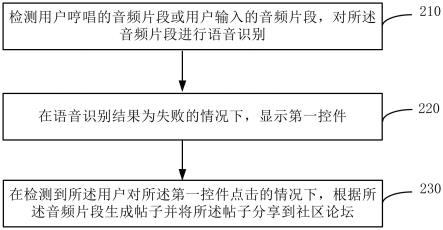
技术特征:
1.一种显示设备,其特征在于,包括:显示器;声音采集器,被配置为采集用户输入的语音;控制器,被配置为:基于待翻译实体和显示设备中预先存储的语句模板获取待翻译语句;将所述待翻译语句翻译成预设语言的目标语句;基于所述目标语句获取所述待翻译实体对应的目标实体;基于所述目标实体和所述预先存储的语句模板生成语音识别模型;响应于所述声音采集器采集的用户语音,基于所述语音识别模型对所述用户语音进行识别,得到所述用户语音对应的控制指令并执行所述控制指令。2.根据权利要求1所述的显示设备,其特征在于,所述控制器执行基于待翻译实体和显示设备中预先存储的语句模板获取待翻译语句,还被配置为:获取所述待翻译实体的目标实体类型;在预设的数据库中,基于所述目标实体类型对所述语句模板进行筛选,得到所述目标实体类型对应的目标语句模板;所述数据库中预先存储有若干个语句模板;基于所述待翻译实体和所述目标语句模板,获取待翻译语句。3.根据权利要求2所述的显示设备,其特征在于,所述语句模板中包括第一固定实体和若干个待填充槽位,所述待填充槽位和实体类型之间存在匹配关系;所述控制器执行基于所述目标实体类型对所述语句模板进行筛选,还被配置为:基于预设的筛选条件对所述数据库中的语句模板进行筛选;所述预设的筛选条件为:如果所述语句模板中存在至少一个待填充槽位和所述目标实体类型相匹配,则确定所述语句模板为目标语句模板。4.根据权利要求3所述的显示设备,其特征在于,所述控制器执行基于所述待翻译实体和所述目标语句模板,获取待翻译语句,还被配置为:确定所述目标语句模板中所述待翻译实体对应的目标待填充槽位,以及所述目标待填充槽位之外的剩余待填充槽位;在所述数据库中,获取所述剩余待填充槽位对应的种子实体对,所述种子实体对包括所述待翻译实体对应的初始语言的第一种子实体和所述预设语言的第二种子实体;将所述待翻译实体填充到所述目标待填充槽位中,以及将所述第一种子实体填充到所述剩余待填充槽位中,得到待翻译语句。5.根据权利要求4所述的显示设备,其特征在于,所述控制器执行基于所述目标语句获取所述待翻译实体对应的目标实体,还被配置为:对所述目标语句进行分词处理,得到分词结果;每个所述目标语句对应一个分词结果;基于所述分词结果获取每个所述目标语句对应的候选实体;对所述候选实体进行筛选,得到所述待翻译实体对应的目标实体。6.根据权利要求5所述的显示设备,其特征在于,所述控制器执行基于所述分词结果获取每个所述目标语句对应的候选实体,还被配置为:在所述数据库中,获取所述目标语句模板对应的匹配语句模板,所述匹配语句模板中包括第二固定实体和所述若干个待填充槽位,所述第二固定实体为所述第一固定实体在所
述预设语言下对应的实体;在所述分词结果中,获取除所述第二固定实体和所述第二种子实体外的剩余分词,并将所述剩余分词确定为每个所述目标语句对应的候选实体。7.根据权利要求5所述的显示设备,其特征在于,所述控制器执行对所述候选实体进行筛选,得到所述待翻译实体对应的目标实体,还被配置为:将所述候选实体翻译为所述初始语言下对应的初始语言候选实体;获取所述初始语言候选实体和所述待翻译实体的编辑距离;以及,获取所有的候选实体中,每个候选实体的出现次数;基于所述编辑距离、所述出现次数和预设的权重系数,计算所述候选实体的翻译得分,并将翻译得分最高的候选实体确定为所述待翻译实体对应的目标实体。8.根据权利要求1所述的显示设备,其特征在于,所述控制器执行基于所述目标实体和所述预先存储的语句模板生成语音识别模型,还被配置为:确定所述待翻译实体的初始语言;获取所述初始语言对应的第一语句模板以及所述预设语言对应的第二语句模板;基于所述待翻译实体和所述第一语句模板生成第一语音识别模型,基于所述目标实体和所述第二语句模板生成第二语音识别模型;所述第一语音识别模型用于识别所述初始语言对应的用户语音,所述第二语音识别模型用于识别所述预设语言对应的用户语音。9.根据权利要求1所述的显示设备,其特征在于,所述控制器执行基于所述目标实体和所述预先存储的语句模板生成语音识别模型,还被配置为:确定所述待翻译实体的初始语言;基于所述目标实体、所述待翻译实体和所述预先存储的语句模板生成第三语音识别模型,所述第三语音识别模型用于识别所述预设语言和所述初始语言对应的用户语音。10.一种语音识别方法,应用于显示设备,其特征在于,所述方法包括:基于待翻译实体和显示设备中预先存储的语句模板获取待翻译语句;将所述待翻译语句翻译成预设语言的目标语句;基于所述目标语句获取所述待翻译实体对应的目标实体;基于所述目标实体和所述预先存储的语句模板生成语音识别模型;响应于声音采集器采集的用户语音,基于所述语音识别模型对所述用户语音进行识别,得到所述用户语音对应的控制指令并执行所述控制指令。
技术总结
本申请一些实施例提供一种显示设备和语音识别方法。显示设备基于待翻译实体和预先存储的语句模板获取待翻译语句,并将待翻译语句翻译成预设语言的目标语句。显示设备基于目标语句获取待翻译实体对应的目标实体,并根据目标实体和语句模板生成语音识别模型。对于采集到的用户语音,显示设备基于语音识别模型对用户语音进行识别,得到用户语音对应的控制指令并执行。对于不同语言的用户语音,显示设备能够自行识别,而不是采用直译的方式,因此能够准确识别用户的语音,提高用户的使用体验。提高用户的使用体验。提高用户的使用体验。
技术研发人员:请求不公布姓名 曹晚霞
受保护的技术使用者:VIDAA国际控股(荷兰)公司
技术研发日:2022.09.29
技术公布日:2023/1/13
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。