技术特征:
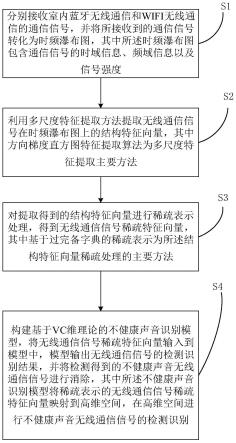
1.一种基于空气传导下的学习耳机智能消除不健康声音方法,其特征在于,所述方法包括:s1:分别接收室内蓝牙无线通信和wifi无线通信的通信信号,并将所接收到的通信信号转化为时频瀑布图,其中所述时频瀑布图包含通信信号的时域信息、频域信息以及信号强度;s2:利用多尺度特征提取方法提取无线通信信号在时频瀑布图上的结构特征向量,其中方向梯度直方图特征提取算法为多尺度特征提取主要方法;s3:对提取得到的结构特征向量进行稀疏表示处理,得到无线通信信号稀疏特征向量,其中基于过完备字典的稀疏表示为所述结构特征向量稀疏处理的主要方法,包括:所述s3步骤中对提取得到的结构特征向量进行稀疏表示处理,包括:对所提取的结构特征向量进行稀疏表示处理,得到无线通信信号稀疏特征向量,其中基于过完备字典的稀疏表示为所述结构特征向量稀疏处理的主要方法,所述稀疏表示处理流程为:s31:构建用于稀疏表示的字典,并初始化字典为d0,所述字典的维度为64
×
128维;s32:设置字典的当前迭代次数为d,d的初始值为0;s33:采集用于字典训练的训练集data1,训练集data1中的样本为图像结构特征向量;s34:构建训练集data1中各样本的稀疏系数表示,则训练集data1中第q个样本的稀疏系数表示为:其中:τ
q
为训练集data1中第q个样本data1
q
的稀疏系数表示;d
d
表示第d次字典迭代的字典;s35:将训练集data1中所有样本的稀疏系数表示构成稀疏系数表示矩阵τ,矩阵τ中的每一列表示样本的稀疏系数表示,并对字典进行第d 1次的更新:d
d 1
=τ
t
(ττ
t
)-1
判断是否小于阈值,若小于阈值,则d
d 1
为训练得到的过完备字典d
*
,τ为对应的稀疏系数表示矩阵;否则令d=d 1,返回步骤s34;s36:构建结构特征向量稀疏处理的目标函数:其中:h
″
i
表示结构特征向量h
′
i
稀疏处理后的稀疏特征向量;所述目标函数的约束条件为:其中:τ
r
为稀疏系数表示矩阵中的行向量,ε0为稀疏度约束阈值,||
·
||0表示l0范数;s37:将训练目标函数转换为拉格朗日函数:
其中:λ为拉格朗日乘子;将使得拉格朗日函数最小的h
″
i
作为稀疏表示处理后的稀疏特征向量,所述稀疏特征向量的维数为64维;则所述学习耳机所接收到的所有无线通信信号稀疏特征向量集合为{h
″1,h
″2,
…
,h
″
i
,
…
,h
″
m
};s4:构建基于vc维理论的不健康声音识别模型,将无线通信信号稀疏特征向量输入到模型中,模型输出无线通信信号的检测识别结果,并将检测得到的不健康声音无线通信信号进行消除,其中所述不健康声音识别模型将稀疏表示的无线通信信号稀疏特征向量映射到高维空间,在高维空间进行不健康声音无线通信信号的检测识别。2.如权利要求1所述的一种基于空气传导下的学习耳机智能消除不健康声音方法,其特征在于,所述s1步骤中分别接收室内蓝牙无线通信和wifi无线通信的通信信号,包括:学习耳机利用内置的信号接收装置分别接收无线通信信号,其中所述无线通信信号包括蓝牙无线通信信号以及wifi无线通信信号,所述室内蓝牙无线通信信号包括室内物联网设备以及移动通信设备的无线通信信号,所述wifi无线通信信号包括局域网下多种终端设备的无线通信信号;所述信号接收装置所接收的无线通信信号集合s为:s={s1(t1),s2(t2),
…
,s
i
(t
i
),
…
,s
m
(t
m
)}其中:s
i
(t
i
)表示信号接收装置所接收的第i个无线通信信号,t
i
表示无线通信信号s
i
(t
i
)的时域信息,t
i
∈[t
i,0
,t
i,end
],t
i,0
表示接收到无线通信信号s
i
(t
i
)的时刻,t
i,end
表示无线通信信号s
i
(t
i
)的消失时刻;a
i
表示无线通信信号的信号幅度s
i
(t
i
),f
i
表示无线通信信号s
i
(t
i
)的频率,表示无线通信信号s
i
(t
i
)的初始相位;m表示信号接收装置所接收到的无线通信信号数量;信号接收装置内的数模转换器将所接收到的无线通信信号转换为模拟信号,所述模拟信号的转换流程为:s11:构建频率为f
s
的冲激序列:的冲激序列:则无线通信信号集合s中任意无线通信信号s
i
(t
i
)的冲激序列为)的冲激序列为s12:基于无线通信信号的冲激序列,将无线通信信号集合s中的任意无线通信信号s
i
(t
i
)转换为模拟信号)转换为模拟信号s13:数模转换器按照模拟信号转换流程将无线通信信号集合s中的无线通信信号转换为模拟信号,得到转换后的集合3.如权利要求2所述的一种基于空气传导下的学习耳机智能消除不健康声音方法,其特征在于,所述s1步骤中对将所接收到的无线通信信号转化为时频瀑布图,包括:学习耳机中内置的时频转换器将集合s
′
中的模拟信号转化为时频瀑布图,所述时频瀑布图的转化流程为:对集合s
′
中的任意模拟信号进行时频转化:其中:s
i
(0)表示模拟信号中的第1个采样信号点的值,s
i
(n
i-1)表示模拟信号中的最后一个采样信号点的值,n
i
表示模拟信号中采样信号点的数目;j表示虚数单位,j2=-1;z(
·
)表示窗函数,l表示窗函数的长度,z
*
(
·
)表示窗函数的共轭复数;f
i
表示集合s
′
中的任意模拟信号的时频转化结果;计算任意模拟信号的信号强度en
i
:en
i
=(f
i
)2基于模拟信号的时域信息、频域信息以及信号强度构建模拟信号的时频瀑布图,所述任意模拟信号的时域瀑布图结果为g
i
(t
i
,f
i
,en
i
);所述集合s
′
中模拟信号的时频瀑布图集合为:{g1(t1,f1,en1),
…
,g
m
(t
m
,f
m
,en
m
)},将时频瀑布图集合发送到学习耳机内的处理器中。4.如权利要求3所述的一种基于空气传导下的学习耳机智能消除不健康声音方法,其特征在于,所述s2步骤中利用多尺度特征提取方法提取无线通信信号在时频瀑布图上的结构特征向量,包括:学习耳机内的处理器利用多尺度特征提取方法提取无线通信信号在时频瀑布图上的结构特征向量,其中方向梯度直方图特征提取算法为多尺度特征提取主要方法,则对于时频瀑布图集合中任意时频瀑布图g
i
(t
i
,f
i
,en
i
),所述多尺度特征提取方法流程为:s21:将时频瀑布图中任意像素(x,y)的像素值转化为灰度值,所述像素值的转化公式为:g(x,y)=0.299
×
r(x,y) 0.587
×
g(x,y) 0.114
×
b(x,y)
其中:r(x,y)表示像素(x,y)在红色颜色通道的值,g(x,y)表示像素(x,y)在绿色颜色通道的值,b(x,y)表示像素(x,y)在蓝色颜色通道的值;g(x,y)表示像素(x,y)的灰度值;s22:计算任意像素(x,y)的梯度值和梯度方向,所述像素梯度值以及梯度方向的计算公式为:公式为:其中:α(x,y)表示像素(x,y)的梯度值;β(x,y)表示像素(x,y)的梯度方向;s23:使用16
×
16像素大小的滑动窗口对时频瀑布图g
i
(t
i
,f
i
,en
i
)进行滑动分割,所述滑动分割采用从左到右,从上到下的顺序,所述时频瀑布图的图像规格均为64
×
128,共分割得到32个像素块;s24:计算每个像素块内像素的梯度值以及梯度方向,划分梯度方向统计区间为(0
°
,90
°
],(90
°
,180
°
],(180
°
,270
°
],(270
°
,360
°
],并计算得到每个像素块的梯度分布直方图,所述梯度分布直方图的横轴为梯度方向统计区间,纵轴为像素块内属于任意梯度方向统计区间的像素梯度之和;s25:将32个像素块的梯度分布直方图进行组合,所述组合结果h
i
为:其中:h
1,i
表示时频瀑布图g
i
(t
i
,f
i
,en
i
)中第1个像素块在4个方向的梯度分布直方图;h
i
表示时频瀑布图g
i
(t
i
,f
i
,en
i
)中梯度分布直方图的组合结果;所述组合结果包含时频瀑布图在4个方向的128个特征点,对h
i
进行归一化处理,所述归一化处理公式为:其中:表示l2范数;ε=0.01;h
′
i
为时频瀑布图g
i
(t
i
,f
i
,en
i
)的结构特征向量;基于多尺度特征提取方法提取时频瀑布图集合中所有时频瀑布图的结构特征向量。5.如权利要求1所述的一种基于空气传导下的学习耳机智能消除不健康声音方法,其特征在于,所述s4步骤中构建基于vc维理论的不健康声音识别模型,其中所述不健康声音
识别模型将稀疏表示的无线通信信号稀疏特征向量映射到高维空间,在高维空间进行不健康声音无线通信信号的检测识别,包括:构建基于vc维理论的不健康声音识别模型,其中所述不健康声音识别模型将稀疏表示的无线通信信号稀疏特征向量映射到高维空间,在高维空间进行不健康声音无线通信信号的检测识别;基于所述vc维理论,所述稀疏特征向量可以被vc维大小为65维的假设空间进行二分类,识别检测得到健康声音无线通信信号以及不健康声音无线通信信号,其中所述稀疏特征向量的维数维64维;所述不健康声音识别模型为65维的假设空间,不健康声音识别模型的识别流程为:将稀疏特征向量h
″
i
输入到不健康声音识别模型中:其中:表示高维的非线性映射;w表示权重向量,b表示偏置量;u(h
″
i
)表示稀疏特征向量h
″
i
所对应无线通信信号s
i
(t
i
)的不健康声音识别结果,u(h
″
i
)={0,1},u(h
″
i
)=1表示无线通信信号s
i
(t
i
)为不健康声音无线通信信号,u(h
″
i
)=0表示无线通信信号s
i
(t
i
)为健康声音无线通信信号。6.如权利要求5所述的一种基于空气传导下的学习耳机智能消除不健康声音方法,其特征在于,所述不健康声音识别模型的训练流程,包括:s41:构建不健康声音识别模型的回归方程:其中:h表示不健康声音识别模型的输入值;s42:采集用于训练不健康声音识别模型的训练数据构成训练数据集data2,所述训练数据集data2中每组训练数据包括稀疏特征向量以及对应的不健康声音识别结果;s43:基于训练数据集data2得到模型参数w和b,所述模型参数的计算公式为:s43:基于训练数据集data2得到模型参数w和b,所述模型参数的计算公式为:其中:ω表示训练数据集data2中的稀疏特征向量集合,v表示ω中的稀疏特征向量;n
表示训练数据集中健康声音无线通信信号的数量,n-表示训练数据集中不健康声音无线通信信号的数量;表示稀疏特征向量对应的不健康声音识别结果;将使得模型参数计算公式达到最小的w,b作为训练得到的模型参数。
7.如权利要求1所述的一种基于空气传导下的学习耳机智能消除不健康声音方法,其特征在于,所述s4步骤中将无线通信信号稀疏特征向量输入到不健康声音识别模型中,模型输出无线通信信号的检测识别结果,并将检测得到的不健康声音进行消除,包括:所述学习耳机所接收到的所有无线通信信号稀疏特征向量输入到不健康声音识别模型中,模型输出无线通信信号的检测识别结果,并将检测得到的不健康声音无线通信信号进行过滤消除。8.一种基于空气传导下的学习耳机智能消除不健康声音装置,其特征在于,所述装置包括:信号接收装置,用于接收室内蓝牙无线通信和wifi无线通信的通信信号,并对所接收的无线通信信号进行数模转换;信号特征提取模块,用于将无线通信信号转化为时频瀑布图,利用多尺度特征提取方法提取无线通信信号在时频瀑布图上的结构特征向量,对提取得到的结构特征向量进行稀疏表示处理,得到无线通信信号稀疏特征向量;不健康声音消除装置,用于构建基于vc维理论的不健康声音识别模型,将无线通信信号稀疏特征向量输入到模型中,模型输出无线通信信号的检测识别结果,并将检测得到的不健康声音无线通信信号进行消除,以实现一种如权利要求1-7所述的基于空气传导下的学习耳机智能消除不健康声音方法。
技术总结
本发明涉及声音过滤消除的技术领域,揭露了一种基于空气传导下的学习耳机智能消除不健康声音方法,包括:接收无线通信信号,并将其转化为时频瀑布图;利用多尺度特征提取方法提取无线通信信号在时频瀑布图上的结构特征向量;对提取得到的结构特征向量进行稀疏表示处理;构建基于VC维理论的不健康声音识别模型,将无线通信信号稀疏特征向量输入到模型中,模型输出无线通信信号的检测识别结果,并对不健康声音进行消除。本发明所提取多尺度结构特征具有几何不变性,避免几何局部区域的信号强度变化对所提取特征造成影响,将无线通信信号稀疏特征向量映射到基于VC维理论的高维空间,在高维空间进行更为准确的不健康声音无线通信信号检测识别。信号检测识别。信号检测识别。
技术研发人员:余安云 张美群 黄珍英
受保护的技术使用者:东莞市杰讯电子科技有限公司
技术研发日:2022.10.20
技术公布日:2023/1/31
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。