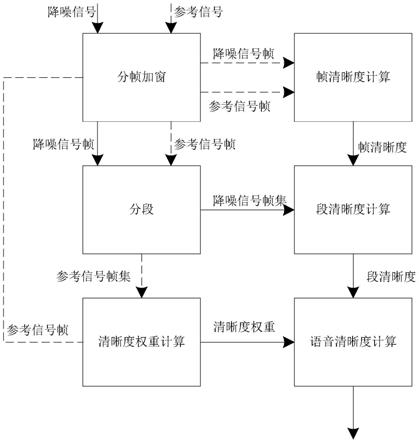
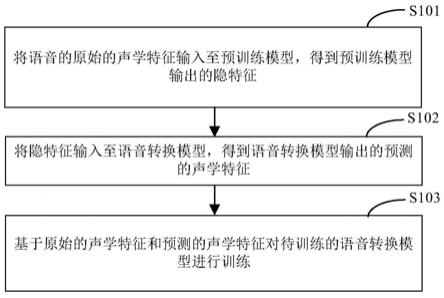
技术特征:
1.一种语音转换模型的训练方法,所述方法包括:将第一用户针对语音的声学特征按照从前到后的顺序依次输入至音色概率图模型、编码器、注意力机制模型和解码器,得到所述解码器输出的特征序列;基于所述解码器输出的特征序列和第二用户针对所述语音的声学特征对待训练的语音转换模型进行训练。2.根据权利要求1所述的方法,其中,所述将第一用户针对语音的声学特征按照从前到后的顺序依次输入至音色概率图模型、编码器、注意力机制模型和解码器,得到所述解码器输出的特征序列,包括:将所述第一用户针对所述语音的声学特征输入至所述音色概率图模型,得到所述音色概率图模型输出的音色概率序列;将所述音色概率图模型输出的音素概率序列输入至所述编码器,得到所述编码器输出的特征序列;将所述编码器输出的特征序列输入至所述注意力机制模型,得到所述注意力机制模型输出的特征序列;将所述注意力机制模型输出的特征序列输入至所述解码器,得到所述解码器输出的特征序列。3.根据权利要求2所述的方法,其中,所述将第一用户针对语音的声学特征输入至音色概率图模型,包括:将所述第一用户针对所述语音的声学特征划分为n个声学特征单元;其中,n为大于1的自然数;将所述n个声学特征单元输入至所述音色概率图模型。4.根据权利要求1所述的方法,其中,所述基于所述解码器输出的特征序列和第二用户针对所述语音的声学特征对待训练的语音转换模型进行训练,包括:基于所述解码器输出的特征序列和第二用户针对所述语音的声学特征计算所述待训练的语音转换模型针对所述语音的声学特征的损失值;根据所述待训练的语音转换模型针对所述语音的声学特征的损失值对所述待训练的语音转换模型的参数进行调整。5.根据权利要求1所述的方法,所述方法还包括:将第一用户针对目标语音的声学特征输入至训练好的语音转换模型,通过所述语音转换模型得到预测出的第二用户针对所述目标语音的声学特征;基于所述第二用户针对所述目标语音的声学特征得到目标语音;其中,所述目标语音包括所述第一用户针对所述目标语音的内容信息和所述第二用户针对所述目标语音的音色信息。6.根据权利要求5所述的方法,其中,所述将第一用户针对目标语音的声学特征输入至训练好的语音转换模型,通过所述语音转换模型得到预测出的第二用户针对所述目标语音的声学特征,包括:将所述第一用户针对所述目标语音的声学特征输入至训练好的音素概率图模型,得到所述音素概率图模型输出的预测的音色概率序列;将所述预测的音色概率序列输入至训练好的编码器,得到所述编码器输出的预测的特
征序列;将所述编码器输出的预测的特征序列输入至训练好的解码器,得到所述解码器输出的预测的特征序列;将所述解码器输出的预测的特征序列作为所述预测出的第二用户针对所述目标语音的声学特征。7.一种语音转换模型的训练装置,所述装置包括:输入模块和训练模块;其中,所述输入模块,用于将第一用户针对语音的声学特征按照从前到后的顺序依次输入至音色概率图模型、编码器、注意力机制模型和解码器,得到所述解码器输出的特征序列;所述训练模块,用于基于所述解码器输出的特征序列和第二用户针对所述语音的声学特征对待训练的语音转换模型进行训练。8.根据权利要求7所述的装置,所述输入模块,具体用于将所述第一用户针对所述语音的声学特征输入至所述音色概率图模型,得到所述音色概率图模型输出的音色概率序列;将所述音色概率图模型输出的音素概率序列输入至所述编码器,得到所述编码器输出的特征序列;将所述编码器输出的特征序列输入至所述注意力机制模型,得到所述注意力机制模型输出的特征序列;将所述注意力机制模型输出的特征序列输入至所述解码器,得到所述解码器输出的特征序列。9.根据权利要求8所述的装置,所述输入模块,具体用于将所述第一用户针对所述语音的声学特征划分为n个声学特征单元;其中,n为大于1的自然数;将所述n个声学特征单元输入至所述音色概率图模型。10.根据权利要求7所述的装置,所述训练模块,具体用于基于所述解码器输出的特征序列和第二用户针对所述语音的声学特征计算所述待训练的语音转换模型针对所述语音的声学特征的损失值;根据所述待训练的语音转换模型针对所述语音的声学特征的损失值对所述待训练的语音转换模型的参数进行调整。11.根据权利要求7所述的装置,所述装置还包括:预测模块,用于将第一用户针对目标语音的声学特征输入至训练好的语音转换模型,通过所述语音转换模型得到预测出的第二用户针对所述目标语音的声学特征;基于所述第二用户针对所述目标语音的声学特征得到目标语音;其中,所述目标语音包括所述第一用户针对所述目标语音的内容信息和所述第二用户针对所述目标语音的音色信息。12.根据权利要求11所述的装置,所述预测模块,具体用于将所述第一用户针对所述目标语音的声学特征输入至训练好的音素概率图模型,得到所述音素概率图模型输出的预测的音色概率序列;将所述预测的音色概率序列输入至训练好的编码器,得到所述编码器输出的预测的特征序列;将所述编码器输出的预测的特征序列输入至训练好的解码器,得到所述解码器输出的预测的特征序列;将所述解码器输出的预测的特征序列作为所述预测出的第二用户针对所述目标语音的声学特征。13.一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行权利要求1
‑
6中任一项所述的方法。14.一种存储有计算机指令的非瞬时计算机可读存储介质,其中,所述计算机指令用于
使所述计算机执行根据权利要求1
‑
6中任一项所述的方法。15.一种计算机程序产品,包括计算机程序/指令,其特征在于,该计算机程序/指令被处理器执行时实现权利要求1所述方法的步骤。
技术总结
本公开提供了一种语音转换模型的训练方法、装置、电子设备及介质,涉及人工智能技术领域,尤其涉及语音和深度学习技术。具体实现方案为:将第一用户针对语音的声学特征按照从前到后的顺序依次输入至音色概率图模型、编码器、注意力机制模型和解码器,得到解码器输出的特征序列;基于解码器输出的特征序列和第二用户针对语音的声学特征对待训练的语音转换模型进行训练。本申请实施例将注意力机制取代DTW对齐,使对齐精度更好,并且使用音素概率图特征作为转换系统的输入特征使模型的学习更方便;该方法既能提高对齐的精度,也能有效提高转换的音色效果。高转换的音色效果。高转换的音色效果。
技术研发人员:王俊超 陈怿翔 康永国
受保护的技术使用者:北京百度网讯科技有限公司
技术研发日:2021.08.18
技术公布日:2021/11/23
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。