技术特征:
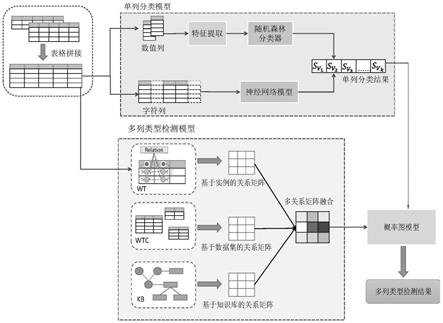
1.一种基于概率图模型的网络表格列类型检测方法,其特征在于:该方法包括以下步骤:步骤1:网络表格拼接:将网络表格数据集中具有相同列标题的网络表格拼接成一张表格,获得拼接表格;步骤2:针对步骤1中获得的拼接表格进行单列分类:首先将所述拼接表格中的列划分为数值型列和字符型列,然后分别针对数值型列和字符型列进行分类;步骤3:基于步骤2的单列分类结果,构建概率图模型挖掘列间隐含的语义关系,实现对整张表的列类型序列的检测。2.根据权利要求1所述的基于概率图模型的网络表格列类型检测方法,其特征在于:所述网络表格数据集的获取方法为:遍历网络表格语料库,在同一网站下寻找具有相同一组列标题的关系型表格形成网络表格数据集。3.根据权利要求1所述的基于概率图模型的网络表格列类型检测方法,其特征在于:利用启发式方法将所述拼接表格中的列划分为数值型列和字符型列。4.根据权利要求1所述的基于概率图模型的网络表格列类型检测方法,其特征在于:针对所述数值型列进行分类的方法为:给定一组彼此不相交的k个知识库类型的集合,表示为{v1,v2,...,v
k
},v
i
∈|v|,其中|v|为知识库中预定义的语义类型集合,将表格数据作为输入,通过基于随机森林的分类器为每一个类别v
i
分配一个实际的概率得分从而得到整列的概率得分为使得目标列的正确类型所在的位置具有最高的概率值得分;所述基于随机森林的分类器是指采用基于统计特征的分类方式,提取数值信息中的均值、方差、中位数、众数、最大值、最小值、峰值、偏度和标准差;提取文字信息中每个字母出现的频率、字符长度的均值与方差,以及具有字符的单元格的占比;再将提取的所有统计量作为特征,利用随机森林算法对分类过程进行建模。5.根据权利要求1所述的基于概率图模型的网络表格列类型检测方法,其特征在于:针对所述字符型列进行分类的方法为:通过融合词嵌入和字符嵌入表达文本语义,使用融合行列信息的单元格嵌入方法,并利用得到的单元格向量表示构建基于深度学习的分类模型,生成单列在各个类型下的概率值。6.根据权利要求5所述的基于概率图模型的网络表格列类型检测方法,其特征在于:针对所述字符型列进行分类的方法具体包括如下步骤:步骤2.3.1:单元格文本向量化:将单元格文本视为一段长度为n的初始文本,使用预训练的词向量模型glove和一维卷积神经网络1d-cnn分别得到单元格文本的单词嵌入向量和字符嵌入向量后,将二者垂直联接产生一个矩阵,接着将该矩阵通过高速神经网络highway-nn得到融合词嵌入和字符嵌入的词向量;步骤2.3.2,单元格嵌入过程:除了目标单元格自身携带的信息外,关注与目标单元格位于同一列和同一行的其他单元格中的信息,以充分学习各种隐式连接;步骤2.3.2.1,列间聚合:针对位于m行n列的目标单元格t
m,n
,聚合n列其他单元格t
m',n
(m'≠m)的上下文信息;步骤2.3.2.2,行间聚合:针对位于m行n列的目标单元格t
m,n
,聚合m行中其他单元格的上下文信息;
步骤2.3.2.3,单元格嵌入表示:将目标单元格自身携带的信息以及与所述目标单元格相关的行间聚合信息和列间聚合信息融合在一起以获取所述目标单元格的全部文本语义表示;步骤2.3.3,字符列分类过程:通过聚合待检测目标列的所有单元格的嵌入获得整列的语义嵌入,利用该嵌入作为输入训练字符列分类模型。7.根据权利要求1所述的基于概率图模型的网络表格列类型检测方法,其特征在于:所述步骤3包括如下步骤:步骤3.1,生成基于数据集的列类型共现关系矩阵p
corr
:统计类型对共同出现的次数得到基于数据集的共现关系矩阵;步骤3.2,生成基于知识库的关系矩阵p
rela
:利用知识库中属性及其值域和定义域间的关系得到基于知识库的关系矩阵;步骤3.3:生成基于实例的关系矩阵p
entity
:通过遍历两列中位于同一行中的单元格对得到基于实例的关系矩阵;步骤3.4:融合上述三种关系矩阵,获得融合后的多关系矩阵q;融合后的多关系矩阵q如下其中α1和α2分别指的是c
i
列和c
j
列各自的单元格实体覆盖率;步骤3.5:构建概率图模型进行网络表格的列类型序列检测,方法为:在整个网络表格上使用线性链条件随机场linear-crf,对相邻列的值之间的相关性进行建模以执行联合预测;其中用单个数值型列在各个类型下的概率值和单个字符型列在各个类型下的概率值来表示状态特征函数φ
single
(c
i
,y
i
);利用多关系矩阵q来表示转移特征函数φ
multi
(y
i-2
,y
i-1
,y
i
,c),其中c表示输入的表格列序列{c1,c2,...,c
n
},转移特征函数依赖于当前列y
i
以及前两列y
i-2
和y
i-1
的状态,用来表示列间关系对语义类型检测的影响。8.根据权利要求7所述的基于概率图模型的网络表格列类型检测方法,其特征在于:所述基于数据集的列类型共现关系矩阵的生成方法为:首先初始化一个矩阵用来记录不同表格中相同列类型对出现的频率;然后遍历已有数据集中已标注好列的语义类型的全部表格,遍历每一个表格的所有列,统计共同出现的列类型对的次数,同时对应的索引位置的值加一;最后统计列类型对的总数并计算得到两种列类型同时出现的频率矩阵p
corr
。9.根据权利要求7所述的基于概率图模型的网络表格列类型检测方法,其特征在于:所述基于知识库的关系矩阵的方法为:对预定义的k个知识库中的类型v进行遍历,利用sparql对每一种类型进行搜索,寻找以该类型为定义域的所有属性并赋值给一集合;接着遍历该集合,寻找每一种属性的值域所属于的类型,如果该类型存在于集合|v|中,则基于知识库的关系矩阵p
rela
中对应的索引位置赋值为对应的概率值。10.根据权利要求7所述的基于概率图模型的网络表格列类型检测方法,其特征在于:所述基于实例的关系矩阵生成方法为:对于c
i
和c
j
两列,通过遍历位于同一行r
m
中的单元格对(t
m,i
,t
m,j
)来寻找潜在的关系,如果通过模糊查找确定知识库中存在与单元格t
m,i
中文本对应的实体e且该实体属于当前类型,则判断t
m,j
是否存在于该实体的属性值中,最后通过多数投票算法得到基于实例的关系矩阵p
entity
。
技术总结
本发明提供一种基于概率图模型的网络表格列类型检测方法,属于语义网中的表格解释领域。该方法包括:将来自同一网站下属于相同模式的表格拼接成一张表格;针对拼接表格进行单列分类:首先将所述拼接表格中的列划分为数值型列和字符型列,然后分别针对数值型列和字符型列进行分类;在单列分类结果的基础上通过构建概率图模型挖掘列间隐含的语义关系,实现对整张表的列类型序列的检测。可以对网络表格中列的语义类型进行检测并取得较好的效果,相对于其它列类型检测方法,准确率均有10%及以上提高。提高。提高。
技术研发人员:申德荣 郭彤 聂铁铮 寇月 于戈
受保护的技术使用者:东北大学
技术研发日:2022.01.21
技术公布日:2022/4/29
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。