技术特征:
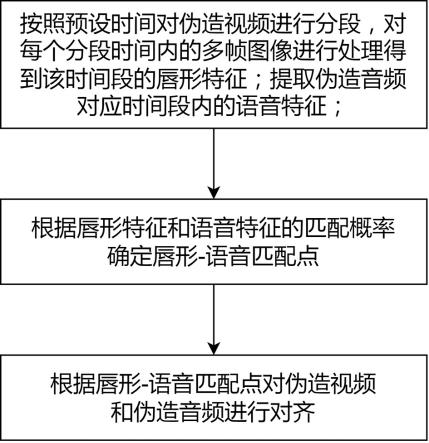
1.一种音视频伪造同步方法,其特征在于:包括如下步骤:按照预设时间对伪造视频进行分段,对每个分段时间内的多帧图像进行处理得到该时间段的唇形特征;提取伪造音频对应时间段内的语音特征;根据唇形特征和语音特征的匹配概率确定唇形-语音匹配点,其中匹配概率是利用唇形-语音匹配网络,对唇形特征和语音特征进行匹配识别得到的;根据唇形-语音匹配点对伪造视频和伪造音频进行对齐。2.如权利要求1所述的音视频伪造同步方法,其特征在于:所述的唇形-语音匹配点由初始匹配点和非初始匹配点构成,所述的根据唇形特征和语音特征的匹配概率确定唇形-语音匹配点以及根据唇形-语音匹配点对伪造视频和伪造音频进行对齐包括如下步骤:根据唇形特征和语音特征的匹配概率确定初始匹配点;根据初始匹配点对伪造视频和伪造音频进行第一次对齐;根据第一次对齐后的唇形特征和语音特征的匹配概率确定非初始匹配点;根据非初始匹配点对伪造视频和伪造音频进行第二次对齐。3.如权利要求2所述的音视频伪造同步方法,其特征在于:所述的根据唇形特征和语音特征的匹配概率确定初始匹配点包括:计算前m个时间段内的每个唇形特征和每个语音特征的匹配概率;根据匹配概率最大的唇形特征和语音特征对应的时间段确定初始匹配点;所述的根据初始匹配点对伪造视频和伪造音频进行第一次对齐包括:根据初始匹配点将伪造视频或伪造音频沿时间轴整体右移使得伪造视频时间轴上的初始匹配点和伪造音频时间轴上的初始匹配点处于同一时刻。4.如权利要求2所述的音视频伪造同步方法,其特征在于:所述的根据第一次对齐后的唇形特征和语音特征的匹配概率确定非初始匹配点包括:在伪造音频时间轴的上一个匹配点之后寻找伪造音频信号幅值大于预设阈值或达到预设间隔的时间点;根据该时间点确定语音特征时间段;在语音特征时间段预设范围内寻找匹配概率最大的唇形特征时间段;根据匹配概率最大的唇形特征和语音特征对应的时间段确定的下一个匹配点即为非初始匹配点。5.如权利要求4所述的音视频伪造同步方法,其特征在于:每确定下一个匹配点之后就通过如下任一步骤执行第二次对齐:步骤一、以音频为基准,对上一个匹配点和下一个匹配点之间的伪造视频进行抽帧或补帧处理使得伪造视频时间轴上的下一个匹配点对齐到伪造音频时间轴上的下一个匹配点所在时刻;步骤二、以视频为基准,对上一个匹配点和下一个匹配点之间的伪造音频进行加速或减速处理使得伪造音频时间轴上的下一个匹配点对齐到伪造视频时间轴上的下一个匹配点所在时刻。6.如权利要求4所述的音视频伪造同步方法,其特征在于:所述的根据匹配概率最大的唇形特征和语音特征对应的时间段确定初始匹配点或下一个匹配点的步骤中,以唇形特征和语音特征对应时间段的起点或中点或终点所处时刻作为匹配点。
7.如权利要求1所述的音视频伪造同步方法,其特征在于:所述的对每个分段时间内的多帧图像进行处理得到该时间段的唇形特征包括如下步骤:对每帧图像按如下步骤进行处理得到每帧图像对应的唇形特征:提取每帧图像中的唇形特征点;对唇形特征点进行曲线拟合得到唇形外轮廓和内轮廓;根据唇形外轮廓曲线求解外唇上下间的距离h1、周长l1、面积p1,根据唇形内轮廓曲线求解内唇上下间的距离h2、周长l2、面积p2;向量v=(h1,l1,p1,h2,l2,p2)即每帧图像的唇形特征;对每个分段时间内的多帧图像的唇形特征求取平均值得到该时间段的唇形特征。8.如权利要求1所述的音视频伪造同步方法,其特征在于:所述的提取伪造音频对应时间段内的语音特征包括:按照设定的参数读入伪造音频;对读入的伪造音频信号依次进行预加重、分帧以及加窗处理后得到多个独立的音频片段;利用快速傅里叶变换将音频片段从时域映射到频域上;利用梅尔倒谱系数的特征采集算法获取音频片段的mfcc值;对每个分段时间内的多个独立音频片段的mfcc值求取平均值得到该时间段的语音特征。9.如权利要求1所述的音视频伪造同步方法,其特征在于:所述按照预设时间对伪造视频进行分段的步骤中,分段时间长度为200~500ms。10.一种音视频伪造系统,其特征在于:包括采集模块、伪造模块、同步模块以及输出模块;所述的采集模块包括摄像头和麦克风分别用于获取用户实时人脸数据和声音数据;伪造模块包括换脸引擎和变声引擎,换脸引擎用于根据人脸数据伪造目标对象的同表情数据得到伪造视频,变声引擎用于根据声音数据伪造目标对象的声音得到伪造音频;同步模块根据权利要求1中所述的步骤对伪造视频和伪造音频进行对齐处理后输出至输出模块;输出模块包括虚拟摄像头和虚拟麦克风分别用于输出对齐后的伪造视频和伪造音频。
技术总结
本发明特别涉及一种音视频伪造同步方法及其构成的伪造系统,其中音视频伪造同步方法,包括如下步骤:按照预设时间对伪造视频进行分段,对每个分段时间内的多帧图像进行处理得到该时间段的唇形特征;提取伪造音频对应时间段内的语音特征;根据唇形特征和语音特征的匹配概率确定唇形-语音匹配点;根据唇形-语音匹配点对伪造视频和伪造音频进行对齐。根据这唇形特征和语音特征去进行匹配,从而确定匹配点,根据匹配点进行对齐就能方便的实现伪造音视频整体的对齐,匹配点和对齐的过程是可以持续进行的,每寻找到匹配点即可进行一次对齐,因此该对齐方法时效性强,非常适用于远程视频会议、直播等场景。直播等场景。直播等场景。
技术研发人员:田辉 邹远方 彭胜聪 郭玉刚 张志翔
受保护的技术使用者:合肥高维数据技术有限公司
技术研发日:2022.12.01
技术公布日:2022/12/30
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。