技术特征:
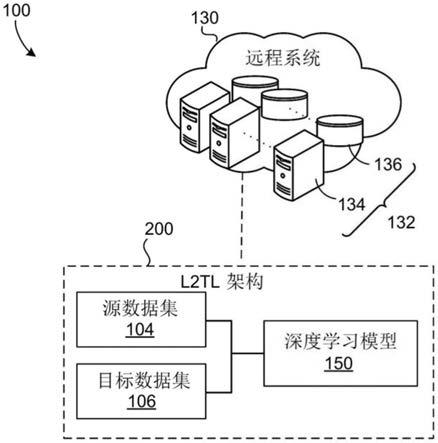
1.一种方法(400),其特征在于,包括:在数据处理硬件(134)处接收源数据集(104)和目标数据集(106);由所述数据处理硬件(134)基于所述源数据集(104)和所述目标数据集(106)来识别深度学习模型(150)的损失函数(201),所述损失函数(201)包括:编码器权重(210);源分类器层权重(202);目标分类器层权重(204);系数(206);和策略权重(208);在被配置为学习所述深度学习模型(150)的权重分配的学习迁移学习(l2tl)架构(200)的多个学习迭代中的每一个学习迭代的第一阶段期间:由所述数据处理硬件(134)应用基于梯度下降的优化来学习使所述损失函数(201)最小化的所述编码器权重(210),所述源分类器层权重(202)和所述目标分类器层权重(204);和由所述数据处理硬件(134)通过对策略模型(209)的动作进行采样来确定所述系数(206);和在所述l2tl架构(200)的所述多个学习迭代中的每一个学习迭代的第二阶段期间,由所述数据处理硬件(134)确定使所述损失函数(201)的评估度量(220)最大化的所述策略权重(208)。2.根据权利要求1所述的方法(400),其特征在于,在执行所述学习迭代的所述第一阶段时,所述策略模型(209)是固定的。3.根据权利要求1或2所述的方法(400),其特征在于,所述策略模型(209)包括基于强化学习的策略模型。4.根据权利要求1-3中任一项所述的方法(400),其特征在于,确定使所述损失函数(201)的所述评估度量(220)最大化的所述策略权重(208)包括使用在所述第一阶段期间学习的所述编码器权重(210)和所述目标分类层权重154。5.根据权利要求1-4中任一项所述的方法(400),其特征在于,所述损失函数(201)的所述评估度量(220)量化所述深度学习模型(150)在目标评估数据集(106')上的性能,所述目标评估数据集(106')包括所述目标数据集(106)中先前未被所述深度学习模型(150)看到的数据样本的子集。6.根据权利要求1-5中任一项所述的方法(400),其特征在于,还包括在所述多个学习迭代中的每一个学习迭代的所述第一阶段期间:由所述数据处理硬件(134)从具有特定大小的所述源数据集(104)采样训练批次的源数据样本;和由所述数据处理硬件(134)从所述训练批次的源数据样本中选择所述源数据样本,所述源数据样本具有n最佳置信度得分,用于训练所述深度学习模型(150)以学习使所述损失函数(201)最小化的所述编码器权重(210),所述源分类器层权重(202)和所述目标分类器层权重(204)。7.根据权利要求1-6中任一项所述的方法(400),其特征在于,还包括,在所述多个学习
迭代中的每一个学习迭代的所述第二阶段期间:由所述数据处理硬件使用目标评估数据集(106')上的策略梯度来训练所述策略模型(209),以计算使所述评估度量(220)最大化的奖励,其中确定使所述损失函数(201)的所述评估度量(220)最大化的所述策略权重(208)是基于所计算的所述奖励。8.根据权利要求1-7中任一项所述的方法(400),其特征在于,其中:所述源数据集(134)包括第一多个图像;并且所述目标数据集(134)包括第二多个图像。9.根据权利要求8所述的方法(400),其特征在于,所述源数据集(134)的所述第一多个图像中的图像的数量大于所述目标数据集(104)的所述第二多个图像中的图像的数量。10.根据权利要求1-9中任一项所述的方法(400),其特征在于,所述l2tl架构(200)包括编码器网络层(152),源分类器层(154)和目标分类器层(156)。11.一种系统(100),其特征在于,包括:数据处理硬件(134);和存储器硬件(136),所述存储器硬件(136)与所述数据处理硬件(134)通信并存储指令,所述指令在所述数据处理硬件(134)上执行时使所述数据处理硬件执行以下操作:接收源数据集(104)和目标数据集(106);基于所述源数据集(104)和所述目标数据集(106)识别深度学习模型(150)的损失函数(201),所述损失函数(201)包括:编码器权重(210);源分类器层权重(202);目标分类器层权重(204);系数(206);和策略权重(208);在被配置为学习所述深度学习模型(150)的权重分配的学习迁移学习(l2tl)架构(200)的多个学习迭代中的每一个学习迭代的第一阶段期间:应用基于梯度下降的优化来学习使所述损失函数(201)最小化的所述编码器权重(210),所述源分类器层权重(202)和所述目标分类器层权重(204);和通过对策略模型(209)的动作进行采样来确定所述系数(206);和在所述l2tl架构(200)的所述多个学习迭代中的每一个学习迭代的第二阶段期间,确定使所述损失函数(201)的评估度量(220)最大化的所述策略权重(208)。12.根据权利要求11所述的系统(100),其特征在于,在执行所述学习迭代的所述第一阶段时,所述策略模型(209)是固定的。13.根据权利要求11或12所述的系统(100),其特征在于,所述策略模型(209)包括基于强化学习的策略模型。14.根据权利要求11-13中任一项所述的系统(100),其特征在于,确定使所述损失函数(201)的所述评估度量(220)最大化的所述策略权重(208)包括使用在所述第一阶段期间学习的所述编码器权重(210)。15.根据权利要求11-14中任一项所述的系统(100),其特征在于,所述损失函数(201)
的所述评估度量(220)量化所述深度学习模型(150)在目标评估数据集(106')上的性能,所述目标评估数据集(106')包括所述目标数据集(106)中先前未被所述深度学习模型(150)看到的数据样本的子集。16.根据权利要求11-15中任一项所述的系统(100),其特征在于,在所述多个学习迭代中的每一个学习迭代的所述第一阶段期间,所述操作还包括:从具有特定大小的所述源数据集(104)采样训练批次的源数据样本;和从所述训练批次的源数据样本中选择所述源数据样本,所述源数据样本具有n最佳置信度得分,用于训练所述深度学习模型(150)以学习使所述损失函数(201)最小化的所述编码器权重(210),所述源分类器层权重(202)和所述目标分类器层权重(204)。17.根据权利要求11-16中任一项所述的系统(100),其特征在于,在所述多个学习迭代中的每一个学习迭代的所述第二阶段期间,所述操作还包括:使用目标评估数据集(106')上的策略梯度来训练所述策略模型(209),以计算使所述评估度量(220)最大化的奖励,其中确定使所述损失函数(201)的所述评估度量(220)最大化的所述策略权重(208)是基于所计算的所述奖励。18.根据权利要求11-17中任一项所述的系统(100),其特征在于,其中:所述源数据集(134)包括第一多个图像;并且所述目标数据集(134)包括第二多个图像。19.根据权利要求18所述的系统(100),其特征在于,所述源数据集(134)的所述第一多个图像中的图像的数量大于所述目标数据集(104)的所述第二多个图像中的图像的数量。20.根据权利要求11-19中任一项所述的系统(100),其特征在于,所述l2tl架构(200)包括编码器网络层(152),源分类器层(154)和目标分类器层(156)。
技术总结
一种方法(400),包括接收源数据集(104)和目标数据集(106),以及基于所述源数据集和所述目标数据集识别深度学习模型(150)的损失函数(201)。损失函数(201)包括编码器权重(210),源分类器层权重(202),目标分类器层权重(204),系数(206)和策略权重(208)。在学习迁移学习(L2TL)架构(200)的多个学习迭代中的每一个学习迭代的第一阶段期间,该方法还包括:应用基于梯度下降的优化来学习使所述损失函数最小化的编码器权重,源分类器层权重和目标分类器权重;以及通过对策略模型的动作进行采样来确定系数(209)。在多个学习迭代中的每一个学习迭代的第二阶段期间,确定使评估度量(220)最大化的策略权重。(220)最大化的策略权重。(220)最大化的策略权重。
技术研发人员:朱林超 托马斯
受保护的技术使用者:谷歌有限责任公司
技术研发日:2020.08.02
技术公布日:2022/3/18
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。