步骤3:在优化后的全局数据结构上进行高效用项集挖掘,如图5所示
53.3.1挖掘前预处理
54.挖掘首先需要读入一个完整滑动窗口的数据,并根据上述步骤2.3对当前滑动窗口中的全局树以及全局头表进行优化,完成后对每一个叶子结点添加效用缓存值,并在头表中建立对应树结点的link指针,根据顺序逐项挖掘。
55.3.2实际挖掘过程
56.根据步骤3.1得到的全局数据结构以及挖掘顺序,可以得到某一个数据项的twu值,效用缓存值以及全局树中结点的位置和事务路径信息,且因为挖掘是通过尾结点表来进行,因此数据项对应的均为叶子结点,在完成挖掘后该数据项结点会将效用缓存值上移至父结点。
57.开始挖掘后,当该数据项的效用值大于等于最小效用值,那该数据项就是一个高效用一项集;同时只要该数据项的twu值大于等于最小效用值,就为该数据项创建子头表与子树;而该数据项的twu值小于最小效用值,根据twu向下收敛的性质,该数据项的超集也一定不是高效用项集,因此结束该数据项的挖掘。
58.若当前数据项需要创建子头表与子树,读取当前数据项link指针对应结点的效用缓存值,此时也得到了当前数据项所在全局树中的所有路径,读取路径中所有数据项并计算twu值,当twu值大于等于最小效用值时将数据项加入子头表。此时,将当前数据项的效用值作为基效用值加至子树的尾结点上,完成子树的构建,之后递归进行子树,子头表的创建并进行挖掘最终得到当前滑动窗口所有的高效用项集。
59.在完成挖掘工作后,滑动窗口向前滑动,此时需要执行步骤1.3进行历史效用值表的更新以及,步骤2.2,步骤2.3对全局数据结构进行更新并重构优化。
60.步骤4:分布式的高效用项集挖掘系统构建,如图1所示
61.整个高效用项集挖掘系统将分为三个模块:历史批数据处理模块,主要负责步骤1中的相关处理,由worker1负责;数据流处理模块,主要负责步骤2,步骤3中的相关处理,由worker2负责;历史效用值表缓存模块,用轻量的缓存系统(redis)存储历史批数据的处理结果——历史效用值表,用于优化剪枝数据流中的高效用项集的搜索空间,从而提高高效用项集挖掘算法的效率。
62.创新点
63.本发明基于历史效用值表优化了当前的数据流高效用项集挖掘算法,并构建了分布式的高效用项集挖掘系统。由于阻尼窗口与界标窗口的数据流处理技术对数据仓库与消息队列造成极大的压力,本发明对数据流的处理采用的是滑动窗口技术,更加注重实时性的处理。在此基础上运用分布式的框架,将任务拆分为历史数据处理与数据流处理两个部分,在稳定进行历史挖掘数据的分析的同时,保证了当前数据流的高效用项集挖掘的实时性,且通过轻量级的缓存进行数据存储,减轻了数据仓库的存储压力,同时根据历史数据的参考性有效剪枝了数据流挖掘的搜索空间,提高了数据流挖掘算法的整体效率。
64.本发明系统在retail、connect、tlc_trip等数据集中有很好的表现,在保证高查全率的前提下,提高了挖掘算法的时间与空间效率。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。