一种pss快速搜索方法、装置及存储介质
技术领域
1.本发明涉及通信技术领域,具体为一种pss快速搜索方法、装置及存储介质。
背景技术:
2.现有pss搜索主要采用传统的pss时域相关搜索算法,具体过程如下:
3.1、将3个pss本地频域基序列通过ifft变换为pss本地时域基序列,并采用降采样算法对pss本地时域基序列进行处理,将处理后的pss本地时域基序列保存在ue中,其中,ifft为快速傅里叶逆变换,ue为用户终端;
4.2、分别使用3个pss本地时域基序列与ue接收的时域数据进行滑动相关,获得滑动相关值序列;
5.3、利用上述滑动相关值序列,分别求出pss相关值序列中的最大值及其最大值位置;
6.4、比较上述3个pss最大值,求出nid2值和pss起始符号位。
7.然而在ue下行同步或小区搜索过程中,pss搜索需要处理同步时间窗内所有的时域数据,以5g nr 100m带宽、30khz子载波间隔、同步时间窗为20ms为例,其需处理的时域数据量为61440*2*10*2,数据处理量非常大。由于现有pss的搜索过程和其面对的大数据量处理,导致pss搜索耗时过长,使得在载波添加、领区测量等需要ue小区搜索的使用场景中,小区搜索时间过长,因此亟需一种能够快速完成pss搜索的方法、装置及存储介质。
技术实现要素:
8.本发明的目的之一在于提供一种pss快速搜索方法,以解决现有技术中pss搜索耗时过长的技术问题。
9.本发明提供的基础方案一:一种pss快速搜索方法,包括以下内容:
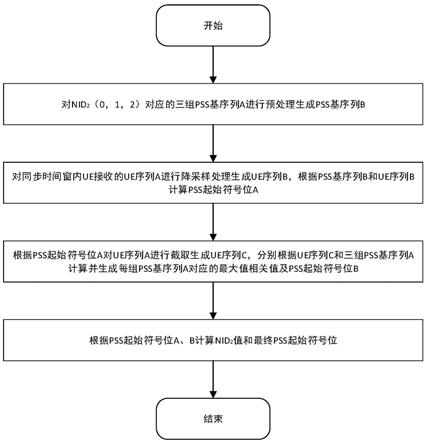
10.s1:对nid2(0、1、2)对应的三组pss基序列a进行预处理生成pss基序列b;
11.s2:对同步时间窗内ue接收的ue序列a进行降采样处理生成ue序列b,根据pss基序列b和ue序列b计算pss起始符号位a;
12.s3:根据pss起始符号位a对ue序列a进行截取生成ue序列c,分别根据ue序列c和三组pss基序列a计算并生成每组pss基序列a对应的最大相关值及pss起始符号位b;
13.s4:根据pss起始符号位a、b计算nid2值和最终的pss起始符号位。
14.基础方案一的有益效果:
15.本方案中,对pss搜索过程进行改进,通过s1整合pss基序列a获得pss基序列b,再通过s2对ue序列a进行处理获得ue序列b,结合pss基序列b进行pss的粗搜索,通过pss粗搜索进行大数据量处理,从而得知pss起始符号位的大致位置。再通过s3根据粗搜索结果对ue序列a进行处理获得ue序列c,结合三组pss基序列a进行pss的精搜索,通过pss精搜索进行局部数据的计算,最终通过s4精确pss起始符号位以及nid2值。
16.本方案通过pss粗搜索对大数据量进行处理,对pss起始符号位的大致位置进行确
定,后续pss精搜索只需对少量数据进行处理便可精确pss起始符号位,与现有pss搜索过程相比,本方案只需一个基序列的处理和三个短序列的处理,搜索过程更为快速,能够有效降低pss搜索耗时,缩短小区搜索时间。
17.进一步,s1中的预处理包括以下内容:对三组pss基序列a进行合并处理,合并处理包括:对三组pss基序列a进行求和。
18.有益效果:通过求和的方式,对三组pss基序列a进行合并,从而减少后续对pss基序列的处理过程,降低计算量。
19.进一步,s1中的预处理包括以下内容:
20.对pss基序列a进行降采样处理,降采样处理包括:获取降采样倍数,根据降采样倍数对pss基序列a进行降采样;
21.s2中对ue序列a采用相同的降采样倍数进行降采样处理。
22.有益效果:通过降采样处理,降低后续处理计算的复杂度,对pss基序列a和ue序列a采用相同降采样倍数的降采样处理,使得两序列数据统一,便于后续进行相关处理。
23.进一步,s2中根据pss基序列b和ue序列b计算pss起始符号位a,包括以下内容:
24.根据pss基序列b和ue序列b滑动相关生成pss相关值序列a,
25.搜索pss相关值序列a生成pss起始符号位a。
26.有益效果:通过滑动相关生成pss相关值序列a,以此搜索到pss起始符号位a,即搜索到最终pss起始符号位的大致位置。
27.进一步,s3中根据pss起始符号位a对ue序列a进行截取生成ue序列c,包括以下内容:
28.根据pss起始符号位a和降采样倍数计算生成截取位;
29.根据单位时域长度和降采样倍数计算生成截取长度;
30.根据截取位和截取长度在ue序列a对应位置截取对应数据长度作为ue序列c。
31.有益效果:单位时域长度是指一个时域符号的数据长度,通过pss起始符号位a和降采样倍数确定最终起始符号位在ue序列a中的大致位置,通过单位时域长度和降采样倍数在大致位置截取一定数据长度的序列数据,即ue序列c。通过截取ue序列a,缩短pss搜索处理的数据量,从而降低pss搜索耗时。
32.进一步,s3中分别根据ue序列c和三组pss基序列a计算并生成每组pss基序列a对应的最大相关值及pss起始符号位b,包括以下内容:
33.三组pss基序列a分别为x0(n)、x1(n)、x2(n),分别根据x0(n)、x1(n)、x2(n)和ue序列c滑动相关生成三组pss相关值序列b;
34.搜索各pss相关值序列b的最大相关值及对应的pss起始符号位b。
35.有益效果:通过滑动相关生成pss相关值序列b,以此计算最大相关值,并搜索到pss起始符号位b。
36.进一步,s4中根据pss起始符号位a、b计算nid2值和最终的pss起始符号位,包括以下内容:
37.比较s3中的最大相关值,将数值最大的最大相关值对应的pss起始符号位b作为pss起始符号位c;
38.根据pss起始符号位a、c和降采样倍数计算生成最终的pss起始符号位;
39.根据数值最大的最大相关值计算生成nid2值。
40.有益效果:通过比较获得数值最大的最大相关值,从而获得在ue序列c中最终的pss起始符号位的所在位置,结合ue序列c在ue序列a中的位置,计算获得最终的pss起始符号位,并以此计算出nid2值。
41.进一步,还包括以下内容:根据系统采样率和预设采样点生成并存储降采样倍数。
42.有益效果:系统采样率由采集设备决定,预设采样点为pss搜索中的最佳点值,以此计算出最佳降采样倍数,从而进行降采样处理。
43.本发明的目的之二在于提供一种pss快速搜索装置。
44.本发明提供基础方案二:一种pss快速搜索装置,包括处理器和存储器,存储器存储有可读指令,当可读指令被处理器运行时,处理器执行上述pss快速搜索方法。
45.基础方案二的有益效果:
46.本方案通过处理器和存储器的设置,执行上述pss快速搜索方法,通过pss粗搜索对大数据量进行处理,确定pss起始符号位的大致位置,后续pss精搜索只需对少量数据进行处理便可精确pss起始符号位,与现有pss搜索过程相比,本方案只需一个基序列的处理和三个短序列的处理,搜索过程更为快速,能够有效降低pss搜索耗时,缩短小区搜索时间。
47.本发明的目的之三在于提供一种pss快速搜索存储介质。
48.本发明提供基础方案三:一种pss快速搜索存储介质,存储有计算机可读指令,当计算机可读指令被运行时,执行上述pss快速搜索方法。
49.基础方案三的有益效果:
50.本方案通过运行计算机可读指令运行上述pss快速搜索方法,实现通过pss粗搜索对大数据量进行处理,确定pss起始符号位的大致位置,后续pss精搜索只需对少量数据进行处理便可精确pss起始符号位,与现有pss搜索过程相比,本方案只需一个基序列的处理和三个短序列的处理,搜索过程更为快速,能够有效降低pss搜索耗时,缩短小区搜索时间。
附图说明
51.图1为本发明一种pss快速搜索方法、装置及存储介质实施例的流程图。
具体实施方式
52.下面通过具体实施方式进一步详细说明:
53.实施例
54.一种pss快速搜索方法,如附图1所示,包括以下内容:
55.根据系统采样率和预设采样点生成并存储降采样倍数。系统采样率由系统设备决定,预设采样点为提前设定的采样值,在本实施例中预设采样点为256,以系统采样率4096为例,则根据系统采样率和预设采样点计算生成的降采样倍数为16,对降采样倍数进行存储,便于后续直接调用。
56.s1:对nid2(0、1、2)对应的三组pss基序列a进行预处理生成pss基序列b。具体的:
57.在本实施例中,以5g nr为例,根据5g nr协议获取nid2=0,1,2的三组pss基序列,分别为x0[k]、x1[k]、x2[k],其中k=0,1,2...126表示子载波序列,此时pss基序列为频域数据。
[0058]
对pss基序列进行ifft转换,使得pss基序列转换为时域数据,即获得三组pss基序列a,分别为x0(n)、x1(n)、x2(n),其中n=0,1,2...4095。其中,ifft为快速傅里叶逆变换。
[0059]
预处理包括:对三组pss基序列a进行合并处理和降采样处理,在本实施例中,先进行降采样处理再进行合并处理,在其他实施例中,先进行合并处理再进行降采样处理,根据实际情况决定合并处理和降采样处理的先后顺序。
[0060]
对pss基序列a进行降采样处理,降采样处理包括:获取降采样倍数,根据降采样倍数对pss基序列a进行降采样,具体的,分别根据降采样倍数对三组pss基序列a进行降采样处理。
[0061]
合并处理包括:对三组pss基序列a进行求和,在本实施例中,对降采样处理后的三组pss基序列a进行求和,生成pss基序列b,pss基序列b为x
σ
(n),具体根据式(1)对三组pss基序列a进行求和。
[0062]
x
σ
(n)=x0(n
·
n
ds
) x1(n
·
n
ds
) x2(n
·
n
ds
)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0063]
式(1)中,n为时域采样点,n
ds
为降采样倍数,在本实施例中,n=0,1,2...255,n
ds
=16。
[0064]
存储pss基序列a:x0(n)、x1(n)、x2(n)和pss基序列b:x
σ
(n)进行存储。
[0065]
s2:对同步时间窗内ue接收的ue序列a进行降采样处理生成ue序列b,根据pss基序列b和ue序列b计算pss起始符号位a。具体的:
[0066]
获取同步时间窗内ue接收的ue序列a,ue代表用户终端,ue序列a为y(m),根据降采样倍数对ue序列a进行降采样处理生成ue序列b,ue序列b为y
ds
(m)=y(m
·
n
ds
),式中m为时域采样点,ue序列b中m=0,1,2...255,降采样倍数与s1中降采样处理的降采样倍数相同,即n
ds
=16。
[0067]
根据pss基序列b和ue序列b滑动相关生成pss相关值序列a,具体根据式(2)生成pss相关值序列a。
[0068][0069]
式(2)中,m、n为时域采样点,n
l
为基序列降采样后的数据长度,re()表示复数取实部运算,在本实施例中,n
l
=256。
[0070]
搜索pss相关值序列a生成pss起始符号位a。具体的,对pss相关值序列a:y
corrσ
(m)进行搜索,找到最大相关值位置m
max
,即为pss起始符号位a。
[0071]
s3:根据pss起始符号位a对ue序列a进行截取生成ue序列c,分别根据ue序列c和三组pss基序列a计算并生成每组pss基序列a对应的最大相关值及pss起始符号位b。
[0072]
具体的:
[0073]
根据pss起始符号位a和降采样倍数计算生成截取位,截取位为m
max
‑
n
ds
。
[0074]
根据单位时域长度和降采样倍数计算生成截取长度,截取长度为n 2n
ds
,式中n为一个时域数据的单位时域长度。
[0075]
根据截取位和截取长度在ue序列a对应位置截取对应数据长度作为ue序列c,具体的,在ue序列a:y(m)的m
max
‑
n
ds
位置处取n 2n
ds
数据长度的时域数据y
′
(m),即ue序列c为y
′
(m)。
[0076]
分别根据三组pss基序列a:x0(n)、x1(n)、x2(n)和ue序列c滑动相关生成三组pss相
关值序列b,具体分别根据式(3)、(4)、(5)生成pss相关值序列b。
[0077][0078]
式(3)、(4)、(5)中,m=0,1,...,2
·
n
ds
‑
1,n=2
·
n
ds
。
[0079]
y
corr0
(m)表示x0(n)与y
′
(m)滑动相关生成的pss相关值序列,y
corr1
(m)表示x1(n)与y
′
(m)滑动相关生成的pss相关值序列,y
corr2
(m)表示x2(n)与y
′
(m)滑动相关生成的pss相关值序列,即三组pss相关值序列b分别为y
corr0
(m)、y
corr1
(m)、y
corr2
(m)。
[0080]
搜索各pss相关值序列b的最大相关值及对应的pss起始符号位b。具体的,分别对y
corr0
(m)、y
corr1
(m)、y
corr2
(m)进行搜索,找到各pss相关值序列b的最大相关值,及对应的最大相关值位置,最大相关值位置即为pss起始符号位b。最大相关值分别为y
corr0_max
、y
corr1_max
、y
corr2_max
,对应pss起始符号位b分别为m
0_max
、m
1_max
、m
2_max
。
[0081]
s4:根据pss起始符号位a、b计算nid2值和最终的pss起始符号位。具体的:
[0082]
比较s3中的最大相关值,得到最大相关值y
corrx_max
,y
corrx_max
为y
corr0_max
、y
corr1_max
、y
corr2_max
中数值最大的最大相关值。
[0083]
将数值最大的最大相关值对应的pss起始符号位b作为pss起始符号位c,pss起始符号位c为m
x_max
。例如当y
corrx_max
=y
corr0_max
时,y
corr0_max
对应的m
0_max
为pss起始符号位c,即m
x_max
=m
0_max
。
[0084]
根据pss起始符号位a、c和降采样倍数计算生成最终的pss起始符号位,pss起始符号位为:m
max
‑
n
ds
m
x_max
。
[0085]
根据数值最大的最大相关值计算生成nid2值,最大相关值对应的基序列索引即为nid2值。
[0086]
本技术还提供一种pss快速搜索装置,包括处理器和存储器,存储器存储有可读指令,当可读指令被处理器运行时,处理器执行上述pss快速搜索方法。
[0087]
本技术还提供一种pss快速搜索存储介质,存储有计算机可读指令,当计算机可读指令被运行时,执行上述pss快速搜索方法。
[0088]
采用本方案对pss搜索过程进行改进,通过pss粗搜索对大数据量进行处理,确定pss起始符号位的大致位置,再通过pss精搜索对最终pss起始符号位进行精确。与现有技术中需对全部基序列进行处理相比,本方案只需对一个基序列进行滑动相关计算,再进行三次小长度的滑动相关计算,搜索过程更为快速,能够有效降低pss搜索耗时,缩短小区搜索时间,显著提高ue下行同步或小区搜索性能。
[0089]
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本技术给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本技术的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作
出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本技术要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。