技术特征:
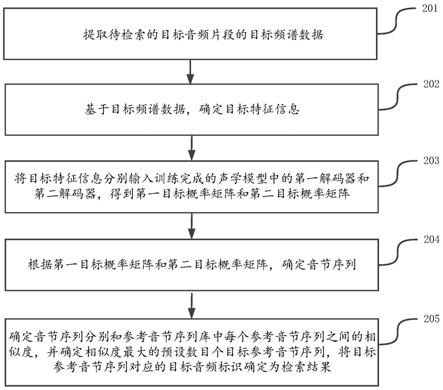
1.一种检索音频的方法,其特征在于,所述方法包括:提取待检索的目标音频片段的目标频谱数据;基于所述目标频谱数据,确定目标特征信息;将所述目标特征信息分别输入训练完成的声学模型中的第一解码器和第二解码器,得到第一目标概率矩阵和第二目标概率矩阵,其中,所述第一解码器和所述第二解码器为不同类型的解码器;根据所述第一目标概率矩阵和所述第二目标概率矩阵,确定音节序列;确定所述音节序列分别和参考音节序列库中每个参考音节序列之间的相似度,并确定相似度最大的预设数目个目标参考音节序列,将所述目标参考音节序列对应的目标音频标识确定为检索结果,其中,所述参考音节序列库中存储有多个参考音节序列以及每个参考音节序列对应的音频标识。2.根据权利要求1所述的方法,其特征在于,所述根据所述第一目标概率矩阵和所述第二目标概率矩阵,确定音节序列,包括:根据所述第一目标概率矩阵和所述第二目标概率矩阵,确定第三目标概率矩阵,其中,所述第三目标概率矩阵由多个向量组成,对于每个向量,所述向量中的每个数值位的取值分别用于表示一个指定音节对应的分值;对于所述第三目标概率矩阵中的每个向量,确定分值最大的目标数值位,将所述目标数值位对应的指定音节确定为所述向量对应的音节;将多个向量分别对应的音节按照所述多个向量在所述第三目标概率矩阵中的顺序进行排序,得到音节序列。3.根据权利要求2所述的方法,其特征在于,所述根据所述第一目标概率矩阵和所述第二目标概率矩阵,确定第三目标概率矩阵,包括:根据所述第一目标概率矩阵、所述第二目标概率矩阵以及第一公式,确定第三目标概率矩阵;所述第一公式为:c=α*loga (1
‑
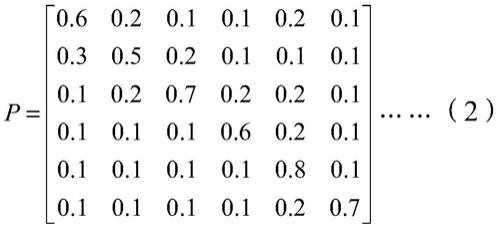
α)*logb;其中,a为所述第一目标概率矩阵,b为所述第二目标概率矩阵,c为所述第三目标概率矩阵,α为预设数值。4.根据权利要求1所述的方法,其特征在于,所述声学模型包括特征提取模块,所述基于所述目标频谱数据,确定目标特征信息,包括:对所述目标频谱数据进行降维处理,得到降维处理后的目标频谱数据;将所述降维处理后的目标频谱数据输入训练完成的声学模型中的特征提取模块,得到目标特征信息。5.根据权利要求4所述的方法,其特征在于,所述特征提取模块包括编码器和自注意学习子模块;所述将所述降维处理后的目标频谱数据输入训练完成的声学模型中的特征提取模块,得到目标特征信息,包括:将所述降维处理后的目标频谱数据输入训练完成的声学模型中的编码器,得到中间特征信息;将所述中间特征信息输入训练完成的声学模型中的自注意学习子模块,得到目标特征
信息。6.一种训练声学模型的方法,其特征在于,所述方法包括:获取样本音频对应的音节序列,作为所述样本音频的基准音节序列;提取所述样本音频的样本频谱数据;基于所述样本频谱数据,确定样本特征信息;将所述样本特征信息和所述基准音节序列,输入所述初始声学模型中的第一解码器和第二解码器,得到第一样本概率矩阵和第二样本概率矩阵,其中,所述第一解码器和所述第二解码器为不同类型的解码器;根据所述第一样本概率矩阵和所述第二样本概率矩阵,确定损失信息;基于所述损失信息对所述初始声学模型进行调参;若满足预设的训练结束条件,则将调参后的初始声学模型确定为训练完成的声学模型;若不满足预设的训练结束条件,则继续基于其他样本音频对调参后的初始声学模型进行调参。7.根据权利要求6所述的方法,其特征在于,所述根据所述第一样本概率矩阵和所述第二样本概率矩阵,确定损失信息,包括:根据所述第一样本概率矩阵和所述第二样本概率矩阵,确定第三样本概率矩阵;确定所述第三样本概率矩阵中所有数值的平均值,作为损失信息。8.根据权利要求7所述的方法,其特征在于,所述根据所述第一样本概率矩阵和所述第二样本概率矩阵,确定第三样本概率矩阵,包括:根据所述第一样本概率矩阵、所述第二样本概率矩阵以及第二公式,确定第三样本概率矩阵;所述第二公式为:g=
‑
αloge
‑
(1
‑
α)logf;其中,e为所述第一样本概率矩阵,f为所述第二样本概率矩阵,g为所述第三样本概率矩阵,α为预设数值。9.一种终端,其特征在于,所述终端包括处理器和存储器,所述存储器中存储有至少一条程序代码,所述至少一条程序代码由所述处理器加载并执行以实现如权利要求1至权利要求8任一项所述的方法所执行的操作。10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有至少一条程序代码,所述至少一条程序代码由处理器加载并执行以实现如权利要求1至权利要求8任一项所述的方法所执行的操作。
技术总结
本申请公开了一种检索音频和训练声学模型的方法、终端及存储介质,属于互联网技术领域。该方法包括:提取待检索的目标音频片段的目标频谱数据;基于目标频谱数据,确定目标特征信息;将目标特征信息分别输入训练完成的声学模型中的第一解码器和第二解码器,得到第一目标概率矩阵和第二目标概率矩阵;根据第一目标概率矩阵和第二目标概率矩阵,确定音节序列;确定音节序列分别和参考音节序列库中每个参考音节序列之间的相似度,并确定相似度最大的预设数目个目标参考音节序列,将目标参考音节序列对应的目标音频标识确定为检索结果。本申请可以直接通过音频片段进行检索,避免了当用户不知道歌曲的名称时,无法进行检索的问题。题。题。
技术研发人员:张斌
受保护的技术使用者:腾讯音乐娱乐科技(深圳)有限公司
技术研发日:2021.09.01
技术公布日:2021/11/30
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。