技术特征:
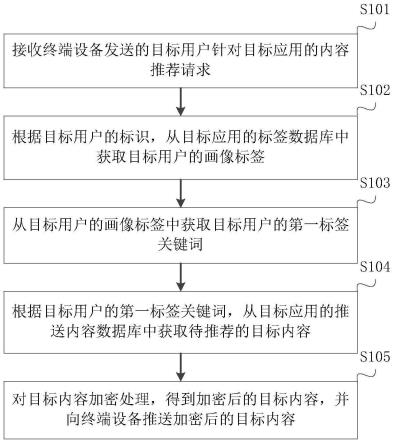
1.一种基于形状与语义增强的多模态图像语义分割方法,其特征在于,包括如下步骤:步骤1、从rgb传感器和thermal传感器中分别获取rgb图像和thermal图像,并通过标定算法进行图像对齐,再通过裁剪统一图像大小;由此构成数据集q,将数据集q划分为训练集q
train
和测试集q
test
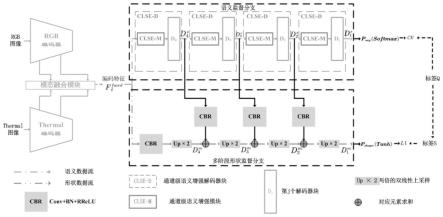
;步骤2、构建基于形状和语义增强的多模态图像语义分割网络模型;步骤3、对多模态图像语义分割网络模型进行模型训练,保存训练完成且性能良好的网络模型;步骤4、rgb传感器和thermal传感器实时获取rgb图像和thermal图像,输入当前训练完成且性能良好的网络模型,对当前图像进行语义分割。2.根据权利要求1所述基于形状与语义增强的多模态图像语义分割方法,其特征在于,多模态图像语义分割网络的解码器端分为多阶段形状监督分支和语义监督分支,其中,语义监督分支包含多个通道级语义增强解码器块clse-d,每个clse-d包含通道级语义增强模块clse-m和解码器块d
j
;多阶段形状监督分支使用符号距离图进行监督来保持分割结果的几何形状信息。3.根据权利要求1所述基于形状与语义增强的多模态图像语义分割方法,其特征在于,多模态图像语义分割网络模型的具体工作流程为:步骤2.1、分别将传感器采集的rgb图像和thermal图像数据输入到rgb编码器和thermal编码器中,模态融合模块对编码器中的图像数据进行融合,得到特征c表示特征通道数,h表示特征的高度,w表示特征的宽度;步骤2.2、在语义监督分支,通过clse-d解码器块得到每层解码器的输出如式(1)所示,式中,表示上一层通道级语义增强解码器块的输出;clse-m(*)表示通道级语义增强模块;d
j
表示第j个解码器块;表示通道级语义增强解码器块的输出特征;clse-d解码器块的具体工作过程为:在clse-m模块中,首先将输入特征分别通过一个全局最大池化gmp和全局平均池化gap,然后将输出结果进行对应像素相加,得到特征接着通过一个1
×
1的卷积层conv进行降维,得到特征其中τ=16,然后通过relu激活函数和一个1
×
1卷积层进行升维,得到特征最后通过如式(2)所示的sigmoid激活函数得到加权系数w
n
,具体计算如式(3)所示;将得到的w
n
与输入特征进行加权相乘并相加得到如式(4)所示;最后通过原始网络的解码器块d
j
得到clse-d的输出特征如式(5)所示;其中,x表示特征的每个像素值;
其中,表示逐个元素相加;其中,表示逐个元素相乘;步骤2.3、在多阶段形状监督分支,分别对语义监督分支的多阶段解码特征进行深度监督;首先将特征或通过一个1
×
1卷积进行降维,得到一个单通道的特征,然后通过标准的批量归一化层bn与随机纠正线性单元激活函数rrelu;如果输入是特征还需与前一层的输出特征相加;最后通过双线性插值up2进行两倍上采样得到如式(6)和式(7)所示,和式(7)所示,4.根据权利要求1所述基于形状与语义增强的多模态图像语义分割方法,其特征在于,所述步骤3的具体过程如下:步骤3.1、采用训练集q
train
训练模型,学习率设置为0.01,使用指数函数降低学习率,迭代次数为200次;优化器采用0.9的momentum,权重衰减设置为0.0005;数据增强策略和批次大小与插入的现有技术中的网络设置一致;步骤3.2、通过训练,将语义监督分支得到的输出特征通过如式(8)所示的softmax函数得到p
seg
,然后与语义标签q进行加权ce损失计算,得到语义损失值l
seg
,如式(9)所示;将形状监督分支得到的输出特征通过tanh激活函数得到p
shape
,然后与如式(10)所示的符号距离图标签s进行平均绝对误差损失值计算,得到形状损失值l
shape
,如式(11)所示;最后将计算后的两个损失值进行权重相加得到总损失值l
total
,如式(12)所示,其中,k为类别的个数,x
k
表示第k个类别的预测值,p
seg
表示语义监督分支得到的预测结果;其中,m表示输入图像的宽度,n表示输入图像的高度,m表示图像的横坐标索引,n表示图像的纵坐标索引,x
mn
表示坐标(m,n)对应的图像像素值,q表示语义分割的语义标签,w表示每个类别对应的权重,l
seg
表示语义监督分支得到的损失值;
其中,p和q分别表示语义标签中不同的像素,||*||2表示欧几里得范数,表示以目标对象的边界作为下确界,表示目标对象的边界,ω
in
和ω
out
分别表示目标对象的内部区域和外部区域,s(p)表示符号距离图在p点的结果;其中,p
shape
表示形状监督分支得到的预测结果,s表示符号距离图标签;l
total
=λ1×
l
seg
λ2×
l
shape
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)其中,λ1和λ2分别表示l
seg
和l
shape
的对应权重;步骤3.3、通过迭代训练,保存结果最好的网络模型参数;步骤3.4、通过测试集q
test
对训练好的模型进行预测,得到语义分割结果,若预测的结果与测试集对应,则证明当前训练完成的网络模型性能良好,保存当前模型,否则,返回重新训练,直到得到性能良好的网络模型。
技术总结
本发明公开了一种基于形状与语义增强的多模态图像语义分割方法,属于图像处理技术领域,包括如下步骤:从可见光传感器和热红外传感器中分别获取RGB图像和Thermal图像,并通过算法进行图像对齐,再统一图像大小,构建数据集;构建基于形状和语义增强的多模态图像语义分割网络模型;对多模态图像语义分割网络模型进行模型训练,保存训练完成且性能良好的网络模型;RGB传感器和Thermal传感器实时获取RGB图像和Thermal图像,输入当前训练完成且性能良好的网络模型,对当前图像进行语义分割。本发明具有即插即用的特性,可以和现有的语义分割网络结合,有效提高图像分割性能,可以推广到自动驾驶、医学影像分析等应用场景,预期创造可观的经济价值。造可观的经济价值。造可观的经济价值。
技术研发人员:单彩峰 杨元健 韩军功 陈宇
受保护的技术使用者:山东科技大学
技术研发日:2022.10.28
技术公布日:2023/1/31
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。