技术特征:
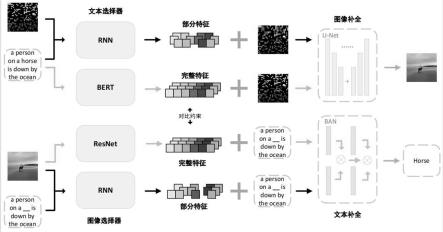
1.一种小规模数据视觉语言预训练方法,其特征在于:对于图像端的预训练子任务,采用u-net网络,在编码缺失图像之后,在每组对应的下采样和上采样阶段之间与额外输入的文本特征进行通道注意力,利用文本信息来进行图像的补全,将编码特征和文本描述特征融合,输入到解码器中,解码成一个正常图像;对于文本端的预训练子任务,使用双线性注意力网络;其中,将文本特征记为x,图像特征为y,注意力权重图w根据不同模态特征之间的亲和度计算得到,在注意力权重图的辅助下,进行x和y之间的特征融合,最终输出缺失单词的预测结果。2.根据权利要求1所述的小规模数据视觉语言预训练方法,其特征在于:在图像端的预训练子任务中,对文本使用文本选择器;在文本端对图像使用图像选择器;所述文本选择器和图像选择器采用循环神经网络,逐位的输出每个区域的选择结果;所述文本选择器的输入为缺失的图像和完整的文本,所述图像选择器的输入为缺失的文本和完整的图像。3.根据权利要求1所述的小规模数据视觉语言预训练方法,其特征在于:对于图像端的预训练子任务,在编码阶段,从输入图像中提取多种尺度的视觉特征;并通过特征提取得到文本特征f
t
,之后输入到模型当中,与编码器输出相融合;解码阶段时,先通过通道注意力机制将编码后的图像特征和文本特征进行特征融合;开始时,特征图通过一个全局池化层转换成一个特征向量,和文本特征连接到一起后,输入到一个带有softmax层的简单前馈神经网络,从而生成一个注意力权重,最终被用来更新特征值,以得到最终融合的特征:下标i∈{1,2,
…
,c
s
}表示索引通道,}表示索引通道,表示一个标量;u-net网络的解码器带有多个反卷积层;每一个反卷积层的输入由同一阶段的编码层输出的编码特征和文本特征结合后得到的融合特征和前一反卷积层的输出连接而成,第一个反卷积层使用编码器最后一层的输出代替前一反卷积层的输出;最后一层输出的特征图a,经过上采样和卷积之后作为最终的图像输出。4.根据权利要求3所述的小规模数据视觉语言预训练方法,其特征在于:在训练过程中,将子任务总体看成一个像素级别的回归问题,g
if
表示图像补全模型,将成对的缺失图像i
miss
和文本特征f
t
作为输入,最终输出补全后的图像i
normal
;原先的正常图像作为模型的补全目标,使用一个像素级的均方误差,如下所示:5.根据权利要求1所述的小规模数据视觉语言预训练方法,其特征在于:对于文本端的预训练子任务,对于给定两个模态的特征x,y,注意力权重根据不同模态特征之间的亲和度计算得来:其中u∈r
n
×
d
和v∈r
m
×
d
是映射矩阵,是一个向量,p
h
∈r
d
,其中是注意力图索引,是注意力图索引,是逐元素乘积;在注意力权重图的辅助下,模型进行x和y之间的特征融合,并在在模型中使用残差连
接,在第n个残差块中,模型输出如下所示:p∈r
d
×
c
是映射矩阵,x作为模型的初始输入f0,ban
h
是生成中间特征的函数,定义为:其中u'∈r
n
×
d
,v'∈r
m
×
d
,最后一层ban网络输出的结果输入到一个多层感知机构建的分类器之后,最终输出缺失单词的预测结果。6.根据权利要求5所述的小规模数据视觉语言预训练方法,其特征在于:将文本端的预训练子任务当作一个视觉问答问题,g
tf
表示文本补全模型,以成对的缺失的文本t
miss
和图像特征f
i
作为模型输入,最终输出缺失的单词t
tar
;模型预测目标为数据集的文本里被遮盖掉的部分;损失函数使用交叉熵损失,公式如下:
技术总结
本发明提出一种小规模数据视觉语言预训练方法,对于图像端,采用U-Net网络,在编码缺失图像之后,在每组对应的下采样和上采样阶段之间与额外输入的文本特征进行通道注意力,利用文本信息来进行图像的补全,将编码特征和文本描述特征融合,输入到解码器中,解码成一个正常图像;对于文本端,使用双线性注意力网络;其中,将文本特征记为X,图像特征为Y,注意力权重图w根据不同模态特征之间的亲和度计算得到,在注意力权重图的辅助下,进行X和Y之间的特征融合,最终输出缺失单词的预测结果。该技术方案在减少了预训练数据的规模的同时,提高了下游任务的表现。了下游任务的表现。了下游任务的表现。
技术研发人员:程航 叶贺辉 陈飞 王美清 刘蓉 王靖岳
受保护的技术使用者:薇链信息技术有限公司
技术研发日:2022.08.18
技术公布日:2022/11/11
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。