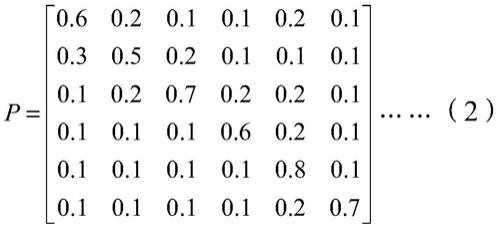
技术特征:
1.一种语音识别方法,其特征在于,包括:获取若干音频帧的语义特征表示;利用语音识别模型对所述若干音频帧的语义特征表示进行识别,得到所述若干音频帧对应的识别文本;其中,所述语音识别模型采用注意力机制,且所述注意力机制的掩膜是基于语音识别要求的时延而生成的。2.根据权利要求1所述的方法,其特征在于,所述语音识别模型包括多层注意力网络层,每层所述注意力网络层均对应设有子掩膜,所述掩膜包含各个所述注意力网络层的子掩膜,每层所述注意力网络层的子掩膜是基于对应所述注意力网络层的子时延而生成的,所述各个所述注意力网络层的子时延相加得到一个和值,且所述和值与所述时延之间满足预设大小关系。3.根据权利要求2所述的方法,其特征在于,所述预设大小关系包括:所述和值等于所述时延。4.根据权利要求2所述的方法,其特征在于,所述注意力网络层的所述子掩膜的生成步骤包括:基于所述若干音频帧的第一帧数,生成初始矩阵;基于所述注意力网络层对应的子时延,确定掩膜参数;其中,所述掩膜参数包括第一掩膜值和第二掩膜值;对于所述初始矩阵的第i行,基于第i
‑
1行中第一元素组的元素位置和所述掩膜参数,定位所述第i行中所述第一元素组和所述第一元素组之后的第二元素组;其中,所述第i行中所述第一元素组滞后所述第i
‑
1行中所述第一元素组的列数为所述第一掩膜值,且所述第一元素组所含第一元素的第一总数为所述第一掩膜值,所述第二元素组所含第二元素的第二总数为所述第二掩膜值。5.根据权利要求4所述的方法,其特征在于,所述第一元素为第一常数值,所述第二元素为第二常数值,不包含于所述第一元素组、所述第二元素组中任一者的元素为第三常数值,且所述第一常数值和所述第二常数值均大于所述第三常数值。6.根据权利要求4所述的方法,其特征在于,所述第一掩膜值和所述第二掩膜值是基于所述子时延和所述音频帧的持续时长确定的;和/或,所述初始矩阵的行数和列数等于所述第一帧数。7.根据权利要求2所述的方法,其特征在于,所述语音识别模型包括音素识别网络和文本解码网络,所述音素识别网络包括所述多层注意力网络层;其中,所述音素识别网络用于对所述若干音频帧的语义特征表示进行音素识别,得到所述若干音频帧的音素分类信息,所述文本解码网络用于对所述音素分类信息进行文本解码,得到所述若干音频帧对应的识别文本。8.根据权利要求1所述的方法,其特征在于,所述获取若干音频帧的语义特征表示,包括:提取各个所述音频帧的声学特征表示;对于每一所述音频帧,融合所述音频帧及其之前预设数值帧所述音频帧的声学特征表示,得到所述音频帧的语义特征表示。9.根据权利要求1所述的方法,其特征在于,所述语音识别模型是经若干轮训练得到
的,且在每轮训练过程中,所述注意力机制的掩膜均是基于当前轮训练所要求的样本时延而生成的,所述样本时延是随机设置的。10.一种语音识别装置,其特征在于,包括:语义特征获取模块,用于获取若干音频帧的语义特征表示;识别文本获取模块,用于利用语音识别模型对所述若干音频帧的语义特征表示进行识别,得到所述若干音频帧对应的识别文本;其中,所述语音识别模型采用注意力机制,且所述注意力机制的掩膜是基于语音识别要求的时延而生成的。11.一种电子设备,其特征在于,包括相互耦接的存储器和处理器,所述存储器中存储有程序指令,所述处理器用于执行所述程序指令以实现权利要求1至9任一项所述的语音识别方法。12.一种计算机可读存储介质,其特征在于,存储有能够被处理器运行的程序指令,所述程序指令用于实现权利要求1至9任一项所述的语音识别方法。
技术总结
本申请公开了一种语音识别方法及相关装置、电子设备、存储介质,其中,语音识别方法包括:获取若干音频帧的语义特征表示;利用语音识别模型对若干音频帧的语义特征表示进行识别,得到若干音频帧对应的识别文本;其中,语音识别模型采用注意力机制,且注意力机制的掩膜是基于语音识别要求的时延而生成的。上述方案,能够降低不同时延要求下语音识别的复杂度和成本。和成本。和成本。
技术研发人员:吴重亮 方昕 吴明辉 李永超 刘俊华
受保护的技术使用者:科大讯飞股份有限公司
技术研发日:2021.08.09
技术公布日:2021/11/30
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。