技术特征:
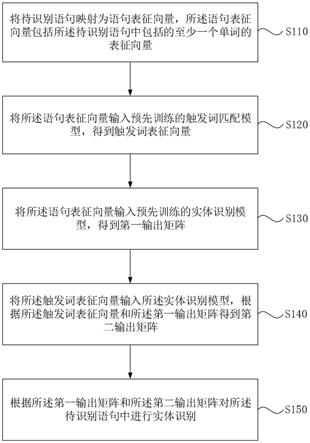
1.基于一致性学习的跨场景持续学习的行人再识别方法,其特征在于,包括下述步骤:将旧场景数据和新场景数据混合,随机抽样后分批次依次并行输入预先设立的旧场景模型和新场景模型,同时得到每一个批次的数据的原始特征;将原始特征输入伪任务数据转换模块,分别得到每一个原始特征经过场景风格转换后对应的旧场景特征和新场景特征;所述伪任务数据转换模块是将一个来自于场景(s)的行人图像变换到场景(t)的分布下,而身份保持不变,从而得到同一个行人在不同的场景下的风格的训练数据;在旧场景特征上计算域内和域间跨场景一致性损失函数,进行伪任务身份辨别性学习;所述跨场景一致性损失函数用于最小化同一个输入样本在不同的伪任务特征变换下不一致性;计算旧场景特征样本和新场景特征样本的两两相似度,进行伪任务知识蒸馏;把新场景特征输入新场景的分类器后计算交叉熵损失函数,进行身份辨别性学习;计算每一个样本对应的旧场景特征和新场景特征距离,进行跨场景一致性学习。2.根据权利要求1所述基于一致性学习的跨场景持续学习的行人再识别方法,其特征在于,所述原始特征包括:旧场景下采集到的数据经过深度卷积神经网络提取的图像特征;以及新场景下采集到的数据经过深度卷积神经网络提取的图像特征。3.根据权利要求1所述基于一致性学习的跨场景持续学习的行人再识别方法,其特征在于,所述伪任务数据转换模块进行场景转换具体为:对于某个特定场景下采集的数据集,每个卷积核对应的批归一化层中的每一个特征通道都会有两个统计统计量,均值μ
(s)
和方差σ
(s)
,计算公式如下:其中,f
i(s)
代表cnn提取的第i个样本样本特征向量,n代表训练一个小批次的样本量,(s)代表当前场景的编号;所述批归一化层是通过滑动平均的方式统计均值和方差以及用反向传播算法更新可学习的缩放系数γ和偏移系数β,将神经网络模型的每一层的所有通道的输出映射到一个高斯分布中,批归一化层的参数反映了一个数据集的样本在各个特征通道上的整体分布特征;对于来自某个场景(s)下的编号为i的样本特征f
i(s)
,使用另一个场景(t)的任务独享批归一化的统计量将其转换到场景(t)下的风格,得到转换后特征f
i(s,t)
,如以下公式所示:其中,γ和β分别代表批归一化层的缩放系数和偏移系数,μ
(t)
和σ
(t)
分别代表场景(t)的任务独享批归一化层的均值统计量和方差统计量;其中,在学习不同的场景时,不同批归一化层使用共享的缩放系数γ和偏移系数β来保持跨域学习中的连续性。4.根据权利要求1所述基于一致性学习的跨场景持续学习的行人再识别方法,其特征在于,所述跨场景一致性损失函数的表达如下:
其中,d是余弦距离度量函数,f
i(s)
是来自场景(s)的编号为i的原始样本特征,n代表训练一个小批次的样本量,p
i
代表数据集中和当前所选样本身份标签相同的图像集合,s代表当前已经学习过的场景数量,stop-grad代表梯度停止回传标志。该损失函数的作用是使得所有身份标签和当前样本相同的样本经过伪任务数据转换模块得到的特征和原始特征f
i(s)
尽可能接近;使用梯度停止模块stop_grad来防止模型在学习新的数据时更新旧的批归一化层的参数,并通过更新网络卷积层参数的方式来使得特征适应新的场景。5.根据权利要求1所述基于一致性学习的跨场景持续学习的行人再识别方法,其特征在于,所述相似度的计算方法如下:在训练过程中的每一个小批次内,使用特征提取网络经过全局池化后的高维特征向量作为样本特征,计算小批次内所有样本的两两相似度,得到相似度矩阵,并以这个矩阵和学生模型的输出的相似度的矩阵的差值作为优化目标,使得学生模型提取的相似度矩阵信息接近于教师模型,从而保留在旧场景里的辨别能力。6.根据权利要求5所述基于一致性学习的跨场景持续学习的行人再识别方法,其特征在于,所述相似度矩阵m的具体计算公式如下:m=[f1,f2,...,f
n
]
t
[f1,f2,...,f
n
]∈r
d
×
n
其中,m是一个样本量为n、特征通道数为d的小批次样本的特征相似度矩阵,f1,f2,...,f
n
分别是编号从1到n的样本特征,t代表矩阵的转置操作;在使用新场景(s)的数据进行训练时,伪任务知识蒸馏学习的表达式为:其中,m
(s-1,i)
在前(s-1)个场景中训练的模型经过任务数据转换模块后得到的特征计算的相似度矩阵,m
(s,j)
在前(s)个场景中训练的模型经过任务数据转换模块后得到的特征计算的相似度矩阵,s是目前已经学习过的场景的数量。7.根据权利要求1所述基于一致性学习的跨场景持续学习的行人再识别方法,其特征在于,所述身份辨别性学习具体为:对于传统的三元组损失函数,每一个样本三元组中的所有样本都是从同一个数据集中采样的,所述样本包括锚样本、正样本和负样本,称为域内身份辨别性学习,如以下公式:其中,f
i(s)
,分别是锚样本、正样本和负样本的特征,n代表训练一个小批次的样本量,s代表当前已经学习过的场景数量,d是余弦距离度量函数,m是三元组损失函数的阈值;利用伪场景数据转换模块对三元组损失函数进行改进,在构造一个样本三元组时,先在数据集a内随机采样一个样本作为锚样本,然后根据锚样本的标签分别采样一个正样本
和负样本,所述正样本是标签和锚样本相同的样本,所述负样本是标签和锚样本不同的样本,并使用伪场景数据转换模块分别对正样本和负样本进行转换,使得正样本和负样本看起来更像是从另一个场景下采集到的和锚样本身份相同和不同的样本,以此来构造跨域的样本三元组,并使用三元组损失函数训练模型,提高模型的跨域泛化能力,将这种优化目称作域间身份辨别性学习,如以下公式:其中,f
i(s)
是锚样本的原始、是正样本和负样本经过数据转换模块后得到的特征,n代表训练一个小批次的样本量,s代表当前已经学习过的场景数量,d是余弦距离度量函数,m是三元组损失函数的阈值;伪任务身份辨别性学习则是由上述的域内身份辨别性学习和域间身份辨别性学习共同组成,具体公式如下:l
pt-id
=l
intra-pt-id
l
inter-pt-id
。8.基于一致性学习的跨场景持续学习的行人再识别系统,其特征在于,应用于权利要求1-7中任一项所述的基于一致性学习的跨场景持续学习的行人再识别方法,其特征在于,包括数据混合模块、伪任务数据转换模块、伪任务身份辨别性学习模块、伪任务知识蒸馏模块、身份辨别性学习模块以及一致性学习模块;所述数据混合模块,用于将旧场景数据和新场景数据混合,随机抽样后分批次依次并行输入预先设立的旧场景模型和新场景模型,同时得到每一个批次的数据的原始特征;所述伪任务数据转换模块,用于分别得到每一个原始特征经过场景风格转换后对应的旧场景特征和新场景特征;所述伪任务数据转换模块是将一个来自于场景(s)的行人图像变换到场景(t)的分布下,而身份保持不变,从而得到同一个行人在不同的场景下的风格的训练数据;所述伪任务身份辨别性学习模块,用于在旧场景特征上计算域内和域间跨场景一致性损失函数,进行伪任务身份辨别性学习;所述跨场景一致性损失函数用于最小化同一个输入样本在不同的伪任务特征变换下不一致性;所述伪任务知识蒸馏模块,用于计算旧场景特征样本和新场景特征样本的两两相似度,进行伪任务知识蒸馏;所述身份辨别性学习模块,用于把新场景特征输入新场景的分类器后计算交叉熵损失函数,进行身份辨别性学习;所述一致性学习模块,用于计算每一个样本对应的旧场景特征和新场景特征距离,进行跨场景一致性学习。9.一种电子设备,其特征在于,所述电子设备包括:至少一个处理器;以及,与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的计算机程序指令,所述计算机程序指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如权利要求1-7中任意一项所述的基于一致性学习的跨场景持续学习的行人再识别方法。
10.一种计算机可读存储介质,存储有程序,其特征在于,所述程序被处理器执行时,实现权利要求1-7任一项所述的基于一致性学习的跨场景持续学习的行人再识别方法。
技术总结
本发明公开了基于一致性学习的跨场景持续学习的行人再识别方法及装置,方法包括:得到每一个批次的数据的原始特征;将原始特征输入伪任务数据转换模块,分别得到每一个原始特征经过场景风格转换后对应的旧场景特征和新场景特征;在旧场景特征上计算域内和域间跨场景一致性损失函数,进行伪任务身份辨别性学习;计算旧场景特征样本和新场景特征样本的两两相似度,进行伪任务知识蒸馏;把新场景特征输入新场景的分类器后计算交叉熵损失函数,进行身份辨别性学习;计算每一个样本对应的旧场景特征和新场景特征距离,进行跨场景一致性学习。本发明能够在先后学习的多个场景下部署不断更新迭代的模型,从而达到降低训练模型和人工维护的成本的目的。工维护的成本的目的。工维护的成本的目的。
技术研发人员:冼宇乔 郑伟诗 葛汶杭 吴岸聪
受保护的技术使用者:中山大学
技术研发日:2022.01.19
技术公布日:2022/4/29
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。