技术特征:
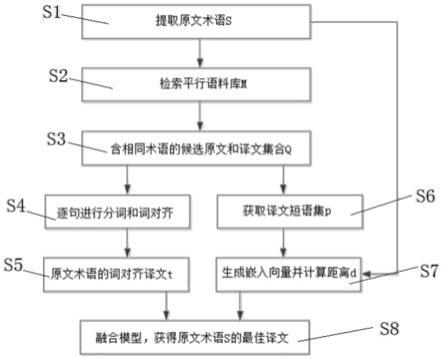
1.一种基于平行语料库的术语译文挖掘方法,其特征在于,具体包括如下步骤:s1、提取待译稿件中的原文术语s;s2、检索平行语料库m:在平行语料库m中对该原文术语s进行字符串搜索;s3、获得含有相同原文术语s的候选原文和译文句子集合q;s4、分词和词对齐:将候选原文和译文句子集合q中的逐句对分别进行分词和词对齐;s5、提取词对齐结果中原文术语s所对应的术语译文t;s6、生成译文短语集:用短语提取算法或工具提取候选译文句子中每个句子的短语片段,去重后形成译文短语集p;s7、生成嵌入向量并计算距离d:通过跨语言嵌入模型分别生成原文术语s和译文短语集p的嵌入向量,利用距离计算公式得出原文术语嵌入向量和译文短语集中每个短语嵌入向量之间的距离d;s8、融合模型:基于s5中所述的词对齐结果和s7中所述的嵌入向量及距离d设计原文术语对应的译文短语的排序模型,获取原文术语s的最佳译文,具体方法如下:a、设原文术语s对应的词对齐结果中的术语译文集合为{t1,t2,...,t
mu
},对该集合中包含相同术语译文作去重处理,获得唯一术语译文集合{t1,t2,...,t
mu
}及每个术语译文的频次集合{ct1,ct2,...,ct
mu
};b、对术语译文的频次集合{ct1,ct2,...,ct
mu
}作归一化处理,得到集合{nct1,nct2,...,nct
mu
},该集合中每个元素依次作为原文术语s对应的词对齐结果中的术语译文集合{t1,t2,...,t
mu
}中相对应元素的可信度;c、设同一原文术语s的嵌入向量与译文短语集合为{p1,p2,...,p
k
}及该集合中每个短语的嵌入向量之间的距离为{d1,d2,...,d
k
};d、将该距离集合中的每个元素取倒数之后再作归一化处理,得到集合{nd1,nd2,...,nd
k
},该集合每个元素依次作为同一原文术语s的嵌入向量与译文短语集合{p1,p2,...,p
k
}中相对应元素的可信度;e、对集合{t1,t2,...,t
mu
}和{p1,p2,...,p
k
}进行合并去重,获得唯一术语译文集合{tp1,tp2,...,tp
r
},该集合为原文术语s的可选译文集合;该可选译文集合中每个元素tp
i
依次作为原文术语s的真实译文的可信度,记为{sim_tp1,sim_tp2,...,sim_tp
r
},其计算方法为:1)若tp
i
属于集合{t1,t2,...,t
mu
}而不属于集合{p1,p2,...,p
k
},则tp
i
的可信度等于集合{t1,t2,...,t
mu
}中对应元素的可信度;2)若tp
i
不属于集合{t1,t2,...,t
mu
}但属于集合{p1,p2,...,p
k
},则tp
i
的可信度等于集合{p1,p2,...,p
k
}中相对应元素的可信度;3)若tp
i
属于集合{t1,t2,...,t
mu
}也属于集合{p1,p2,...,p
k
},则tp
i
的可信度等于集合{t1,t2,...,t
mu
}和集合{p1,p2,...,p
k
}中相对应元素的可信度之和;f、获取上述可信度集合中最大的元素所对应的译文作为原文术语s的最佳译文。2.根据权利要求1所述的一种基于平行语料库的术语译文挖掘方法,其特征在于,s3中所述的分词具体为:选择每种语言相对应的分词工具,将原文术语s作为自定义词语预置到所述分词工具中。3.根据权利要求1所述的一种基于平行语料库的术语译文挖掘方法,其特征在于,s3中
所述的词对齐具体为:先选择基于预训练模型的词对齐工具simalign,然后对候选原文和译文句子集合q中的逐句对进行词对齐,即可提取每个句子中原文术语s所对应的词对齐术语译文。4.根据权利要求1所述的一种基于平行语料库的术语译文挖掘方法,其特征在于,s7中所述的跨语言嵌入模型包括跨语言词嵌入模型,其生成嵌入向量的具体步骤如下:ss1、将原文术语s分词处理,使用facebook的muse项目中预训练的跨语言词嵌入模型生成该原文术语s中各个词语的嵌入向量,将原文术语s中各个词语的嵌入向量相加获得该原文术语s的嵌入向量;ss2、将译文短语集p中的短语分别进行分词处理,使用facebook的muse项目中预训练的跨语言词嵌入模型生成译文短语集p中各个词语的嵌入向量,将译文短语集p中各词语的嵌入向量相加获得该译文短语集p的嵌入向量。5.根据权利要求1所述的一种基于平行语料库的术语译文挖掘方法,其特征在于,s7中所述的跨语言嵌入模型还包括跨语言句嵌入模型,其生成嵌入向量的具体步骤如下:将原文术语s和译文短语集p中的短语均作短句子处理,然后直接使用facebook的laser项目中预训练的跨语言句嵌入模型或ukplab的sentence-transformers跨语言句嵌入模型生成嵌入向量。6.根据权利要求1所述的一种基于平行语料库的术语译文挖掘方法,其特征在于,所述距离计算公式采用余弦距离或欧氏距离计算公式。7.根据权利要求1所述的一种基于平行语料库的术语译文挖掘方法,其特征在于,s6中所述的工具设置为spacy工具,其包括noun_chunks模块,用以提取英语句子的名词短语片段。
技术总结
本发明公开了一种基于平行语料库的术语译文挖掘方法,具体包括如下步骤:S1、提取待译稿件中的原文术语S;S2、检索平行语料库M;S3、获得含有相同原文术语S的候选原文和译文句子集合Q;S4、分词和词对齐;S5、提取词对齐结果中原文术语S所对应的术语译文t;S6、生成译文短语集p;S7、生成嵌入向量并计算距离d;S8、融合模型,获取原文术语S的最佳译文。本发明通过检索平行语料库快速获取原文术语的最佳译文,保证术语译文的准确性和一致性,提高翻译效率。提高翻译效率。提高翻译效率。
技术研发人员:毛红保
受保护的技术使用者:语联网(武汉)信息技术有限公司
技术研发日:2022.03.03
技术公布日:2022/6/1
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。