技术特征:
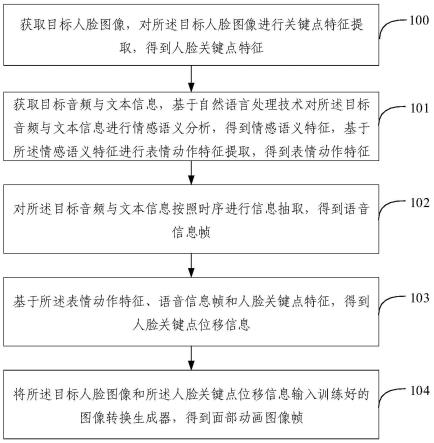
1.一种人脸动画生成方法,其特征在于,包括:获取目标人脸图像,对所述目标人脸图像进行关键点特征提取,得到人脸关键点特征;获取目标音频与文本信息,基于自然语言处理技术对所述目标音频与文本信息进行情感语义分析,得到情感语义特征,基于所述情感语义特征进行表情动作特征提取,得到表情动作特征;对所述目标音频与文本信息按照时序进行信息抽取,得到语音信息帧;基于所述表情动作特征、语音信息帧和人脸关键点特征,得到人脸关键点位移信息;将所述目标人脸图像和所述人脸关键点位移信息输入训练好的图像转换生成器,得到面部动画图像帧。2.根据权利要求1所述的人脸动画生成方法,其特征在于,所述基于所述表情动作特征、语音信息帧和人脸关键点特征,得到人脸关键点位移信息,具体包括:基于所述表情动作特征和所述语音信息帧,对所述人脸关键点特征进行关键点位移变换,得到人脸关键点位移信息;或者,基于所述语音信息帧,对所述人脸关键点特征进行关键点位移变换,得到人脸关键点位移信息。3.根据权利要求1所述的人脸动画生成方法,其特征在于,所述图像转换生成器是基于人脸图像样本、音频与文本信息样本以及所述人脸图像样本对应的面部动画图像帧样本进行生成对抗训练得到。4.根据权利要求1所述的人脸动画生成方法,其特征在于,所述方法还包括:基于生成对抗训练得到所述图像转换生成器;其中,所述基于生成对抗训练得到所述图像转换生成器,包括:构建初始生成对抗网络;获取人脸图像样本以及所述人脸图像样本对应的面部动画图像帧样本,对所述人脸图像样本进行人脸关键点特征提取,得到人脸关键点特征样本;获取音频与文本信息样本,基于自然语言处理技术对所述音频与文本信息样本进行情感语义分析,得到情感语义特征样本,基于所述情感语义特征样本进行表情动作特征提取,得到表情动作特征样本;对所述音频与文本信息样本按照时序进行信息抽取,得到语音信息帧样本;基于所述表情动作特征样本、语音信息帧样本和人脸关键点特征样本,得到人脸关键点位移信息样本;将所述人脸图像样本和所述人脸关键点位移信息样本输入至所述初始生成对抗网络的生成器,得到第一面部动画图像帧;将所述第一面部动画图像帧与所述面部动画图像帧样本输入到所述初始生成对抗网络的判别器,得到梯度信息;将所述梯度信息反馈至所述生成器,进行生成对抗训练;训练结束时,得到训练好的生成对抗网络,将所述训练好的生成对抗网络的生成器作为所述图像转换生成器。5.根据权利要求4所述的人脸动画生成方法,其特征在于,所述基于所述表情动作特征样本、语音信息帧样本和人脸关键点特征样本,得到人脸关键点位移信息样本,包括:
基于所述表情动作特征样本和所述语音信息帧样本,对所述人脸关键点特征样本进行关键点位移变换,得到人脸关键点位移信息样本;或者,基于所述语音信息帧样本,对所述人脸关键点特征样本进行关键点位移变换,得到人脸关键点位移信息样本。6.根据权利要求1所述的人脸动画生成方法,其特征在于,所述基于所述情感语义特征进行表情动作特征提取,得到表情动作特征,包括:将所述情感语义特征,或者将所述情感语义特征和目标音频,输入至深度学习网络进行表情动作特征提取,得到表情动作特征。7.一种人脸动画生成装置,其特征在于,包括:第一特征提取模块,用于获取目标人脸图像,对所述目标人脸图像进行关键点特征提取,得到人脸关键点特征;第二特征提取模块,用于获取目标音频与文本信息,基于自然语言处理技术对所述目标音频与文本信息进行情感语义分析,得到情感语义特征,基于所述情感语义特征进行表情动作特征提取,得到表情动作特征;时序抽取模块,用于对所述目标音频与文本信息按照时序进行信息抽取,得到语音信息帧;位移变换模块,用于基于所述表情动作特征、语音信息帧和人脸关键点特征,得到人脸关键点位移信息;生成模块,用于将所述目标人脸图像和所述人脸关键点位移信息输入训练好的图像转换生成器,得到面部动画图像帧。8.根据权利要求7所述的人脸动画生成装置,其特征在于,还包括:训练模块,用于基于生成对抗训练得到所述图像转换生成器;所述训练模块,具体用于:构建初始生成对抗网络;获取人脸图像样本以及所述人脸图像样本对应的面部动画图像帧样本,对所述人脸图像样本进行人脸关键点特征提取,得到人脸关键点特征样本;获取音频与文本信息样本,基于自然语言处理技术对所述音频与文本信息样本进行情感语义分析,得到情感语义特征样本,基于所述情感语义特征样本进行表情动作特征提取,得到表情动作特征样本;对所述音频与文本信息样本按照时序进行信息抽取,得到语音信息帧样本;基于所述表情动作特征样本、语音信息帧样本和人脸关键点特征样本,得到人脸关键点位移信息样本;将所述人脸图像样本和所述人脸关键点位移信息样本输入至所述初始生成对抗网络的生成器,得到第一面部动画图像帧;将所述第一面部动画图像帧与所述面部动画图像帧样本输入到所述初始生成对抗网络的判别器,得到梯度信息;将所述梯度信息反馈至所述生成器,进行生成对抗训练;训练结束时,得到训练好的生成对抗网络,将所述训练好的生成对抗网络的生成器作为所述图像转换生成器。
9.一种电子设备,包括处理器和存储有计算机程序的存储器,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至6任一项所述人脸动画生成方法的步骤。10.一种处理器可读存储介质,其特征在于,所述处理器可读存储介质存储有计算机程序,所述计算机程序用于使所述处理器执行权利要求1至6任一项所述人脸动画生成方法的步骤。
技术总结
本发明提供一种人脸动画生成方法及装置,所述方法包括:获取目标人脸图像,对目标人脸图像进行关键点特征提取,得到人脸关键点特征;获取目标音频与文本信息,基于自然语言处理技术对目标音频与文本信息进行情感语义分析,得到情感语义特征,基于情感语义特征进行表情动作特征提取,得到表情动作特征;对目标音频与文本信息按照时序进行信息抽取,得到语音信息帧;基于表情动作特征、语音信息帧和人脸关键点特征,得到人脸关键点位移信息;将目标人脸图像和人脸关键点位移信息输入训练好的图像转换生成器,得到面部动画图像帧。本发明能够生成表情丰富的面部动画,并生成了在接收用户音频信息的场景下的面部动画,保证面部动画的真实性。动画的真实性。动画的真实性。
技术研发人员:司晨 刘佳琳 刘亚盟 井志刚 付强 王忠光
受保护的技术使用者:中移系统集成有限公司 中国移动通信集团有限公司
技术研发日:2021.07.21
技术公布日:2023/2/6
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。