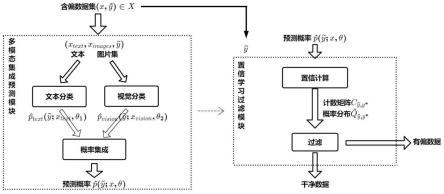
技术特征:
1.一种基于置信学习的有偏数据检测方法,其特征在于,是按如下步骤进行:步骤1、将包含有偏数据的样本数据集记为x={x1,x2,
…
,x
k
,
…
,x
k
},其中,k表示所述样本数据集x中的样本数,x
k
表示第k个样本,且表示第k个样本,且表示第k个样本x
k
的文本,且且表示第k个样本x
k
中文本的第n个单词,n为文本的单词数;表示第k个样本x
k
的图片集,且的图片集,且表示第k个样本x
k
中图片集的第m张图片;m为图片集的图片数量;表示第k个样本x
k
中含偏标签集,且中含偏标签集,且中含偏标签集,且表示第k个样本x
k
中含偏标签集的第g个含偏标签,g为含偏标签集的含偏标签数;将所述样本数据集x中所有样本的不重复的含偏标签集记作将所述样本数据集x中所有样本的不重复的含偏标签集记作表示第c个含偏标签,c为所述样本数据集x中不重复的含偏标签数量;步骤2、构建多模态集成预测模块,包括:文本分类器、视觉分类器和融合层;步骤2.1、基于bi-lstm模型构建文本分类器;步骤2.1.1、所述文本分类器通过一个嵌入层对第n个单词进行处理,得到第n个单词的嵌入向量从而得到的嵌入向量集合步骤2.1.2、所述文本分类器将嵌入向量集合e
k
输入bi-lstm网络中并获得文本描述的词级别表征h
n
:所述bi-lstm网络中的前向网络按照到的顺序读取嵌入向量,并利用式(1)得到第n个单词的前向隐藏状态的前向隐藏状态式(1)中,代表第n-1个单词的前向隐藏状态;所述bi-lstm网络中的后向网络按照到的顺序读取嵌入向量,并利用式(2)得道第n个单词的后向隐藏状态的后向隐藏状态式(2)中,代表第n 1个单词单的后向隐藏状态;所述bi-lstm网络再通过式(3)得到结合上下文情境的第n个单词的表征表示从而得到第k个样本x
k
的文本的单词表征的单词表征步骤2.1.3、所述文本分类器采用平均池化的方法处理来获取文本的全局特征再通过softmax分类层对全局特征进行处理,从而利用式(4)生成仅在文本条件下,第k个样本x
k
对第c个含偏标签的预测概率
式(4)中,和分别表示在第c个标签下的参数矩阵和偏置向量;步骤2.2、基于预训练后的vgg-16网络构建视觉分类器;步骤2.2.1、所述视觉分类器将第k个样本的图片集输入预训练后的vgg-16模型中进行处理,并将vgg-16模型中倒数第二个全连接层的输出作为图片集的特征表示集合;其中,表示中第m张图片的特征表示;步骤2.2.2、所述视觉分类器采用平均池化的方法对图片集的特征表示集合的特征表示集合进行聚合操作,得到第k个样本x
k
的图片集的视觉特征再使用一个mlp层对视觉特征进行处理,并利用式(5)得到视觉特征的隐藏展示最后使用另一个mlp层对隐藏展示进行处理,并利用式(6)生成仅在视觉条件下,第k个样本x
k
对第c个含偏标签的预测概率的预测概率的预测概率式(5)和式(6)中,tanh表示双曲正切函数,并作为隐藏层的激活函数,分别表示隐藏层对应的参数矩阵和偏置向量;和分别表示在第c个含偏标签下的参数矩阵和偏置向量;步骤2.3、融合层使用如式(10)所示的加权平均法对预测概率进行集成,得到第k个样本x
k
对第c个含偏标签最终的集成预测概率最终的集成预测概率式(7)中,α,β分别为文本分类器和视觉分类器的权重大小,满足α,β∈[0,1]且α β=1;步骤3、多模态集成预测模块的训练:步骤3.1、利用式(8)构建多模态集成预测模块的交叉熵损失函数j:式(8)中,s表示所述多模态样本数据集x中的部分样本作为训练集,|s|表示训练集的样本数,表示训练集中第f个样本x
f
的含偏标签集;步骤3.2、利用误差反向传播算法对所述多模态集成预测模块进行训练,并最小化损失函数j用于更新模块参数,直到所述损失函数j收敛为止,从而得到最优多模态集成预测模型;步骤4、利用式(9)计算所述含偏标签集中第j个含偏标签的置信度阈值t
j
:
式(9)中,表示样本数据集x中具有第j个含偏标签的样本子集,表示样本子集中的任意一个样本x在最优多模态集成预测模型的参数θ下对第j个含偏标签的预测概率,| |表示计数操作;步骤4、构建置信联合计数矩阵和联合概率分布;步骤4.1、根据置信度阈值,对所述样本数据集x中的正确标签进行估计,得到正确标签集y
*
,从而利用式(10)和式(11)计算含偏标签集与正确标签集y
*
的置信联合计数矩阵的置信联合计数矩阵的置信联合计数矩阵式(10)与式(11)中,表示中第i行第j列的值,即为同时具有第i个含偏标签与第j个正确标签的样本数量的样本数量表示同时具有第i个含偏标签与第j个正确标签的估计数据集合;步骤4.2、根据置信联合计数矩阵估计含偏标签集与正确标签集y
*
的联合概率分布步骤4.2.1、利用式(12)得到修正后计数矩阵第i行第j列的值步骤4.2.1、利用式(12)得到修正后计数矩阵第i行第j列的值步骤4.2.2、利用式(13)得到含偏标签集与正确标签集y
*
的联合概率分布估计的联合概率分布估计式(13)中,为联合概率分布估计中第i行第j列的值,表示数据中同时具有第i个含偏标签与第j个正确标签的概率,且满足步骤5、根据有偏率对有偏数据进行过滤:步骤5.1、从中的所有非对角线元素所对应的中选择若干个使得式(14)最小的样本并组成有偏数据候选集:式(14)中,表示样本子集中的任意一个样本x在参数θ下对第i个含偏标签的预测概率;步骤5.2、利用式(15)计算所述有偏数据候选集中的每个样本的边际并用于对样本进行升序排序,得到排序后的有偏数据候选集:
式(15)中,mean表示平均池化操作;为样本数据集x中的第i个含偏标签;表示第k个样本x
k
的含偏标签集合;表示第k个样本x
k
在参数θ下对第i个含偏标签的预测概率;步骤5.3、对排序后的有偏数据候选集,选取前一定比例的数据进行过滤,得到相对干净的数据集。2.一种电子设备,包括存储器以及处理器,其特征在于,所述存储器用于存储支持处理器执行权利要求1所述有偏数据检测方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。3.一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序,其特征在于,所述计算机程序被处理器运行时执行权利要求1所述有偏数据检测方法的步骤。
技术总结
本发明公开了一种基于置信学习的有偏数据检测方法,包括:1.构建并表示包含有偏数据的数据集,2.构建多模态集成预测模块,3.多模态集成预测模块的训练,4.构建置信联合计数矩阵和联合概率分布,5.根据有偏率对有偏数据进行过滤。本发明基于置信学习框架,综合考虑了文本与图片的特征表达,能够估计含偏标签与正确标签的联合概率分布,从而能筛选出正确数据,并有效降低含偏标签对相关任务的影响。并有效降低含偏标签对相关任务的影响。并有效降低含偏标签对相关任务的影响。
技术研发人员:钱洋 杜威 徐旺 姜元春 凌海峰 刘业政 许华华 陈邵格
受保护的技术使用者:合肥工业大学
技术研发日:2022.11.22
技术公布日:2023/3/3
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。