技术特征:
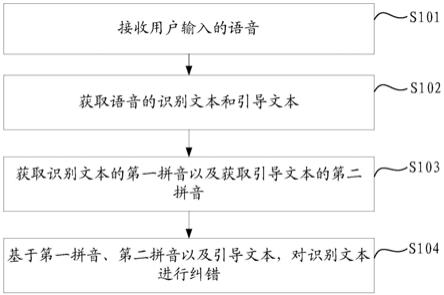
1.一种文本处理方法,其特征在于,应用于电子设备,所述方法包括:接收用户输入的语音;获取所述语音的识别文本和引导文本;获取所述识别文本的第一拼音以及获取所述引导文本的第二拼音;基于所述第一拼音、所述第二拼音以及所述引导文本,对所述识别文本进行纠错。2.根据权利要求1所述的方法,其特征在于,所述获取所述识别文本的第一拼音,包括:将所述识别文本拆分为多个识别文本块,分别获取每一个识别文本块的识别拼音;所述获取所述引导文本的第二拼音,包括:将所述引导文本拆分为多个引导文本块,分别获取每一个引导文本块的引导拼音。3.根据权利要求2所述的方法,其特征在于,所述基于所述第一拼音、所述第二拼音以及所述引导文本,对所述识别文本进行纠错,包括:对于每一个识别文本块的识别拼音,获取所述识别文本块的识别拼音分别与各个引导文本块的引导拼音之间的差异程度;在最小的差异程度大于预设阈值的情况下,依照差异程度由低至高的顺序选择预设数量个差异程度对应的引导文本块;使用选择的引导文本块分别替换所述识别文本中的所述识别文本块,得到多个替换后的识别文本;获取每一个替换后的识别文本的困惑度;选择困惑度最小的替换后的识别文本作为识别文本的纠错版本。4.根据权利要求3所述的方法,其特征在于,所述获取所述识别文本块的识别拼音分别与各个引导文本块的引导拼音之间的差异程度,包括:对于每一个引导文本块的引导拼音,获取所述识别文本块的识别拼音的声母与所述引导文本块的引导拼音的声母之间的第一差异;获取所述识别文本块的识别拼音的韵母与所述引导文本块的引导拼音的韵母之间的第二差异;获取所述识别文本块的识别拼音的声调与所述引导文本块的引导拼音的声调之间的第三差异;获取所述识别文本块的识别拼音与所述引导文本块的引导拼音之间的编辑距离;根据所述第一差异、所述第二差异、所述第三差异以及所述编辑距离获取所述差异程度。5.根据权利要求4所述的方法,其特征在于,所述获取所述识别文本块的识别拼音的声母与所述引导文本块的引导拼音的声母之间的第一差异,包括:获取所述识别文本块的识别拼音中的各个声母的第一向量以及所述引导文本块的引导拼音中的各个声母的第二向量;计算所述第一向量与所述第二向量之间的余弦距离,并作为所述第一差异。6.根据权利要求5所述的方法,其特征在于,所述获取所述识别文本块的识别拼音中的各个声母的第一向量以及所述引导文本块的引导拼音中的各个声母的第二向量,包括:在语音差异确定模型的网络参数中提取所述第一向量和所述第二向量;
其中,所述语音差异确定模型是基于多个样本数据集对待训练模型训练,直至待训练模型中的网络参数收敛后得到的,每一个样本数据集中包括两个样本词汇各自的拼音以及包括两个样本词汇的拼音之间的标注差异。7.根据权利要求4所述的方法,其特征在于,所述获取所述识别文本块的识别拼音的韵母与所述引导文本块的引导拼音的韵母之间的第二差异,包括:获取所述识别文本块的识别拼音中的各个韵母的第三向量以及所述引导文本块的引导拼音中的各个韵母的第四向量;计算所述第三向量与所述第四向量之间的余弦距离,并作为所述第二差异。8.根据权利要求7所述的方法,其特征在于,所述获取所述识别文本块的识别拼音中的各个韵母的第三向量以及所述引导文本块的引导拼音中的各个韵母的第四向量,包括:在语音差异确定模型的网络参数中提取所述第三向量和所述第四向量;其中,所述语音差异确定模型是基于多个样本数据集对待训练模型训练,直至待训练模型中的网络参数收敛后得到的,每一个样本数据集中包括两个样本词汇各自的拼音以及包括两个样本词汇的拼音之间的标注差异。9.根据权利要求4所述的方法,其特征在于,所述获取所述识别文本块的识别拼音的声调与所述引导文本块的引导拼音的声调之间的第三差异,包括:获取所述识别文本块的识别拼音中的各个声调的第五向量以及所述引导文本块的引导拼音中的各个声调的第六向量;计算所述第五向量与所述第六向量之间的余弦距离,并作为所述第三差异。10.根据权利要求9所述的方法,其特征在于,所述获取所述识别文本块的识别拼音中的各个声调的第五向量以及所述引导文本块的引导拼音中的各个声调的第六向量,包括:在语音差异确定模型的网络参数中提取所述第五向量和所述第六向量;其中,所述语音差异确定模型是基于多个样本数据集对待训练模型训练,直至待训练模型中的网络参数收敛后得到的,每一个样本数据集中包括两个样本词汇各自的拼音以及包括两个样本词汇的拼音之间的标注差异。11.根据权利要求6、8或10所述的方法,其特征在于,所述待训练模型包括:统计机器学习模型以及深度学习模型;所述统计机器学习模型包括:logistic回归分析模型、贝叶斯模型以及线性回归模型;所述深度学习模型包括:卷积神经网络cnn,循环神经网络rnn以及深度信念网络dbn。12.一种文本处理装置,其特征在于,应用于电子设备,所述装置包括:接收模块,用于接收用户输入的语音;第一获取模块,用于获取所述语音的识别文本和引导文本;第二获取模块,用于获取所述识别文本的第一拼音,以及,第三获取模块,用于获取所述引导文本的第二拼音;纠错模块,用于基于所述第一拼音、所述第二拼音以及所述引导文本,对所述识别文本进行纠错。13.根据权利要求12所述的装置,其特征在于,所述第二获取模块包括:第一拆分子模块,用于将所述识别文本拆分为多个识别文本块;
第一获取子模块,用于分别获取每一个识别文本块的识别拼音;所述第三获取模块包括:第二拆分子模块,用于将所述引导文本拆分为多个引导文本块;第二获取子模块,用于分别获取每一个引导文本块的引导拼音。14.根据权利要求13所述的装置,其特征在于,所述纠错模块包括:第三获取子模块,用于对于每一个识别文本块的识别拼音,获取所述识别文本块的识别拼音分别与各个引导文本块的引导拼音之间的差异程度;第一选择子模块,用于在最小的差异程度大于预设阈值的情况下,依照差异程度由低至高的顺序选择预设数量个差异程度对应的引导文本块;替换子模块,用于使用选择的引导文本块分别替换所述识别文本中的所述识别文本块,得到多个替换后的识别文本;第四获取子模块,用于获取每一个替换后的识别文本的困惑度;第二选择子模块,用于选择困惑度最小的替换后的识别文本作为识别文本的纠错版本。15.根据权利要求14所述的装置,其特征在于,所述第三获取子模块包括:第一获取单元,用于对于每一个引导文本块的引导拼音,获取所述识别文本块的识别拼音的声母与所述引导文本块的引导拼音的声母之间的第一差异;第二获取单元,用于获取所述识别文本块的识别拼音的韵母与所述引导文本块的引导拼音的韵母之间的第二差异;第三获取单元,用于获取所述识别文本块的识别拼音的声调与所述引导文本块的引导拼音的声调之间的第三差异;第四获取单元,用于获取所述识别文本块的识别拼音与所述引导文本块的引导拼音之间的编辑距离;第五获取单元,用于根据所述第一差异、所述第二差异、所述第三差异以及所述编辑距离获取所述差异程度。16.根据权利要求15所述的装置,其特征在于,所述第一获取单元包括:第一获取子单元,用于获取所述识别文本块的识别拼音中的各个声母的第一向量以及所述引导文本块的引导拼音中的各个声母的第二向量;第一计算子单元,用于计算所述第一向量与所述第二向量之间的余弦距离,并作为所述第一差异。17.根据权利要求16所述的装置,其特征在于,所述第一获取子单元具体用于:在语音差异确定模型的网络参数中提取所述第一向量和所述第二向量;其中,所述语音差异确定模型是基于多个样本数据集对待训练模型训练,直至待训练模型中的网络参数收敛后得到的,每一个样本数据集中包括两个样本词汇各自的拼音以及包括两个样本词汇的拼音之间的标注差异。18.根据权利要求15所述的装置,其特征在于,所述第二获取单元包括:第二获取子单元,用于获取所述识别文本块的识别拼音中的各个韵母的第三向量以及所述引导文本块的引导拼音中的各个韵母的第四向量;第二计算子单元,用于计算所述第三向量与所述第四向量之间的余弦距离,并作为所
述第二差异。19.根据权利要求18所述的装置,其特征在于,所述第二子单元具体用于:在语音差异确定模型的网络参数中提取所述第三向量和所述第四向量;其中,所述语音差异确定模型是基于多个样本数据集对待训练模型训练,直至待训练模型中的网络参数收敛后得到的,每一个样本数据集中包括两个样本词汇各自的拼音以及包括两个样本词汇的拼音之间的标注差异。20.根据权利要求15所述的装置,其特征在于,所述第三获取单元包括:第三获取子单元,用于获取所述识别文本块的识别拼音中的各个声调的第五向量以及所述引导文本块的引导拼音中的各个声调的第六向量;第三计算子单元,用于计算所述第五向量与所述第六向量之间的余弦距离,并作为所述第三差异。21.根据权利要求20所述的装置,其特征在于,所述第三获取子单元具体用于:在语音差异确定模型的网络参数中提取所述第五向量和所述第六向量;其中,所述语音差异确定模型是基于多个样本数据集对待训练模型训练,直至待训练模型中的网络参数收敛后得到的,每一个样本数据集中包括两个样本词汇各自的拼音以及包括两个样本词汇的拼音之间的标注差异。22.根据权利要求17、19或21所述的装置,其特征在于,所述待训练模型包括:统计机器学习模型以及深度学习模型;所述统计机器学习模型包括:logistic回归分析模型、贝叶斯模型以及线性回归模型;所述深度学习模型包括:卷积神经网络cnn,循环神经网络rnn以及深度信念网络dbn。23.一种电子设备,其特征在于,所述电子设备包括:处理器;和存储器,其上存储有可执行代码,当所述可执行代码被执行时,使得所述处理器执行如权利要求1-11中一个或多个所述的文本处理方法。24.一个或多个机器可读介质,其上存储有可执行代码,当所述可执行代码被执行时,使得处理器执行如权利要求1-11中一个或多个所述的文本处理方法。
技术总结
本申请提供了一种文本处理方法及装置。在本申请中,由于用户是基于电子设备输出的引导文本而向电子设备输入语音的,因此,电子设备输出的引导文本的内容与用户在电子设备上输入的语音的内容是有内在逻辑关联以及内在内容关联的,因此,可以基于第一拼音、第二拼音以及引导文本对识别文本进行纠错,以使纠错后的识别文本可以为用户所要表达内容对应的文本,之后可以基于纠错后的识别文本确定识别用户的意图,并根据该咨询意图给用户相应的回复,从而使得电子设备之后向用户输出的回复的内容与用户实际想要的对话内容相符合,进而就可以解决用户的问题,以提高用户体验。以提高用户体验。以提高用户体验。
技术研发人员:李杨 付彬 孙健 唐呈光 赵学敏
受保护的技术使用者:阿里巴巴集团控股有限公司
技术研发日:2020.06.02
技术公布日:2021/12/6
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。