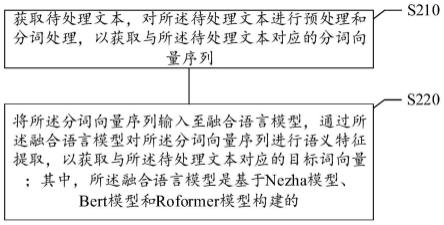
技术特征:
1.一种文本处理方法,其特征在于,包括:获取待处理文本,对所述待处理文本进行预处理和分词处理,以获取与所述待处理文本对应的分词向量序列;将所述分词向量序列输入至融合语言模型,通过所述融合语言模型对所述分词向量序列进行语义特征提取,以获取与所述待处理文本对应的目标词向量;其中,所述融合语言模型是基于nezha模型、bert模型和roformer模型构建的。2.根据权利要求1所述的方法,其特征在于,所述对所述待处理文本进行预处理和分词处理,以获取分词向量序列,包括:将预处理后的所述待处理文本输入至分词模型,通过所述分词模型对所述预处理后的待处理文本进行分词和向量化处理,以获取与所述预处理后的待处理文本中各分词对应的分词向量;根据各所述分词的顺序和各所述分词对应的分词向量构建所述分词向量序列。3.根据权利要求1所述的方法,其特征在于,所述融合语言模型包括输入层、第一语义解析单元、第二语义解析单元、模型融合层、词向量转换层和输出层;所述将所述分词向量序列输入至融合语言模型,通过所述融合语言模型对所述分词向量序列进行语义特征提取,以获取与所述待处理文本对应的目标词向量,包括:通过所述输入层将所述分词向量序列分别输入至所述第一语义解析单元和所述第二语义解析单元,通过所述第一语义解析单元和所述第二语义解析单元分别对所述分词向量序列进行语义特征提取,以获取第一词向量和第二词向量;通过所述模型融合层对所述第一词向量和所述第二词向量进行融合,以获取融合词向量;通过所述词向量转换层基于注意力机制对所述融合词向量进行处理,以获取所述目标词向量。4.根据权利要求3所述的方法,其特征在于,所述第一语义解析单元包括依次连接的roformer模型层和第一bert模型层;所述通过所述第一语义解析单元对所述分词向量序列进行语义特征提取,以获取第一词向量,包括:通过所述roformer模型层根据所述分词向量序列中各分词向量所对应的位置构建旋转位置编码;将所述分词向量序列和所述旋转位置编码输入至所述第一bert模型层,通过所述第一bert模型层根据所述旋转位置编码对所述分词向量序列进行语义特征提取,以获取所述第一词向量。5.根据权利要求3中所述的方法,其特征在于,所述第二语义解析单元包括依次连接的第二bert模型层和nezha模型层;所述通过所述第二语义解析单元对所述分词向量序列进行语义特征提取,以获取第二词向量,包括:将所述分词向量序列输入至所述第二bert模型层,通过所述第二bert模型层对所述分词向量序列进行语义特征提取,以获取初始词向量;将所述初始词向量输入至所述nezha模型层,通过所述nezha模型层对所述初始词向量
进行处理,以获取相对位置编码,并基于所述相对位置编码对所述初始词向量进行语义特征提取,以获取所述第二词向量。6.根据权利要求3所述的方法,其特征在于,所述通过所述模型融合层对所述第一词向量和所述第二词向量进行融合,以获取融合词向量,包括:将所述第一词向量和所述第二词向量中对应同一分词的词向量相加或拼接,以获取所述融合词向量。7.根据权利要求3所述的方法,其特征在于,所述融合词向量包括与各所述分词对应的嵌入词向量,所述词向量转换层包括注意力层和转换层;所述通过所述词向量转换层基于注意力机制对所述融合词向量进行处理,以获取所述目标词向量,包括:通过所述注意力层基于注意力机制确定与各所述嵌入词向量对应的注意力权重;通过所述转换层根据各所述嵌入词向量和与各所述嵌入词向量对应的所述注意力权重进行加权平均,以获取所述目标词向量。8.根据权利要求1所述的方法,其特征在于,在将所述分词向量序列输入至融合语言模型之前,所述方法还包括:获取文本样本,对所述文本样本进行所述预处理和所述分词处理,以获取与所述文本样本对应的分词向量样本序列;根据所述分词向量样本序列对待训练融合语言模型进行对比训练和对抗训练,以获取所述融合语言模型。9.根据权利要求8所述的方法,其特征在于,所述获取文本样本,包括:获取标注文本、与所述标注文本对应的分类信息和未标注文本,根据所述标注文本和所述分类信息对待训练文本分类模型进行训练,以获取文本分类模型,所述待训练文本分类模型是基于所述待训练融合语言模型构建的;将未标注文本输入至所述文本分类模型,通过所述文本分类模型对所述未标注文本进行特征提取,以获取与所述未标注文本对应的分类信息;根据所述分类信息将所述标注文本和所述未标注文本划分为多个文本集,并根据所述多个文本集确定所述文本样本。10.根据权利要求9所述的方法,其特征在于,所述分类信息为业务类型;所述根据所述多个文本集确定所述文本样本,包括:获取与目标业务类型对应的文本集中的文本作为正文本样本,获取与所述目标业务类型不对应的文本集中的文本作为负文本样本;根据所述正文本样本和所述负文本样本构建所述文本样本。11.根据权利要求8所述的方法,其特征在于,所述根据所述分词向量样本序列对待训练融合语言模型进行对比训练和对抗训练,以获取所述融合语言模型,包括:获取与目标文本样本对应的第一分词向量序列,根据所述第一分词向量序列生成正样本对;获取与非目标文本样本对应的第二分词向量序列,根据所述第二分词向量序列生成负样本;根据所述目标文本样本、所述正样本对和所述负样本对所述待训练融合语言模型进行
对比训练,并在进行所述对比训练的同时,对所述待训练融合语言模型中的参数进行快速梯度上升处理,以对所述待训练融合语言模型进行对抗训练。12.根据权利要求11所述的方法,其特征在于,所述根据所述第一分词向量序列生成正样本对,包括:将所述第一分词向量序列输入至所述待训练融合语言模型两次,以获取两组与所述目标文本样本对应的词向量,根据所获取的两组词向量构建所述正样本对。13.根据权利要求11所述的方法,其特征在于,所述根据所述目标文本样本、所述正样本对和所述负样本对所述待训练融合语言模型进行对比训练,包括:根据所述正样本对中的一个正样本和所述负样本构建正负样本对;根据所述目标文本样本、所述正负样本对和所述正样本对对所述待训练融合语言模型进行对比训练。14.一种文本处理装置,其特征在于,包括:文本处理模块,用于获取待处理文本,对所述待处理文本进行预处理和分词处理,以获取与所述待处理文本对应的分词向量序列;模型处理模块,用于将所述分词向量序列输入至融合语言模型,通过所述融合语言模型对所述分词向量序列进行语义特征提取,以获取与所述待处理文本对应的目标词向量;其中,所述融合语言模型是基于nezha模型、bert模型和roformer模型构建的。15.一种计算机存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1~13中任意一项所述的文本处理方法。16.一种电子设备,其特征在于,包括:处理器;以及存储器,用于存储所述处理器的可执行指令;其中,所述处理器配置为经由执行所述可执行指令来执行权利要求1~13中任意一项所述的文本处理方法。
技术总结
本申请属于人工智能技术领域,涉及文本处理方法、装置、存储介质及电子设备。该方法包括:获取待处理文本,对所述待处理文本进行预处理和分词处理,以获取与所述待处理文本对应的分词向量序列;将所述分词向量序列输入至融合语言模型,通过所述融合语言模型对所述分词向量序列进行语义特征提取,以获取与所述待处理文本对应的目标词向量;其中,所述融合语言模型是基于Nezha模型、Bert模型和Roformer模型构建的。本申请能够通过融合语言模型充分挖掘待处理文本中隐藏的信息,提高语义特征提取和词向量的精准度。和词向量的精准度。和词向量的精准度。
技术研发人员:刘康 李鉴学 范潇 杨明川
受保护的技术使用者:中国电信股份有限公司
技术研发日:2022.09.02
技术公布日:2022/11/22
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。