技术特征:
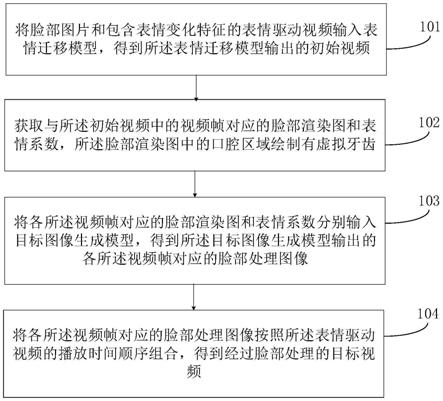
1.一种视频生成方法,其特征在于,所述方法包括:将脸部图片和包含表情变化特征的表情驱动视频输入表情迁移模型,得到所述表情迁移模型输出的初始视频,所述初始视频为将所述表情驱动视频中的表情变化特征与所述脸部图片的脸部特征融合后生成的视频;获取与所述初始视频中的视频帧对应的脸部渲染图和表情系数,所述脸部渲染图中的口腔区域绘制有虚拟牙齿;将各所述视频帧对应的脸部渲染图和表情系数分别输入目标图像生成模型,得到所述目标图像生成模型输出的各所述视频帧对应的脸部处理图像;所述目标图像生成模型用于根据所述表情系数,对所述脸部渲染图的脸部区域进行基于牙齿和纹理的处理;将各所述视频帧对应的脸部处理图像按照所述表情驱动视频的播放时间顺序组合,得到经过脸部处理的目标视频。2.根据权利要求1所述的方法,其特征在于,所述获取与所述初始视频中的视频帧对应的脸部渲染图和表情系数,包括:识别所述初始视频中视频帧的脸部关键点及牙齿关键点;根据各所述视频帧的脸部关键点及牙齿关键点,构建得到与各所述视频帧对应的脸部渲染图和表情系数。3.根据权利要求2所述的方法,其特征在于,根据各所述视频帧的脸部关键点及牙齿关键点,构建得到与各所述视频帧对应的脸部渲染图和表情系数,包括:根据各所述视频帧的脸部关键点进行三维重建,得到所述视频帧对应的三维脸部建模和表情系数;将所述三维脸部建模投影至二维平面,得到脸部建模图;根据所述视频帧的牙齿关键点,确定所述脸部建模图中的口腔区域,并在所述口腔区域中绘制虚拟牙齿,得到所述脸部渲染图。4.根据权利要求1所述的方法,其特征在于,所述方法还包括:获取训练视频,所述训练视频为具有多帧暴露牙齿的视频帧、画面中具有脸部表情变化、画面中头部运动姿态的偏移量小于或等于预设阈值的视频;根据所述训练视频,获取训练配对数据,所述训练配对数据包括:所述训练视频的任一视频帧、与所述任一视频帧对应的脸部渲染图、所述任一视频帧的表情系数;根据所述训练配对数据,对初始图像生成模型进行训练,得到目标图像生成模型。5.根据权利要求4所述的方法,其特征在于,所述根据所述训练视频,获取训练配对数据,包括:从所述训练视频中提取第一视频帧和第二视频帧;获取所述第一视频帧的第一三维脸部建模,以及所述第二视频帧的第二三维脸部建模和表情系数,所述第一三维脸部建模为融合了所述第一视频帧的脸部特征以及所述第一视频帧的表情特征的三维建模,所述第二三维脸部建模为融合了所述第一视频帧的脸部特征以及所述第二视频帧的表情特征的三维建模;将所述第一三维脸部建模和所述第二三维脸部建模共同投影至二维平面,得到所述第二视频帧的脸部建模图;确定所述第二视频帧的脸部建模图中的口腔区域,并在所述口腔区域中绘制虚拟牙
齿,得到所述第二视频帧的脸部渲染图;建立所述第二视频帧、所述第二视频帧的脸部渲染图、所述第二视频帧的表情系数之间的对应关系,得到所述训练配对数据。6.根据权利要求5所述的方法,其特征在于,所述获取所述第一视频帧的第一三维脸部建模,以及所述第二视频帧的第二三维脸部建模和表情系数,包括:分别对所述第一视频帧和所述第二视频帧进行关键点识别,得到所述第一视频帧的第一脸部关键点,以及所述第二视频帧的第二脸部关键点;根据所述第一脸部关键点,获取所述第一视频帧的第一表情系数和第一姿态系数,以及根据第二脸部关键点,获取所述第二视频帧的第二表情系数;根据所述第一视频帧、所述第一表情系数和第一姿态系数进行三维重建,得到所述第一三维脸部建模;根据所述第一视频帧、所述第二表情系数和第一姿态系数进行三维重建,得到所述第二三维脸部建模。7.一种视频生成装置,其特征在于,所述装置包括:迁移模块,被配置为将脸部图片和包含表情变化特征的表情驱动视频输入表情迁移模型,得到所述表情迁移模型输出的初始视频,所述初始视频为将所述表情驱动视频中的表情变化特征与所述脸部图片的脸部特征融合后生成的视频;第一获取模块,被配置为获取与所述初始视频中的视频帧对应的脸部渲染图和表情系数,所述脸部渲染图中的口腔区域绘制有虚拟牙齿;处理模块,被配置为将各所述视频帧对应的脸部渲染图和表情系数分别输入目标图像生成模型,得到所述目标图像生成模型输出的各所述视频帧对应的脸部处理图像;所述目标图像生成模型用于根据所述表情系数,对所述脸部渲染图的脸部区域进行基于牙齿和纹理的处理;生成模块,被配置为将各所述视频帧对应的脸部处理图像按照所述表情驱动视频的播放时间顺序组合,得到经过脸部处理的目标视频。8.一种电子设备,其特征在于,包括:处理器;用于存储所述处理器可执行指令的存储器;其中,所述处理器被配置为执行所述指令,以实现如权利要求1至6中任一项所述的方法。9.一种计算机可读存储介质,其特征在于,当所述计算机可读存储介质中的指令由电子设备的处理器执行时,使得所述电子设备能够执行如权利要求1至6中任一项所述的方法。10.一种计算机程序产品,包括计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1-6任一项所述的方法。
技术总结
本公开提供了一种视频生成方法及装置,包括:得到表情迁移模型输出的初始视频;获取与初始视频中的视频帧对应的脸部渲染图和表情系数,脸部渲染图中的口腔区域绘制有虚拟牙齿;将视频帧对应的脸部渲染图和表情系数分别输入目标图像生成模型,得到目标图像生成模型输出的脸部处理图像;将各所述视频帧对应的脸部处理图像按照所述表情驱动视频的播放时间顺序组合,得到经过脸部处理的目标视频。本公开可以在保证目标视频的牙齿完整的基础上,提升了脸部纹理和牙齿纹理的真实自然程度,大大提升了目标视频的质量。提升了目标视频的质量。提升了目标视频的质量。
技术研发人员:黄旭为 饶强 白云志 刘晓强 叶奎 张国鑫
受保护的技术使用者:北京达佳互联信息技术有限公司
技术研发日:2021.11.30
技术公布日:2022/3/29
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。