技术特征:
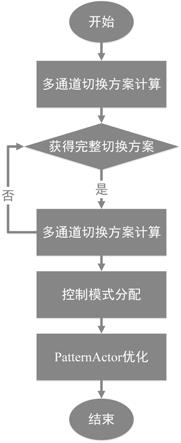
1.一种连续微流控生物芯片下基于drl的控制逻辑设计方法,其特征在于,包括如下步骤:s1、多通道切换方案计算:构建整数线性规划模型以最小化控制逻辑所需的时间片数量,获得多通道切换方案;s2、控制模式分配:获得多通道切换方案后,为多通道切换方案中每个多通道组合分配相应的控制模式;s3、patternactor优化:构建基于深度强化学习的控制逻辑合成方法,对生成的控制模式分配方案进行优化,以最小化所使用的控制阀门数量。2.根据权利要求1所述的连续微流控生物芯片下基于drl的控制逻辑设计方法,其特征在于,步骤s1具体实现如下:首先,给定生化应用中所有流阀门/控制通道的状态转换序列,通过构建状态矩阵来包含生化应用的整个状态转换过程,其中矩阵中的每一行表示每一时刻各控制通道的状态;将相应控制通道连接到核心输入,并将核心输入压力值置位后传输给对应的流阀门;其次,利用切换矩阵来表示在控制逻辑中需要执行的操作;在切换矩阵中,元素1代表的是某个控制通道此时已连接到核心输入并且当前控制通道中的状态值已更新为与核心输入的压力值相同;元素0则代表的是某个控制通道此时未连接到核心输入且当前控制通道中的状态值未进行更新;元素x表示前后两个时刻的状态值不变;切换矩阵的每一行都被称为一种切换模式;由于切换矩阵中的某一行可能存在多个1元素,该切换模式所对应的多个控制通道状态可能不会同时更新;此时需要将该切换模式划分成多个时间片,利用多个相应的多通道组合来完成该切换模式;对于切换矩阵而言,行数为完成所有状态转换所需的切换模式总数,列数为控制逻辑中控制通道总数;对于n个控制通道而言,通过列数为n的复用矩阵来表示2
n-1种多通道组合,其中需要从矩阵中的所有行中选择一种或多种组合来实现切换矩阵中每一行所表示的切换模式;针对切换矩阵中每一行的切换模式的多通道组合是由该切换模式中元素1的位置和个数决定的,即实现相应切换模式的可选多通道组合个数为2
n-1,这里的n表示切换模式中元素1的个数;因此,针对于切换矩阵中每一行的切换模式,构建联合向量组来包含能够组成每个切换模式的可选多通道组合;联合向量组中的向量组个数与切换矩阵的行数x'相同,且每个向量组中包含有2
n-1个维度为n的子向量,这些子向量都是实现相应切换模式的可选多通道组合;当联合向量组中元素m
i,j,k
为1时,则表示元素m
i,j,k
所对应的控制通道与实现第i个切换模式有关;由于多通道切换方案最终的目标是通过选择联合向量组中各向量组中子向量所表示的多通道组合来实现切换矩阵因此构建一个方法数组来表示针对切换矩阵中的每一行切换模式所使用的相应多通道组合位于中的位置;其中方法数组中包含x'个子
数组,且子数组的元素个数由该子数组所对应的切换模式中元素1的个数决定,即子数组中的元素个数为2
n-1;方法数组中第i个子数组表示选择中第i个向量组中的组合来实现切换矩阵第i行的切换模式;对于切换矩阵中的元素y
i,k
而言,当元素的值为1时则表明第i个切换模式涉及到第k个控制通道来实现状态切换,因此需要在联合向量组中的第i个向量组中选择一个在第k列也为1的子向量来实现该切换模式;此约束表示为:k列也为1的子向量来实现该切换模式;此约束表示为:其中h(j)表示联合向量组中第j个向量组中子向量的个数;m
i,j,k
和y
i,k
是已给定的常数,而t
i,j
则是值为0或1的二值变量;控制逻辑中允许被使用的最大控制模式数量是由外部压力源的数量所决定的,其表示为常数q
cw
且值为该值远小于2
n-1;另外对于从联合向量组中选择的子向量,构建一个值为0或1的二值行向量来记录最终选择的不重复的子向量即多通道组合;最终选择的不重复子向量总数不能够大于q
cw
,因此该约束如下:其中c表示的是联合向量组中包含的不重复的子向量总数;如果方法数组中第i个子数组的第j个元素不为1,那么对于联合向量组中第i个向量组的第j个子向量所表示的多通道组合则没有被选择;但与该子向量元素值相同的其他子向量可能存在于联合向量组中其他的向量组中,因此具有元素值相同的多通道组合仍可能被选择;仅当某个多通道组合在整个过程中没有被选择,那么在中对应此多通道组合的列元素则置为0,其约束为:素则置为0,其约束为:其中[m
i,j
]表示与联合向量组中第i个向量组中的第j个子向量元素值相同的多通道组合在中的位置;方法数组中每一个子数组表明从联合向量组的向量组中选择了哪些由子向量表示的多通道组合来实现切换矩阵中对应的切换模式;对于方法数组中每一个子数组中的1元素个数表示实现该子数组所对应在切换矩阵中的切换模式所需要的时间片数;因此为最小化实现切换矩阵中所有切换模式的时间片总数,解决的优化问题如下所示:
s.t.(1),(2),(3)通过求解如上所示的优化问题,根据的值来获得实现整个切换方案所需要的多通道组合;同样针对切换矩阵中每一行的切换模式所使用的多通道组合则由t
i,j
的值来决定;即当t
i,j
的值为1时,该多通道组合为m
i,j
表示的子向量的值。3.根据权利要求1所述的连续微流控生物芯片下基于drl的控制逻辑设计方法,其特征在于,步骤s2具体实现方式为:多通道切换方案由一个多路径矩阵表示,针对该多路径矩阵的每一行多通道组合分配相应的控制模式,并将这些控制模式写于多路径矩阵的右侧。4.根据权利要求1所述的连续微流控生物芯片下基于drl的控制逻辑设计方法,其特征在于,步骤s3中,所述基于深度强化学习的控制逻辑合成方法,采用双深度q网络和两种布尔逻辑简化技术为控制逻辑。5.根据权利要求1所述的连续微流控生物芯片下基于drl的控制逻辑设计方法,其特征在于,步骤s3中,patternactor优化过程,通过构建ddqn模型作为强化学习的agent,并采用深度神经网络dnns来记录数据;将控制逻辑中可用的控制端口数初始化为并且这些端口相应地形成种控制模式;patternactor优化过程具体实现如下:s31、patternactor的状态设计设计agent状态s:通过将时间t的多通道组合与所有时间内所选动作的编码序列串联起来以设计状态;多通道切换方案由一个多路径矩阵表示;编码序列的长度等于多路径矩阵的行数,即每个多通道组合对应一位动作码;所有状态构成一个状态空间s;s32、patternactor的动作设计设计agent动作a:通道组合需要分配相应的控制模式,动作即尚未被选择的控制模式,每个控制模式只允许被选择一次,所有由控制端口产生的控制模式构成动作空间a;此外,a中的控制模式都是按序号升序编码;当agent在某一状态下采取动作时,动作码表明哪种控制模式已被分配;s33、patternactor的奖赏函数设计设计agent奖赏函数r:通过设计状态的奖励函数,agent获得有效的信号并以正确的方式学习;对于一个多路径矩阵,假设矩阵的行数为h,相应地将初始状态表示为s
i
,终止状态表示为s
i h-1
;总体奖励函数表述如下:其中,表示当前状态下相应多通道组合分配可行的控制模式可以简化的控制阀数量;表示当前状态下下一个多通道组合分配可行的控制模式可以简化的控制阀数量;v
m
表示控制逻辑所需的最大控制阀数量;其中λ和β是两个权重因子;s
i h-2
、s
i h-3
分别为终止
状态s
i h-1
的前一个状态、前前一个状态;表示终止状态s
i h-1
下控制阀和路径长度之和;对于状态s
i h-2
,当当前的多通道组合已经分配控制模式时,考虑最后一个多通道组合选择剩余可用模式的情况,控制逻辑所需的控制阀最小数量由v
u
表示;s34、采用ddqn模型来设计控制逻辑,ddqn模型的结构由两个dnn组成,分别称为策略网络和目标网络,其中策略网络为状态选择动作,而目标网络评估所采取动作的质量;两者交替工作;在ddqn的训练过程中,为评估在当前状态s
t
中所采取动作的质量,策略网络首先找到动作a
max
,该动作使下一状态s
t 1
中的q值最大化,如下所示:其中θ
t
表示策略网络的参数;然后,下一个状态s
t 1
被传输到目标网络以计算动作a
max
的q值即q(s
t 1
,a
max
,θ
t-);最后,该q值用于计算目标值y
t
,该值用于评估在当前状态s
t
下所采取动作的质量,如下所示:y
t
=r
t
γq(s
t 1
,a
max
,θ
t-)其中θ
t-表示目标网络的参数;在为状态-动作对计算q值的过程中,策略网络以状态s
t
作为输入,而目标网络以状态s
t 1
作为输入;通过策略网络,获得状态s
t
下所有可能动作的q值,然后通过动作选择策略为状态s
t
选择动作;首先,策略网络确定q(s
t
,a2)的值;其次,通过策略网络找到下一个状态s
t 1
中具有最大q值的动作a1;然后,将下一个状态s
t 1
作为目标网络的输入,以获得动作a1的q值,即q(s
t 1
,a1),并根据y
t
=r
t
γq(s
t 1
,a
max
,θ
t-)获得目标值y
t
;q(s
t
,a2)作为策略网络的预测值,而y
t
作为策略网络的实际值;策略网络中的值函数通过使用策略网络的预测值和策略网络的实际值的误差反向传播进行校正,进而调整ddqn模型的策略网络和目标网络。6.根据权利要求5所述的连续微流控生物芯片下基于drl的控制逻辑设计方法,其特征在于,步骤s33中,奖奖励函数的设计采用两种布尔逻辑简化方法:逻辑树简化和逻辑森林简化。7.根据权利要求5所述的连续微流控生物芯片下基于drl的控制逻辑设计方法,其特征在于,步骤s34中,ddqn模型中的策略网络和目标网络都由两个全连接层组成,并以随机权重和偏置进行初始化;首先,分别初始化策略网络、目标网络和经验回放buffer相关的参数;经验回放buffer记录了每一轮中先前控制模式分配的信息transitions,由五个元素组成,即(s
t
,a
t
,r
t
,s
t 1
,done),第五个元素done表示是否已经达到终止状态,它是一个数值为0或1的变量;然后,训练回合episode初始化为常量e,agent准备好与环境进行交互;之后,由上述五个元素组成的transition被依次存储到经验回放buffer中;经过预定次数的迭代,agent准备从以前的经验中学习;在学习过程中,从经验回放buffer中随机选择transitions作为学习样本,使网络更新;并利用下式的损失函数,通过采用梯度下降反向传播来更新策略网络的参数;l(θ)=ε[(r
t
γq(s
t 1
,a
*
;θ
t-)-q(s
t
,a
t
;θ
t
))2]经过几个周期的学习,目标网络的旧参数会定期被策略网络的新参数替换最后,代理使用patternactor记录迄今为止找到的最佳解决方案;整个学习过程以设
置的训练回合数结束。8.根据权利要求5所述的连续微流控生物芯片下基于drl的控制逻辑设计方法,其特征在于,步骤s34中,动作选择策略采用ε-greedy策略,其中ε是一个随机生成的数字,分布在区间[0.1,0.9]上。
技术总结
本发明涉及一种连续微流控生物芯片下基于DRL的控制逻辑设计方法,旨在为控制逻辑寻求更有效的模式分配方案。首先,提出了一种有效求解多通道切换计算的整数线性规划模型,以最小化控制逻辑所需的时间片数量从而显著提高生化应用的执行效率。其次,提出了一种基于深度强化学习的控制逻辑合成方法,该方法利用双深度Q网络和两种布尔逻辑简化技术为控制逻辑寻求更有效的模式分配方案,从而带来了更好的逻辑合成性能和更低的芯片成本。的逻辑合成性能和更低的芯片成本。的逻辑合成性能和更低的芯片成本。
技术研发人员:郭文忠 蔡华洋 刘耿耿 黄兴 陈国龙
受保护的技术使用者:福州大学
技术研发日:2022.05.27
技术公布日:2022/9/6
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。