技术特征:
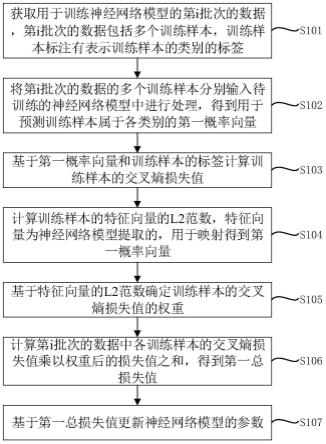
1.一种神经网络模型的训练方法,其特征在于,包括:获取用于训练神经网络模型的第i批次的数据,所述第i批次的数据包括多个训练样本,所述训练样本标注有表示所述训练样本的类别的标签;将所述第i批次的数据的多个所述训练样本分别输入待训练的神经网络模型中进行处理,得到用于预测所述训练样本属于各类别的第一概率向量;基于所述第一概率向量和所述训练样本的标签计算所述训练样本的交叉熵损失值;计算所述训练样本的特征向量的l2范数,所述特征向量为所述神经网络模型提取的,用于映射得到所述第一概率向量;基于所述特征向量的l2范数确定所述训练样本的交叉熵损失值的权重;计算所述第i批次的数据中各所述训练样本的交叉熵损失值乘以权重后的损失值之和,得到第一总损失值;基于所述第一总损失值更新所述神经网络模型的参数。2.根据权利要求1所述的神经网络模型的训练方法,其特征在于,基于所述特征向量的l2范数确定所述训练样本的交叉熵损失值的权重,包括:将所述第i批次的数据的多个训练样本对应的l2范数存入数据队列中;基于所述数据队列中所有l2范数的均值和标准差,以及所述训练样本的特征向量的l2范数确定所述训练样本的交叉熵损失值的权重。3.根据权利要求2所述的神经网络模型的训练方法,其特征在于,所述数据队列具有m
×
p个存储位,m为每一批次的数据中训练样本的数量,p为大于1的整数,将所述第i批次的数据的多个训练样本对应的l2范数存入数据队列中,包括:判断所述数据队列是否存在空置的存储位;若是,则从所述空置的存储位中确定待存储的目标存储位;若否,则擦除第i-p批次的数据的多个训练样本对应的l2范数,得到目标存储位;将所述第i批次的数据的多个训练样本对应的l2范数存入所述目标存储位中。4.根据权利要求2所述的神经网络模型的训练方法,其特征在于,基于所述数据队列中所有l2范数的均值和标准差,以及所述训练样本的特征向量的l2范数确定所述训练样本的交叉熵损失值的权重,包括:计算所述数据队列中所有l2范数的均值和标准差;基于所述均值和标准差确定用于表示训练样本难易程度的多个分区,每一分区具有对应的交叉熵损失值的权重;确定所述训练样本的特征向量的l2范数所属的分区;将所述训练样本的特征向量的l2范数所属的分区对应的权重作为所述训练样本的交叉熵损失值的权重。5.根据权利要求2所述的神经网络模型的训练方法,其特征在于,基于所述数据队列中所有l2范数的均值和标准差,以及所述训练样本的特征向量的l2范数确定所述训练样本的交叉熵损失值的权重,包括:基于所述数据队列中的l2范数的均值和标准差构建所述l2范数的高斯分布函数;基于所述高斯分布函数和所述数据队列中的l2范数的标准差构建自适应权重函数;将所述训练样本的特征向量的l2范数输入所述自适应权重函数,得到所述训练样本的
交叉熵损失值的权重。6.根据权利要求5所述的神经网络模型的训练方法,其特征在于,所述高斯分布函数如下:其中,z为训练样本的特征向量的l2范数,μ为所述数据队列中l2范数的均值,σ为所述数据队列中l2范数的标准差。7.根据权利要求5所述的神经网络模型的训练方法,其特征在于,所述自适应权重函数如下:其中,z为训练样本的特征向量的l2范数,g(z)为所述高斯分布函数,σ为所述数据队列中l2范数的标准差,t为预设的l2范数阈值。8.根据权利要求1-7任一所述的神经网络模型的训练方法,其特征在于,在获取用于训练神经网络模型的第i批次的数据之前,还包括:获取用于训练神经网络模型的多个批次的数据;利用多个批次的数据对神经网络模型进行初始训练,直至所述神经网络模型满足预设条件。9.根据权利要求8所述的神经网络模型的训练方法,其特征在于,利用多个批次的数据对神经网络模型进行初始训练,直至所述神经网络模型满足预设条件,包括:将第j批次的数据的多个所述训练样本分别输入待训练的神经网络模型中进行处理,得到用于预测所述训练样本属于各类别的第二概率向量;基于所述第二概率向量和所述训练样本的标签计算所述训练样本的交叉熵损失值;计算第j批次的数据中各训练样本的交叉熵损失值之和,得到第二总损失值;判断所述第二总损失是否小于或等于预设值;在所述第二总损失值大于所述预设值时,更新所述神经网络模型的参数,并将第j 1批次的数据的多个所述训练样本分别输入待训练的神经网络模型中进行处理;在所述第二总损失值小于或等于预设值时,确定所述神经网络模型满足预设条件。10.一种神经网络模型的训练装置,其特征在于,包括:数据获取模块,用于获取用于训练神经网络模型的第i批次的数据,所述第i批次的数据包括多个训练样本,所述训练样本标注有表示所述训练样本的类别的标签;第一概率值获取模块,用于将所述第i批次的数据的多个所述训练样本分别输入待训练的神经网络模型中进行处理,得到用于预测所述训练样本属于各类别的第一概率向量;交叉熵损失值计算模块,用于基于所述第一概率向量和所述训练样本的标签计算所述训练样本的交叉熵损失值;l2范数计算模块,用于计算所述训练样本的特征向量的l2范数,所述特征向量为所述神经网络模型提取的,用于映射得到所述概率向量;权重确定模块,用于基于所述特征向量的l2范数确定所述训练样本的交叉熵损失值的
权重;第一总损失值计算模块,用于计算所述第i批次的数据中各所述训练样本的交叉熵损失值乘以权重后的损失值之和,得到第一总损失值;参数更新模块,用于基于所述第一总损失值更新所述神经网络模型的参数。11.一种计算机设备,其特征在于,包括:一个或多个处理器;存储装置,用于存储一个或多个程序;当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如权利要求1-9中任一所述的神经网络模型的训练方法。12.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1-9中任一所述的神经网络模型的训练方法。
技术总结
本发明公开了一种神经网络模型的训练方法、装置、设备及存储介质。本发明实施例提供的神经网络模型的训练方法,基于训练样本的特征向量的L2范数挖掘训练数据中的难样本,为该难样本的交叉熵损失值配置相应的权重,让模型在训练过程中更多地关注到难样本的学习,进而提高神经网络模型在实际应用过程中的泛化性。此外,基于训练样本的特征向量的L2范数挖掘训练数据中的难样本,无需计算训练样本间的相似度和排序操作,节省了计算资源,提高了训练效率。提高了训练效率。提高了训练效率。
技术研发人员:熊凯
受保护的技术使用者:广州视源人工智能创新研究院有限公司
技术研发日:2021.02.08
技术公布日:2022/8/25
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。