技术特征:
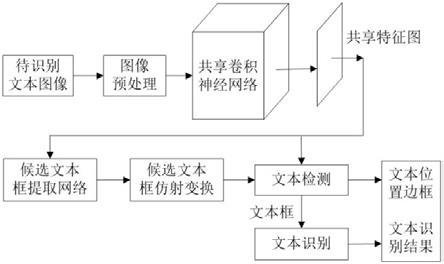
1.一种基于深度学习的ocr文字识别方法,其特征在于,具体包括以下步骤:步骤1:采集自然场景中包含文本的图像并进行图像标注后,将图像划分为训练集和测试集;步骤2:搭建共享卷积神经网络,将预处理后图像输入到共享卷积神经网络中,得到共享特征图;步骤3:搭建候选文本框提取网络,输入共享特征图到候选文本框提取网络中,得到具有不同旋转角度的候选文本框;步骤4:实现候选文本框仿射变换;步骤5:对仿射变换后的候选文本框进行文本检测;所述文本检测过程是将经仿射变换得到的候选文本框输入到roipooling层中得到仿射变换候选文本框的特征,这些特征的大小固定且相同;再将所得特征输入到后续依次连接的两层全连接层和softmax层中得的文本检测结果,同时进行候选文本框的位置回归得到更加准确的文本框位置坐标;步骤6:利用rnn循环网络和ctc算法对文本检测结果进行文本识别;步骤7:用步骤1中制作的数据集训练上述网络并进行ocr文本识别测试。2.如权利要求1所述的一种基于深度学习的ocr文字识别方法,其特征在于,步骤2中的所述搭建共享卷积神经网络:所述共享卷积神经网络设置有依次连接的5个卷积块conv和3个反卷积块deconv;且5个卷积块conv中的中间的3个卷积块conv与3个反卷积块deconv还构成关于卷积块conv5的对称结构,所述对称结构具体为:卷积块conv4输出的特征图与反卷积块deconv1输出的特征图相融合得到新特征图,并将新特征图作为下一个反卷积块deconv2的输入;同理,卷积块conv3输出的特征图与反卷积块deconv2输出的特征图相融合得到新特征图并作为下一个反卷积块deconv3的输入,卷积块conv2输出的特征图与反卷积块deconv3输出的特征图相融合得到共享特征图,且所得共享特征图的长宽是输入到该网络中的图像长宽的1/4;每个所述卷积块conv包括两个依次连接的卷积层,每个所述反卷积块deconv中包括依次连接的一个反卷积层和一个卷积层;每个卷积层和反卷积层后都设置有一个激活函数relu;利用卷积层进行卷积操作和特征降维,而不是利用下采样层进行特征降维,来保留了更多的图像像素信息,从而获得更具鲁棒性的图像特征。3.如权利要求2所述的一种基于深度学习的ocr文字识别方法,其特征在于,步骤3中的所述候选文本框提取网络包括候选文本框构建网络层、候选文本框分类分支、候选文本框位置回归分支和自定义网络层;所述步骤3具体步骤包括:步骤3.1:将共享特征图送入候选文本框提取网络中,该网络首先利用候选文本框构建网络层在共享特征图上的每个像素点处进行卷积核为5
×
3和3
×
5的卷积操作,且分别获得水平方向上的和垂直方向上的特征并将这两个方向上的特征进行连接,同时为每个像素点配备63种不同尺度、不同长宽比以及不同旋转角度的候选文本框;步骤:3.2:将候选文本框分别送入到候选文本框分类分支、候选文本框位置回归分支中进行分类处理和位置回归处理;步骤3.3:将候选文本框分类分支、候选文本框位置回归分支的输出内容送入到自定义
网络层中,并结合输入图像的信息判断产生的候选文本框是否超出图像边界,若候选文本框超出输入图像边界则剔除,同时微调符合要求的候选文本框的位置,得到最终的带角度的候选文本框;所述由候选文本框构建网络层产生的候选文本框具有32^2、64^2、128^2共3种尺度,2:1、4:1、8:1共3种长宽比以及π/2、π/3、π/6、0、
‑
π/6、
‑
π/3、
‑
π/2共7种旋转角度;并以一个5维的向量(x,y,w,h,θ)表示提取的每一个候选文本框,其中x和y表示候选文本框的中心坐标,用于确定候选文本框的位置;w和h表示候选文本框的宽和高,用于确定候选文本框的大小;θ表示预测的候选文本框相对于水平方向的旋转角度且旋转角度范围θ∈[π/2,
‑
π/2];其中,训练网络时,候选文本框提取网络利用候选文本框分类分支对候选文本框进行分类是将候选文本框分为包含文本的候选文本框和背景两类,且在判断候选文本框是否包含文本内容时需要同时根据两个条件进行判断:一是候选文本框的旋转角度θ与真实标记的文本框旋转角度θ
gt
差值的绝度值小于等于π/12;二是利用仿射变换将候选文本框和真实标记的文本框转换成水平文本框后两者面积的交并比大于0.6则判断为包含文本内容、交并比小于0.3则判断为背景。4.如权利要求3所述的的一种基于深度学习的ocr文字识别方法,其特征在于,在经过步骤3处理后,还需要对候选文本框进行仿射变换,然后再进行步骤4的操作,具体放射变换的操作为:首先,计算候选文本框的仿射变换矩阵m,计算公式具体如下;其中,m表示仿射变换矩阵,包含旋转、缩放、平移;θ表示候选文本框的旋转角度;s表示缩放的比例;t
k
和t
g
表示平移量;具体参数计算公式分别如下:t
k
=l*conθ
‑
t*sinθ
‑
k;t
g
=t*conθ l*sinθ
‑
g;其中,t、b、l表示候选文本框中的点距离旋转的框的上下左的距离,h
t
为仿射变换后候选文本框的高度;然后,对候选文本框进行仿射变换;具体计算公式如下:其中,k、g为原坐标值,k
′
、g
′
为变换后的新坐标;最后,通过双线性插值法获得候选文本框的高度固定且长宽比保持不变的水平特征,将获取的水平方向的候选文本框特征用于文本检测,双线插值法具体计算公式如下:
其中,(i,j)表示坐标点,f(i,j)为插值结果,f(i1,j1)、f(i2,j1)、f(i2,j1)、f(i2,j2)表示特征图中已知的四个坐标点处的像素值,f()为根据坐标值计算像素值的计算模型。5.如权利要求4所述的一种基于深度学习的ocr文字识别方法,其特征在于,所述步骤4的操作为:对经过仿射变换的候选文本框进行非极大值抑制操作,具体为:步骤4.1:按照文本框的置信度p排列相应的候选文本框;步骤4.2:选取置信度最大的候选文本框,将置信度最大的候选文本框与其余候选文本框进行iou运算,并删除运算结果超过设定阈值的候选文本框;步骤4.3:对删除后剩下的候选文本框继续执行步骤2的操作,得到更为精确的包含文本的候选文本框,将这些经过筛选的更为精确的包含文本的候选文本框一方面作为图像中文本的位置预测结果,另一方面用于文本识别部分的输入,所述iou运算的具体公式如下:其中,iou是候选文本框重合部分交并比的计算结果,areai和areaj分别表示两个不同候选文本框的面积。6.如权利要求1所述的一种基于深度学习的ocr文字识别方法,其特征在于,所述步骤5采用rnn循环网络和ctc算法网络构成文本识别网络来对筛选后的文本框进行文本识别,具体步骤为:步骤5.1:将共享特征图和候选文本框筛选的文本框输入;步骤5.2:将输入的特征转换成序列,并输入到rnn循环网络中进行文本的预测识别;步骤5.3:最将预测识别结果输入到ctc算法网络中得到识别结果。7.如权利要求1所述的一种基于深度学习的ocr文字识别方法,其特征在于,所述步骤6在整个训练过程中采用的训练函数l包括两部分,分别为步骤3的候选文本框的提取部分的损失函数l
box
以及在文字识别过程中的损失函数l
recog
。8.如权利要求7所述的一种基于深度学习的ocr文字识别方法,其特征在于,所述训练函数l的计算公式如下:l=l
box
l
recog
。9.如权利要求7或8所述的一种基于深度学习的ocr文字识别方法,其特征在于,所述损失函数l
recog
的具体计算公式如下:其中,l
recog
表示文字识别过程中的损失函数值,表示标准的序列标签,h
n
表示循环层产生的概率预测序列,p()表示条件概率,n表示序列标签的长度,log表示对数函数。
10.如权利要求7或8所述的一种基于深度学习的ocr文字识别方法,其特征在于,所述步骤7在整个训练过程中候选文本框提取网络训练时的损失函数l
box
的计算公式如下:其中,l
box
表示产生候选文本框过程中的损失函数值,p
i
表示候选文本框i预测为包含文本的概率;表示候选文本框是否包含文本的标签,当候选文本框包含文本时为1、不包含文本时为0;m
cls
表示训练过程中每次迭代所用的候选文本框数量,m
rt
表示包含文本的候选文本框数量,r表示smoothl1函数,l
i
=(x,y,w,h,θ)表示包含文本的候选文本框的参数化坐标,是与包含文本的候选文本框l
i
相对应的标准文本框参数化坐标,λ为平衡权重参数。
技术总结
本发明提出了一种基于深度学习的OCR文字识别方法,通过数据集构建、搭建共享卷积神经网络、搭建候选文本框提取网络、候选文本框仿射变换、文本检测、文本识别等操作;实现多角度文本识别,且识别精度和速度更高。且识别精度和速度更高。且识别精度和速度更高。
技术研发人员:王红蕾 李欢欢 徐小云 杨平 胡州明 朱海萍 吴豪 周平
受保护的技术使用者:四川中电启明星信息技术有限公司
技术研发日:2021.09.07
技术公布日:2021/11/24
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。