技术特征:
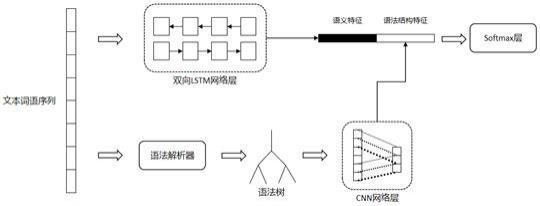
1.一种基于语法序列嵌入模型的售电公司评价情感分类方法,其特征在于,包括如下步骤:步骤(1),在电力零售交易平台上对所有售电公司随机采集评论数据,并对数据进行清洗和过滤以去除无语义内容,然后对剩余的数据进行情感类别标注;之后对数据进行划分,划分为训练集和测试集;步骤(2),将训练集输入到基于语法序列嵌入的语义融合深度模型中,以交叉熵作为损失函数进行训练,并采用测试集进行测试,获得构建好的基于语法序列嵌入的语义融合深度模型;所述的基于语法序列嵌入的语义融合深度模型中,采用双向lstm网络层进行语义特征提取;采用cnn网络层进行语法结构特征提取;之后将提取的语义特征和语法结构特征进行拼接后输入到softmax层进行类别预测;双向lstm网络层的输入为句子中所有词语经过嵌入处理后构成的矩阵;cnn网络层的输入为语法嵌入矩阵;softmax层输出为情感类别的概率;所述的语法嵌入矩阵表示为m∈r
k
×
n
,其中,k为语法嵌入的维度,n为句子包含的单词数;步骤(3),采用构建好的基于语法序列嵌入的语义融合深度模型对电力零售交易平台的评论数据进行情感分类。2.根据权利要求1所述的基于语法序列嵌入模型的售电公司评价情感分类方法,其特征在于,步骤(1)中,标注的类别共有5类,分别用1-5进行表示。3.根据权利要求1所述的基于语法序列嵌入模型的售电公司评价情感分类方法,其特征在于,步骤(1)中,数据以4:1的比例划分训练集和测试集。4.根据权利要求1所述的基于语法序列嵌入模型的售电公司评价情感分类方法,其特征在于,步骤(2)中,语法嵌入矩阵的获取方法为:包含n个词语的句子s={w1,w2,
…
,w
n
},对于第i个词语w
i
,i=1,2,
…
,n,其对应的从语法树根节点到叶子节点的路径为p(w
i
);p(w
i
)表示为序列{t1,t2,
…
,t
l
},其中,t
j
为语法标签,j=1,2,
…
,l;p(w
i
)为词语w
i
的语法序列;句子s中所有词语的语法序列构成的集合p={p(w
i
),i=1,2,
…
,n};通过对语法序列中所有语法标签嵌入求和计算得到语法路径的嵌入表示,如式(1)所示;在式(1)中,词语w
i
对应的语法序列为p(w
i
),p(w
i
)包含l个语法标签,分别是从t1一直到t
l
,其中语法标签t
j
对应的语法嵌入向量为vector(t
j
),1≤j≤l;通过将语法标签t1到t
l
对应的语法嵌入进行相加,得到语法序列p(w
i
)对应的嵌入向量表示vector(p(w
i
)),又因语法序列p(w
i
)为词语w
i
对应的语法序列,故词语w
i
对应的语法嵌入向量亦为vector(p(w
i
));将句子s中所有词语对应的语法嵌入向量按序排列可得语法嵌入矩阵m∈r
k
×
n
,如式(2)所示;其中k为单个词语语法嵌入的维度,n为句子s包含的单词数,语法嵌入矩阵m即表示了
句子s的语法结构信息;5.根据权利要求1所述的基于语法序列嵌入模型的售电公司评价情感分类方法,其特征在于,步骤(2)中,cnn网络层包括卷积层和池化层;卷积层用于对文本局部语法结构特征进行提取,具体为:使用固定窗口的卷积过滤器f∈r
k
×
s
对语法嵌入矩阵m∈r
k
×
n
进行滑动处理,其中k为语法嵌入向量的维度,s为过滤器每次处理的窗口长度,n为句子中词语的个数,卷积过滤器在第i个窗口进行特征提取的结果为c
i
,如式(3)所示;c
i
=f(f
·
m[i:i s-1] b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)其中,f为非线性激活函数relu,b为偏置量,过滤器f在语法嵌入矩阵m上以固定为1的步长进行滑动,并对所有长度为s的窗口m[i:i s-1]进行特征提取,其中i∈[1,2,...,n-s 1],完成特征提取后所得的特征映射图向量为c
syntax
={c1,c2,
…
,c
n-s 1
};采用m个窗口大小相同的卷积过滤器对语法嵌入矩阵m∈r
k
×
n
进行处理,从而得到多个对应的特征映射图向量,构成特征矩阵;使用最大池化层化对每个特征映射图进行池化操作,即对m个特征映射图向量取向量中的最大值,如式(4)所示;在式(4)中,pool
j
为对第j个卷积过滤器产生的特征映射图向量进行最大池化的结果,j=1,2,...,m,max为对向量c
jsyntax
计算最大值的函数,c
jsyntax
为第j个卷积过滤器特征提取后所得的特征映射图向量;在得到所有特征映射图向量池化结果后,将这些池化结果进行拼接得到最终的语法结构特征向量r
syntax
,如式(5)所示;r
syntac
=[pool1,pool2,...,pool
m
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)。6.根据权利要求1所述的基于语法序列嵌入模型的售电公司评价情感分类方法,其特征在于,步骤(2)中,使用双向lstm网络层对输入的文本词语嵌入矩阵进行语义特征提取,具体为:对与一个包含有n个按序排列词语的句子s={w1,w2,...,w
n
},通过一个词典嵌入矩阵e∈r
d
×
v
以及式(6)来查询每个词语对应的分布式嵌入表示,其中,在词典嵌入矩阵中,d为词嵌入向量维度,v为词汇表的数量,在glove预训练词向量中随机挑选100万个300维的词向量来构造词典嵌入矩阵,即d=300,v=1000000,r为实数空间,w
i
为句子中第i个词语,i=1,2,..,n;e
i
=eo
i
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)在式(6)中,o
i
是词语w
i
对应的维度为v的one-hot编码,即在o
i
中,只有词语w
i
对应维度的值为1,其余值均为0,从而将o
i
与e相乘便可得到词语w
i
对应的词向量e
i
;而后将句子s中所有词语的词向量进行堆叠得到一个词向量矩阵w∈r
d
×
n
,其中,d为词向量维度,n为句子s中词语数量,r为实数空间,之后将词向量矩阵w作为双向lstm网络层的输入;
双向lstm网络层包含多个神经元,每个神经元均包含遗忘门、输入门和输出门;对于当前神经元,遗忘门首先接收上一神经元的输出h
t-1
和当前输入x
t
来计算遗忘权重f
t
,如公式(7)所示,其中当前输入x
t
就是词向量矩阵w中的第t行构成的向量,1≤t≤n且t为整数,该遗忘权重用于后续与上一神经元的状态c
t-1
进行相乘来决定保留哪些历史状态,如公式(10)所示;在公式(7)中,w
f
为遗忘权重f
t
的参数矩阵,b
f
为遗忘权重f
t
的偏移量,σ为sigmoid激活函数;f
t
=σ(w
f
·
[h
t-1
,x
t
] b
f
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)输入门接收上一单元输出h
t-1
和当前输入x
t
来计算得到当前哪些信息需要被记忆的权重i
t
,如公式(8)所示,同时,输入门还通过公式(9)计算当前神经元的候选状态c
t’;在公式(8)和(9)中,w
i
和w
c
分别为记忆权重i
t
和候选状态c
t’的参数矩阵,b
i
和b
c
则分别为记忆权重i
t
和候选状态c
t’的偏移量,σ为sigmoid激活函数,tanh为tanh激活函数;最终使用公式(10)的加权和公式计算得出当前神经元的终态c
t
;i
t
=σ(w
i
·
[h
t-1
,x
t
] b
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)c
′
t
=tanh(w
c
·
[h
t-1
,x
t
] b
c
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)c
t
=f
t
*c
t-1
i
t
*c
′
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)之后输出门将基于前一神经元输出h
t-1
和当前输入x
t
来计算一个输出权重o
t
,如公式(11)所示,wo为输出权重o
t
的参数矩阵,b
o
为输出权重o
t
的偏移量,σ为sigmoid激活函数,最后,输出权重o
t
与经过tanh激活函数处理过的神经元状态c
t
相乘,得到当前神经元的输出信息h
t
,如公式(12)所示;o
t
=σ(w
o
·
[h
t-1
,x
t
] b
o
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)h
t
=o
t
*tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)双向lstm网络层分别使用两个反向的lstm对输入序列进行建模,定义输入词语w
i
(i=1,2,...,n)对应的正向和反向lstm输出状态分别为和将其拼接得到当前输入的状态表示对于包含n个词语的句子,经过双向lstm处理后得到的特征表示为h={h1,h2,...,h
n
}。7.根据权利要求1所述的基于语法序列嵌入模型的售电公司评价情感分类方法,其特征在于,将提取的语义特征和语法结构特征进行拼接后输入到softmax层,具体为:将语法结构特征表示r
syntax
及语义特征表示h进行拼接后得到最终的语法语义融合特征a,如式(13)所示;a=[r
syntax
,h]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)在得到语法语义融合特征a后,将a输入到一个全连接层通过softmax函数进行归一化处理,最终得到文本属于每个类别概率构成的向量p=(p1,p2,...,p
n
),其中p
j
为该文本属于第j个类别的概率,j=1,2,...,n,n为类别总数,如公式(14)所示,其中w
a
和b
a
分别为参数矩阵和p相对于参数矩阵的偏移量,softmax为归一化激活函数;p=soft max(a
·
w
a
b
a
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)。8.根据权利要求1所述的基于语法序列嵌入模型的售电公司评价情感分类方法,其特征在于,以交叉熵作为损失函数,具体为:假设待分类数据集共有n个类别,则对于某个样本,分别将其对于第i个类别预测概率p
i
取对数后与指示变量y
i
相乘,指示变量y
i
来源于训练数据的标签,假设该样本的标签确定该样本属于第j类,0<j≤n,则y
i
为1,其他y
i
(0<i≤n,i≠j)为0;并将所有相乘结果相加后取负值即可得到该样本的损失函数值l,如公式(15)所示;在模型训练过程中,每一轮迭代都需对所有样本计算损失函数值并得出样本的损失函数均值,而后计算损失函数对于各模型参数的梯度,并通过学习率对模型参数进行基于梯度方向的更新。9.根据权利要求1所述的基于语法序列嵌入模型的售电公司评价情感分类方法,其特征在于,还包括:从电力零售交易平台中获取各售电公司的所有评价数据,使用构建好的基于语法序列嵌入的语义融合深度模型分别对各售电公司的评价数据进行情感分类,根据分类结果统计售电公司在零售市场的好评率和差评率;所述的好评率为情感类别为5的评价数量占评价总数的比例;所述的差评率为情感类别为1的评价数量占评价总数的比例,并对电力零售用户推荐好评率排名前十的售电公司。
技术总结
本发明涉及一种基于语法序列嵌入模型的售电公司评价情感分类方法,首先,在电力零售交易平台上对所有售电公司随机采集评论数据,并对数据进行清洗和过滤;然后进行情感类别标注;并将数据划分为训练集和测试集;将训练集输入到基于语法序列嵌入的语义融合深度模型中,以交叉熵作为损失函数进行训练,并采用测试集进行测试,获得构建好的基于语法序列嵌入的语义融合深度模型;采用构建好模型对电力零售交易平台的评论数据进行情感分类。本发明通过基于文本语法树嵌入序列的神经网络模型实现对售电公司的评价文本进行语法结构分析、语义建模来实现情感分类,分类结果可以作为交易中心评估售电公司服务质量、信用等级、运营水平的一个重要指标。平的一个重要指标。平的一个重要指标。
技术研发人员:宝君维 陈然 张加贝 赵伟华 蔡华祥 张茂林 王帮灿 丁文娇
受保护的技术使用者:昆明电力交易中心有限责任公司
技术研发日:2022.08.24
技术公布日:2022/12/16
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。