技术特征:
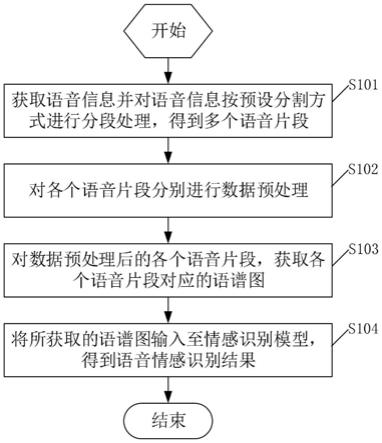
1.一种基于语谱图的语音情感识别方法,其特征在于,包括:获取语音信息并对所述语音信息按预设分割方式进行分段处理,得到多个语音片段;其中,各个所述语音片段之间具备时序关系;对各个所述语音片段分别进行数据预处理;对数据预处理后的各个所述语音片段,获取各个所述语音片段对应的语谱图;其中,不同情绪的语谱图不同;将所获取的语谱图输入至情感识别模型,得到语音情感识别结果;其中,所述情感识别模型通过深度卷积神经网络进行深层情感特征的学习并再通过长短期记忆网络捕获不同语音片段之间的上下文关系进行训练得到。2.根据权利要求1所述的基于语谱图的语音情感识别方法,其特征在于,各个所述语音片段分别进行数据预处理,包括:对各个所述语音片段分别进行预加重处理;对进行预加重处理后的各个语音片段分别进行分帧和加窗。3.根据权利要求2所述的基于语谱图的语音情感识别方法,其特征在于,对各个所述语音片段分别进行预加重处理,包括:采用一阶高通数字滤波器来实现对各个所述语音片段分别进行预加重处理。4.根据权利要求2所述的基于语谱图的语音情感识别方法,其特征在于,对各个所述语音片段分别进行预加重处理所采用的传递函数为:y(k)=x(k)-ax(k-1);其中,a为预加重系数;x(k)为所述语音片段,其中k=0,1,2,
…
,m,y(k)为对x(k)进行预加重处理后输出语音片段。5.根据权利要求2所述的基于语谱图的语音情感识别方法,其特征在于,对进行预加重处理后的各个语音片段分别进行分帧和加窗,包括:对各个所述进行预加重处理后的语音片段,分别采用可移动的有限长度的窗口加权进行分帧;其中,进行分帧方式为交叠分帧。6.根据权利要求5所述的基于语谱图的语音情感识别方法,其特征在于,采用可移动的有限长度的窗口加权进行分帧所采用的公式为:w
f
(n)=w(n)*f(n);其中,f(n)为窗函数,表示加窗时的计算过程;w(n)为原始语音信号;w
f
(n)表示加窗后的语音信号。7.根据权利要求6所述的基于语谱图的语音情感识别方法,其特征在于,所述窗函数为汉明窗函数。8.根据权利要求1所述的基于语谱图的语音情感识别方法,其特征在于,对数据预处理后的各个所述语音片段,获取各个所述语音片段对应的语谱图,包括:对各个数据预处理后的语音片段,进行时频分析处理,得到各个所述语音片段的语谱图。9.根据权利要求1所述的基于语谱图的语音情感识别方法,其特征在于,情感识别模型的构建过程,包括:获取语音训练样本并对所述语音训练样本按预设分割方式进行分段处理,得到多个语
音片段样本;其中,各个语音片段样本之间具备时序关系;对相应的语音片段样本进行数据预处理;以及,对数据预处理后的语音片段样本,获取语谱图样本;将所述语谱图样本输入至所述深度卷积神经网络,以进行深度情感特征的提取,并将所述深度卷积神经网络所提取的特征送入所述长短期记忆网络进行学习,接着通过全连接分类层对最终的语音情感做出划分;得到语音情感识别训练结果;依据所述训练结果与所述语音训练样本的真实结果进行比较,如果比较值满足预设条件,则完成情感识别模型的构建。10.根据权利要求9所述的基于语谱图的语音情感识别方法,其特征在于,所述深度卷积神经网络为vgg16网络;将vgg16网络的各卷积层中卷积核替换成空洞卷积;并在每层卷积之后都添加相应的批量标准化bn层。
技术总结
本发明提供一种基于语谱图的语音情感识别方法,包括:获取语音信息并对语音信息按预设分割方式进行分段处理,得到多个语音片段;其中,各个语音片段之间具备时序关系;对各个语音片段分别进行数据预处理;对数据预处理后的各个语音片段,获取各个语音片段对应的语谱图;将所获取的语谱图输入至情感识别模型,得到语音情感识别结果;也即,将得到的语谱图输入到深度卷积神经网络进行深层情感特征的学习并在此基础上通过长短期记忆网络捕获不同语音片段之间的上下文关系,最终实现对输入语音的情感的识别;同时,通过情感识别模型实现了更好地建模语音上下文之间的时序关系。了更好地建模语音上下文之间的时序关系。了更好地建模语音上下文之间的时序关系。
技术研发人员:董兰芳 胡普照 许广德
受保护的技术使用者:中国科学技术大学
技术研发日:2022.03.02
技术公布日:2022/6/1
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。