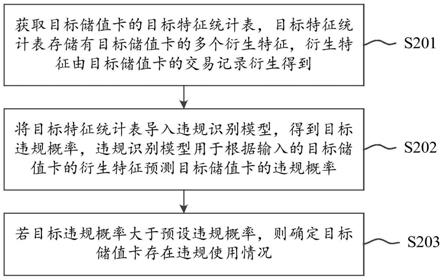
技术特征:
1.一种视频生成方法,其特征在于,所述方法包括:获取多个音频数据;通过自动语音识别系统将每个所述音频数据分解成音素数据,并计算每个所述音素数据的后验概率,得到音素后验概率;获取与所述多个音频数据对应的视频数据;通过3d人脸重建技术提取所述对应的视频数据中每一帧图像数据的人脸表情参数,得到表情特征向量;将所述多个音频数据对应的视频数据,通过递归神经网络将所述表情特征向量以及所述音素后验概率生成目标表情模型;获取待替换的目标视频;通过3d人脸重建技术提取所述对应的视频数据中每一帧图像数据的人脸三维重建模型,得到虚拟图像数据;将所述待替换的目标视频以及所述虚拟图像数据输入至生成式对抗神经网络,得到目标生成模型;将所述目标表情模型以及目标生成模型部署至客户端;通过所述客户端生成目标视频。2.根据权利要求1所述的方法,其特征在于,所述通过所述客户端生成目标视频,包括:获取用户输入的音频数据;将所述用户输入的音频数据输入至所述目标表情模型,得到目标表情;将所述目标表情输入至所述目标生成模型,生成目标图像;将所述目标表情以及所述目标图像通过聚类加速算法,合成对话视频。3.根据权利要求2所述的方法,其特征在于,所述将所述目标表情以及所述目标图像通过聚类加速算法,合成对话视频,包括:通过训练好的分类器分类所述目标表情,得到所述目标表情的类别;根据所述目标表情的类别以及所述目标表情生成合成图像;将所述合成图像替换所述目标图像对应的区域,得到替换后的图像;根据所述替换后的图像以及对应的所述音频数据合成对话视频。4.根据权利要求3所述的方法,其特征在于,所述通过训练好的分类器分类所述目标表情,得到所述目标表情的类别之前,所述方法还包括:获取多个表情特征;通过所述多个表情特征训练初始分类器,得到训练好的分类器;为所述训练好的分类器每个分类结果设置对应的表情,得到表情的类别。5.根据权利要求4所述的方法,其特征在于,所述通过3d人脸重建技术提取所述对应的视频数据中每一帧图像数据的人脸三维重建模型,得到虚拟图像数据,包括:通过3d人脸重建技术提取所述待替换的目标视频,得到3d人脸模型参数组,所述3d人脸模型参数组至少包括身份参数、表情参数、面部纹理参数、姿态参数以及光照参数;删除所述3d人脸模型参数组中的表情参数,得到去除后的模型参数数据;获取待生成的音频,得到待生成的音素后验概率;将所述待生成的音素后验概率输入至所述目标表情模型,得到目标表情参数;
合成所述目标表情参数与所述去除后的模型参数数据,得到所述虚拟图像数据。6.根据权利要求5所述的方法,其特征在于,所述将所述待替换的目标视频以及所述虚拟图像数据输入至生成式对抗神经网络,得到目标生成模型,包括:设置判别器;将多张所述虚拟图像数据输入至所述目标表情模型,得到多张合成后的人脸图像;将所述多张虚拟图像数以及所述待替换的目标视频输入至判别器,得到判别器的识别结果;通过目标表情模型和判别器的对抗训练过程,完成生成式对抗神经网络的训练,得到所述目标生成模型。7.根据权利要求1-6中任一项所述的方法,其特征在于,所述将所述多个音频数据对应的视频数据,通过递归神经网络将所述表情特征向量以及所述音素后验概率生成目标表情模型之前,所述方法还包括:获取多个待训练的音频数据以及对应的待训练表情特征向量;将所述多个待训练的音频数据作为初始长短期记忆神经网络lstm的输入,将所述对应的待训练表情特征向量作为初始lstm的输出,训练所述初始lstm,得到所述目标表情模型。8.一种视频生成装置,其特征在于,所述装置包括:输入输出模块,用于获取多个音频数据;处理模块,用于通过自动语音识别系统将每个所述音频数据分解成音素数据,并计算每个所述音素数据的后验概率,得到音素后验概率;通过所述输入输出模块获取与所述多个音频数据对应的视频数据;通过3d人脸重建技术提取所述对应的视频数据中每一帧图像数据的人脸表情参数,得到表情特征向量;将所述多个音频数据对应的视频数据,通过递归神经网络将所述表情特征向量以及所述音素后验概率生成目标表情模型;通过所述输入输出模块获取待替换的目标视频;通过3d人脸重建技术提取所述对应的视频数据中每一帧图像数据的人脸三维重建模型,得到虚拟图像数据;将所述待替换的目标视频以及所述虚拟图像数据输入至生成式对抗神经网络,得到目标生成模型;将所述目标表情模型以及目标生成模型部署至客户端;通过所述客户端生成目标视频。9.一种计算机设备,其特征在于,所述计算机设备包括:至少一个处理器、存储器和输入输出单元;其中,所述存储器用于存储程序代码,所述处理器用于调用所述存储器中存储的程序代码来执行如权利要求1-7中任一项所述的方法。10.一种计算机存储介质,其特征在于,其中存储计算机指令,当所述计算机指令在计算机上运行时,使得计算机执行如权利要求1-7中任一项所述的方法。
技术总结
本发明涉及软件图像合成领域,提供了一种视频生成方法、装置、设备和存储介质。方法包括:通过自动语音识别系统将每个音频数据分解成音素数据,并计算每个音素数据的后验概率,得到音素后验概率;通过3D人脸重建技术提取对应的视频数据中每一帧图像数据的人脸表情参数,得到表情特征向量;将多个音频数据对应的视频数据,通过递归神经网络将表情特征向量以及音素后验概率生成目标表情模型;获取待替换的目标视频;通过3D人脸重建技术提取对应的视频数据中每一帧图像数据的人脸三维重建模型,得到虚拟图像数据;将待替换的目标视频以及虚拟图像数据输入至生成式对抗神经网络,得到目标生成模型。提高了人脸合成的速度。提高了人脸合成的速度。提高了人脸合成的速度。
技术研发人员:周艺超 李坤 胡景强 刘鹏飞 孙立发 钟静华
受保护的技术使用者:深圳市声希科技有限公司
技术研发日:2020.10.12
技术公布日:2022/4/29
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。