技术特征:
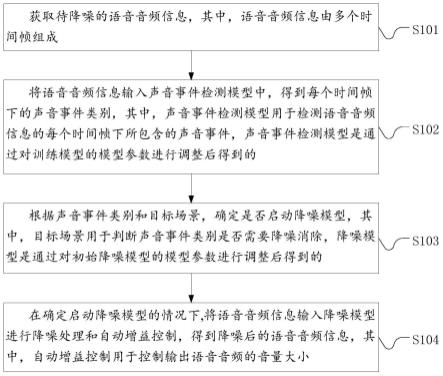
1.一种声音降噪方法,其特征在于,所述方法包括:获取待降噪的语音音频信息,其中,所述语音音频信息由多个时间帧组成;将所述语音音频信息输入声音事件检测模型中,得到每个时间帧下的声音事件类别,其中,所述声音事件检测模型用于检测所述语音音频信息的每个时间帧下所包含的声音事件,所述声音事件检测模型是通过对训练模型的模型参数进行调整后得到的;根据所述声音事件类别和目标场景,确定是否启动降噪模型,其中,所述目标场景用于判断所述声音事件类别是否需要降噪消除,所述降噪模型是通过对初始降噪模型的模型参数进行调整后得到的;在确定启动所述降噪模型的情况下,将所述语音音频信息输入所述降噪模型进行降噪处理和自动增益控制,得到降噪后的语音音频信息,其中,所述自动增益控制用于控制输出语音音频的音量大小。2.根据权利要求1所述的方法,其特征在于,在所述将所述语音音频信息输入声音事件检测模型中之前,所述方法还包括:确定不需要降噪的声音事件,划分声音事件类别;获取由多种所述声音事件类别组成的多种音频数据,其中,每种所述音频数据由多个时间帧组成,且在同一时间帧中对应至少一种所述声音事件类别,每个时间帧携带有包含的所述声音事件类别的类别标签;根据多种所述音频数据生成训练样本;提取所述训练样本中目标音频数据的语音特征信息,并进行编码,得到目标编码特征,同时确定所述目标编码特征对应的至少一种所述声音事件类别;将所述目标编码特征输入所述训练模型,得到所述目标编码特征属于每种目标声音事件类别的初始概率,更新所述训练模型的模型参数,直到属于每种所述目标声音事件类别的初始概率都大于第一预设阈值,则训练完成,得到所述声音事件检测模型,其中,所述目标编码特征携带有属于所述目标声音事件类别的所述类别标签,所述目标声音事件类别的数量至少为一个。3.根据权利要求2所述的方法,其特征在于,所述根据多种所述音频数据生成训练样本包括:从所述音频数据中随机抽样并时域叠加,生成训练数据;通过预设方法扩充所述训练数据的数据量,得到所述训练样本,其中,所述预设方法用于增扩所述训练数据的数据量。4.根据权利要求1所述的方法,其特征在于,在所述得到每个时间帧下的声音事件类别之后,所述方法还包括:生成时间窗,其中,所述时间窗由预设数量个时间帧组成;以一个时间帧为步长,将所述时间窗在所述语音音频信息的时间轴上向前滑动预设距离,生成所述时间窗经过的每一时间帧下出现目标声音事件类别的概率,其中,若所述概率大于第二预设阈值,则对应时间帧的音频属于所述目标声音事件类别,若所述概率小于第二预设阈值,则对应时间帧的音频不属于所述目标声音事件类别,所述预设距离包含所有需要通过所述时间窗判断所述音频是否属于目标声音事件类别的时间帧。5.根据权利要求1所述的方法,其特征在于,在所述将所述语音音频信息输入所述降噪
模型进行降噪处理和自动增益控制之前,所述方法还包括:利用干净音频和噪声音频生成加噪音频,构建训练集,其中,所述干净音频为信噪比大于噪声阈值的音频,所述噪声音频为信噪比小于所述噪声阈值的音频,其中,所述噪声阈值为音频中包含噪声的临界值;提取所述干净音频的频域特征和所述加噪音频的频域特征;将所述加噪音频的频域特征输入初始降噪模型中得到属于所述干净音频的频域特征的初始概率,更新所述初始降噪模型的模型参数,直到属于所述干净音频的频域特征的初始概率大于第三预设阈值,则训练完成,得到所述降噪模型,其中,所述加噪音频中包含干净音频,在所述加噪音频的频域特征中携带有干净音频的频域特征标签。6.根据权利要求1所述的方法,其特征在于,所述将所述语音音频信息输入所述降噪模型进行降噪处理和自动增益控制包括:在接收到所述降噪模型启动的指示信息的情况下,获取启动降噪模型的时间帧在所述待降噪的语音音频信息中所处的第一时间点;在接收到所述降噪模型关闭的指示信息的情况下,获取启动降噪模型的时间帧在所述待降噪的语音音频信息中所处的第二时间点;在所述第一时间点后设定数量的时间帧内,将输出音频信号的增益控制在预设区间内,利用调节参数渐进调节降噪模型的开启;或者,在所述第二时间点后设定数量的时间帧内,将输出音频信号的增益控制在所述预设区间内,利用所述调节参数渐进调节降噪模型的关闭。7.根据权利要求1所述的方法,其特征在于,所述根据所述声音事件类别和目标场景,确定是否启动降噪模型包括:根据所述目标场景确定需要降噪消除的声音事件类别与不需要降噪消除的声音事件类别;将所有需要降噪消除的声音事件类别每个时间帧下的特征编码全部置零,将所有不需要降噪消除的声音事件类别每个时间帧下的所述特征编码之间先进行逻辑或操作,再进行逻辑非操作,得到数字标识;根据所述数字标识,确定是否启动所述降噪模型。8.一种声音降噪装置,其特征在于,所述装置包括:获取模块,用于获取待降噪的语音音频信息,其中,所述语音音频信息由多个时间帧组成;第一得到模块,用于将所述语音音频信息输入声音事件检测模型中,得到每个时间帧下的声音事件类别,其中,所述声音事件检测模型用于检测所述语音音频信息的每个时间帧下所包含的声音事件,所述声音事件检测模型是通过对训练模型的模型参数进行调整后得到的;确定模块,根据所述声音事件类别和目标场景,确定是否启动降噪模型,其中,所述目标场景用于判断所述声音事件类别是否需要降噪消除,所述降噪模型是通过对初始降噪模型的模型参数进行调整后得到的;第二得到模块,用于在确定启动所述降噪模型的情况下,将所述语音音频信息输入所述降噪模型进行降噪处理和自动增益控制,得到降噪后的语音音频信息,其中,所述自动增
益控制用于控制输出语音音频的音量大小。9.一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,所述处理器、所述通信接口和所述存储器通过所述通信总线完成相互间的通信,其特征在于,所述存储器,用于存储计算机程序;所述处理器,用于通过运行所述存储器上所存储的所述计算机程序来执行权利要求1至7中任一项中所述的方法步骤。10.一种计算机可读的存储介质,其特征在于,所述存储介质中存储有计算机程序,其中,所述计算机程序被处理器执行时实现权利要求1至7中任一项中所述的方法步骤。
技术总结
本申请提供了一种声音降噪方法和装置、电子设备和存储介质,其中,该方法包括:获取待降噪的语音音频信息,其中,语音音频信息由多个时间帧组成;将语音音频信息输入声音事件检测模型中,得到每个时间帧下的声音事件类别;根据声音事件类别和目标场景,确定是否启动降噪模型;在确定启动降噪模型的情况下,将语音音频信息输入降噪模型进行降噪处理和自动增益控制,得到降噪后的语音音频信息,其中,自动增益控制用于控制输出语音音频的音量大小。通过本申请,解决了相关技术中存在无法区分声音事件、会消除所有非语音声音的问题。会消除所有非语音声音的问题。会消除所有非语音声音的问题。
技术研发人员:苏悦 张新科 崔潇潇 鲁勇
受保护的技术使用者:北京探境科技有限公司
技术研发日:2022.07.27
技术公布日:2022/12/12
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。