技术特征:
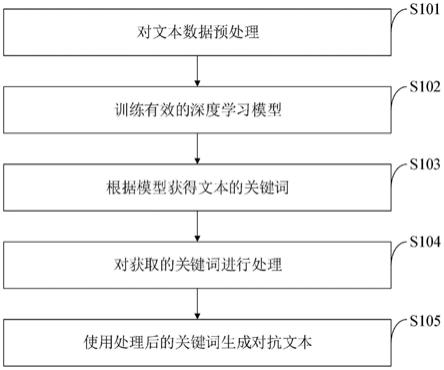
1.一种面向文本的对抗样本生成方法,其特征在于,所述面向文本的对抗样本生成方法对获取的文本数据进行预处理,使用处理好的训练集训练深度学习模型;将数据输入所述深度学习模型,对文本进行计算,获取关键词的权重;将关键词按照权重排序以后选择关键词进行处理生成对应的对抗样本,根据模型识别效果选择结束或者继续修改关键词,获取最终的对抗样本。2.如权利要求1所述的面向文本的对抗样本生成方法,其特征在于,所述面向文本的对抗样本生成方法包括以下步骤:步骤一,对文本数据预处理;步骤二,训练有效的深度学习模型;步骤三,根据模型获得文本的关键词;步骤四,对获取的关键词进行处理;步骤五,使用处理后的关键词生成对抗文本。3.如权利要求2所述的面向文本的对抗样本生成方法,其特征在于,所述步骤一中的对文本数据预处理包括:(1)清理数据,删除掉无用的符号和各种标签;在处理前删除掉无用的空格符号和各种网页标签;(2)为各个类别的数据添加对应的数字标签;对于情感分类样本,正样本标签设置为1,负样本设置为0;对于多分类样本,根据类别数从0开始计数进行标签分类;(3)对文本进行分词,转化为对应的数字token;使用训练集来构造词典,根据单词出现频率从大到小排序;从3开始计数作为对应单词的token;其中0用于长度填充,保证文本具有相同的长度;1用于表示文本的开始,置于文本第一个位置;2用于表示未知符号,代表词典中没有出现的单词。4.如权利要求2所述的面向文本的对抗样本生成方法,其特征在于,所述步骤二中的训练有效的深度学习模型包括:(1)设置词嵌入矩阵参数,设置模型结构超参数,使用lstm构建出模型框架;构建模型时,根据需要设置词向量长度,构建词嵌入矩阵,随机初始化以后作为模型第一层,将离散的单词转化为连续的向量表示;将连续的向量表示输入设置好的lstm和textcnn模型得到模型输出的向量,最后经过线性层和softmax层的转化,将输出向量转化为对应类别的置信度分数;(2)将预处理的数据输入模型,根据深度学习方法对模型进行训练和调节参数;将步骤一中处理好的数据送入模型,通过adam优化器对模型进行优化,不断使用训练集优化模型参数;(3)得到模型的最优参数,固化模型作为后续的使用工具;将训练好的模型参数,通过库函数保存为参数文件用于之后的攻击实验。5.如权利要求2所述的面向文本的对抗样本生成方法,其特征在于,所述步骤三中的根据模型获得文本的关键词包括:(1)将文本进行截取,获得对应单词上文的信息;1)对于文本中的每个单词,去掉单词之后的文本;
对于第i条文本x
i
={w0,w1…
w
n-1
,w
n
},对于单词w
j
的上文信息重要度,去掉第j个单词之后的所有文本,得到x
i
={w0,w1…
w
j
},再将第j个单词去掉得到x
′
i
={w0,w1…
w
j-1
};2)将截取后的文本输入模型,获取模型分数;将得到的x
i
={w0,w1…
w
j
}输入模型得到置信度分数{s0,s1…
s
d
},将得到的x
′
i
={w0,w1…
w
j-1
}输入模型得到置信度分数{s
′0,s
′1…
s
′
d
};3)计算模型分数和对应标签之间的变化,将变化量作为单词的上文权重;根据文本的类别k得到对应的分数变化s
k-s
′
k
来作为对应单词的上文信息;(2)将文本进行截取,获取对应单词下文的信息;1)对于文本中的每个单词,去掉单词之前的文本;对于第i条文本x
i
={w0,w1…
w
n-1
,w
n
},对于单词w
j
的上文信息重要度,去掉第j个单词之前的所有文本,得到x
i
={w
j
,w
j 1
…
w
n
},再将第j个单词去掉得到x
′
i
={w
j 1
…
w
n
};2)将截取后的文本输入模型,获取模型分数;将得到的x
i
={w0,w1…
w
n-1
,w
n
}送入模型得到置信度分数{t0,t1…
t
d
},将得到的x
′
i
={w
j 1
…
w
n
}送入模型得到置信度分数{t
′0,t
′1…
t
′
d
};3)计算模型分数和对应标签的之间的变化,将变化量作为单词的下文权重;根据文本的类别k得到对应的分数变化t
k-t
′
k
来作为对应单词的下文信息;(3)根据文本中对应单词的上下文信息确定关键词;1)根据单词的上文和下文权重,进行加和作为单词的上下文信息权重;使用步骤(1)和步骤(2)的得到的单词对应的上文和下文信息,通过计算(s
k-s
′
k
) (t
k-t
′
k
)来作为单词的上下文信息权重;2)根据上下文信息权重对单词进行从大到小排序;对每条文本中的每个单词来计算上下文信息权重,将单词记录位置坐标,按照从大到小进行排序;3)选取权重高的单词作为关键词进行修改;依次按照权重从大到小的顺序选择关键词。6.如权利要求2所述的面向文本的对抗样本生成方法,其特征在于,所述步骤四中的对获取的关键词进行处理包括:(1)使用同义词对单词进行修改;1)使用glove来对单词进行计算,获取对应的单词向量;使用glove构建向量词典,将单词转化为对应向量;2)在词向量空间中查找和单词向量最接近的作为近义词替换;在glove词典中寻找和关键词词性pos相同的单词,计算和关键词词向量的余弦相似度,选择余弦相似度最大的单词作为当前关键词的同义词替换候选;(2)使用emoji对单词进行修改;将所有表情emoji取出,随机选取两个表情,添加到单词的前后位置;(3)使用词典对单词进行修改;1)使用nltk函数获取单词在文本中的pos含义;使用nltk函数库的词性判断函数获取关键词词性pos;2)在词典中获取单词的释义,选择相同pos的释义作为关键词替换内容;
使用的词典获取关键词的翻译内容,根据关键词的词性pos选择具有相同性质的翻译作为关键词的修改内容。7.如权利要求2所述的面向文本的对抗样本生成方法,其特征在于,所述步骤五中的使用处理后的关键词生成对抗文本包括:(1)获取根据权重排序好的关键词,对关键词进行处理;1)依次取出排序好的关键词,对每一个单词进行关键词处理获取替换内容;根据步骤三获取的关键词,选择当前未被修改的,权重最大的关键词;根据步骤四获取当前关键词的不同替换内容,对同一条文本进行替换,获取相同文本的不同对抗样本;2)将文本进行对应的修改,获取阶段性的对抗文本,输入模型获取模型输出分数;将当前得到的同一样本的不同对抗文本输入模型,得到模型的分类置信度;3)如果模型误分类,结束步骤(1);如果当前已经使得模型误分类,则选择一条成功攻击的文本作为修改好的对抗样本,结束对当前文本的攻击,否则进行下一步骤;4)否则选择对模型输出影响最大的作为当前关键词的修改方案,继续对剩余的关键词进行修改,回到步骤1);对于得到的同一文本的不同样本,选择使模型的输出置信度中对文本分类影响最大的对抗样本,作为现阶段生成的对抗样本;将当前生成的对抗样本作为文本继续转到步骤1),继续选择未修改的单词进行攻击;(2)获取修改后的对抗样本,根据token转化为原始文本;对于得到的文本对抗样本序列,根据token标记转化为原始的文本数据,保存到文本文档中。8.一种实施权利要求1~7任意一项所述的面向文本的对抗样本生成方法的面向文本的对抗样本生成系统,其特征在于,所述面向文本的对抗样本生成系统包括:数据预处理模块,用于对文本数据预处理;模型训练模块,用于训练有效的深度学习模型;关键词获取模块,用于根据模型获得文本的关键词;关键词处理模块,用于对获取的关键词进行处理;对抗文本生成模块,用于使用处理后的关键词生成对抗文本。9.一种计算机设备,其特征在于,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行如下步骤:对获取的文本数据进行预处理,使用处理好的训练集训练深度学习模型;将数据输入所述深度学习模型,对文本进行计算,获取关键词的权重;将关键词按照权重排序以后选择关键词进行处理生成对应的对抗样本,根据模型识别效果选择结束或者继续修改关键词,获取最终的对抗样本。10.一种信息数据处理终端,其特征在于,所述信息数据处理终端用于实现如权利要求8所述的面向文本的对抗样本生成系统。
技术总结
本发明属于人工智能信息安全技术领域,公开了一种面向文本的对抗样本生成方法、系统、设备及终端,该方法包括:对获取的文本数据进行预处理,使用处理好的训练集训练深度学习模型;将数据输入深度学习模型,对文本进行计算,获取关键词权重;将关键词按照权重排序后选择关键词进行处理生成对应的对抗样本,根据模型识别效果选择结束或者继续修改关键词,获取最终的对抗样本。本发明结合了单词级和句子级的方法,同时避免了无效语句的生成,减少了修改的比率,尽可能地不影响文本语义,在保证攻击效果的同时减小了人眼识别的可能性。本发明自适应地选择最优扰动,在保留完整文本语义的同时尽可能减小扰动幅度,以更高的攻击成功率欺骗分类器。骗分类器。骗分类器。
技术研发人员:高海昌 姚舟 常国沁 张宇鸿
受保护的技术使用者:西安电子科技大学
技术研发日:2022.01.02
技术公布日:2022/5/25
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。