技术特征:
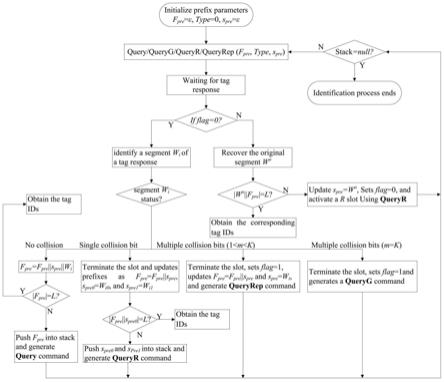
1.一种基于特征组的查询树多标签并发识别方法,其特征在于,所述方法包括:根据标签返回的数据串的特征将整个数据串空间划分为多个互不相交的子集,每个子集包含若干个不同的数据串,子集中的每个数据串可以视为一个完整标签id或部分id,且每个子集都对应的唯一的查询前缀,该前缀的长度固定,不随着碰撞发生的实际位置动态增长,当来源于同一个子集的多个数据串同时返回时,读写器可以在一个时隙中同时识别它们。2.根据权利要求1所述的未知标签识别方法,其特征在于,所述方法包括以下步骤:步骤1:读写器从堆栈中读取帧前缀fpre、时隙前缀spre、标志位flag,初始状态时,帧前缀和时隙前缀均为空串,标志位为0,发送query、queryg、queryr或queryrep查询命令;步骤2:读写器覆盖范围内的待识别标签接收到读写器发送的查询命令,利用自身的匹配电路将提取出的帧前缀fpre与标签自身的编号id进行比较,若匹配,则响应读写器的查询命令,其响应的数据取决于标志位flag,时隙前缀是spre和命令类型;当标志位为0时,标签会将自身id的前k比特同spre相匹配;若匹配结果为真,那么标签会返回匹配的wi段数据,否则等待下一次查询命令;当标志位为1时,标签会将自身id同spre相匹配,并根据spre中的碰撞位置指示信息将m(1<k<m)位的碰撞数据映射成m=2
m
位的映射数据,并返回映射数据给读写器;若m=k,则标签会生成一个2
k
位的数据串并返回给读写器;步骤3:读写器接收标签响应的查询应答;如果在预设时间段t内没有接收到标签响应,则说明读写器覆盖范围内没有待识别的标签;否则,跳转到步骤4;步骤4:读写器根据标志位的不同来解析相应的标签数据;如果标志位为0,读写器首先将fpre更新为fpre||spre,然后解析标签返回的段wi;如果读写器没有在wi中检测到碰撞,则更新fpre为fpre||wi,将查询命令标志设为query命令,并跳转到步骤5;否则,则跳转到步骤6;如果标志位为1,则跳转到步骤7;步骤5:读写器判断此刻fpre的长度是否同标签id长度l相等,若相等,则成功识别当前标签;若不等,则读写器将更新后的fpre、spre参数压入堆栈,并跳转到步骤1;步骤6:如果检测到wi仅有1位碰撞数据,读写器会立刻终止本时隙并将wi中的碰撞位分别替换为为0和1,然后得到wi0和wi1;读写器更新fpre=fpre||spre,spre0=wi0和spre1=wi1,将查询命令标志设为queryr并跳转到步骤5;如果检测到wi中有m(1<m<k)位碰撞数据,读写器会立刻终止本时隙,记录碰撞位置,设置标志位为1,更新fpre=fpre||spre,spre=wi,将查询命令标志设为queryrep命令,并跳转到步骤5;如果检测到wi有k位碰撞数据,读写器会立刻终止本时隙,设置标志位为1,将查询命令标志设为queryg命令,并跳转到步骤1;步骤7:读写器根据收到的标签返回的映射过的数据串和spre中的碰撞信息,恢复出原始的段信息w
o
,并判断w
o
||spre的长度是否等于标签id长度l;若等于,读写器可以识别出相应的标签;否则,读写器更新spre=w
o
,设置标志位为0,将查询命令标志设为queryr命令,并跳转到步骤1;步骤8:重复进行上述步骤,直到完成对所有标签的识别。3.根据权利要求2所述的未知标签识别方法,其特征在于,所述标签的id编码采用曼彻斯特编码或fm0编码方式。4.根据权利要求2所述的未知标签识别方法,其特征在于,所述的步骤1中,首次发送的
是query命令,其后发送的命令取决于查询命令标志。5.根据权利要求2所述的未知标签识别方法,其特征在于,所述的步骤2中,k的取值为2的整数次幂。6.根据权利要求2所述的未知标签识别方法,其特征在于,所述的步骤2中,当1<m<k时,标签返回的映射数据的映射步骤具体包括:步骤2.11:输入m位原始数据,该数据表示为b=b
m-1
b
m-2
...b0,映射后的m(m=2
m
)位数据表示为p=p
m-1
p
m-2
...p0,其中b
i
和p
i
都表示某位二进制数;初始化使得p中的p0位为1,其余位均为0,j为0;步骤2.12:计算r=b
j
×2j
,将p循环左移r位后得到更新的p,并执行j=j 1;步骤2.13:判断j值是否等于m,若是,则终止映射流程并将此时的p输出作为最终的映射数据;否则,跳转到步骤2.12。7.根据权利要求2所述的未知标签识别方法,其特征在于,所述的步骤2中,组查询的生成方法的具体步骤包括:步骤2.21:初始化一个组查询集合q
ini
和一个k维的矢量空间s
k
={0,1}
k
,向量空间中的向量长度均为k。初始状态时,q
ini
为空集合;步骤2.22:随机从s
k
中选取一个向量a0;步骤2.23:从s
k
中选取向量a1,使得a1和a0的汉明距离为1;步骤2.24:将a0和a1压入集合q
ini
中,同时将它们从s
k
中移出;步骤2.25:判断此时q
ini
集合中的元素个数是否超过n(n=2
k
/k),若是,则结束组查询生成流程并输出q
out
=q
ini
,q
out
为最终生成的组查询集合;若否,则跳转到步骤2.26;步骤2.26:从s
k
中选取一个向量b0,使得b0和q
ini
集合中的各个向量的汉明距离大于等于3,然后跳转到步骤2.27;步骤2.27:从s
k
中选取一个向量b1,使得b1和b0的汉明距离等于1;步骤2.28:将b0和b1压入集合q
ini
中,同时将它们从s
k
中移出,并跳转到步骤2.25。8.根据权利要求2所述的未知标签识别方法,其特征在于,所述的步骤2中,当m=k时,标签返回的映射数据的映射步骤具体包括:步骤2.31:输入k位原始数据,该数据表示为b=b
k-1
b
k-2
...b0,映射后的m(m=2
k
)位数据表示为g=g1g2...g
n
,其中n=2
k
/k,b
i
表示某位二进制数,而g
i
表示g中第i段的k比特的数据串;初始化使得g为一个全0的数据串;步骤2.32:标签将自身id同查询命令中的spre相匹配,将匹配后的wi数据串同对应的组查询进行按位异或运算,生成g
i
;步骤2.33:标签用生成的g
i
替换掉g中对应的数据串部分,g中其余的数据位保持不变,然后返回给读写器。9.根据权利要求4所述的未知标签识别方法,其特征在于,所述方法包括:若是query命令,则将命令中的查询前缀与自身id进行比较,如果匹配,就发送匹配后的id的高k位,如果不一致则不响应读写器操作。10.一种基于特征组的查询树多标签并发识别系统,其特征在于,所述系统包括电子设备和阅读器;所述阅读器与电子设备通信连接并用于向工作域内的待识别标签发送或接收信息;所
述电子设备包括至少一个处理器,以及与所述至少一个处理器通信连接的存储器;所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行权利要求1至9中任一项所述的方法。
技术总结
本发明公开了一种基于特征组的查询树多标签并发识别方法及系统,其根据标签返回的数据串的特征将整个数据串空间划分为多个互不相交的子集,每个子集包含若干个不同的数据串,子集中的每个数据串可以视为一个完整标签ID或部分ID,且每个子集都对应的唯一的查询前缀,该前缀的长度固定,不会随着碰撞发生的实际位置动态增长,当来源于同一个子集的多个数据串同时返回时,读写器可以在一个时隙中同时识别它们,消除了传统方法中碰撞时隙无法被充分利用的问题,极大的加快了查询速度,有效的减少了查询次数,提高了查询效率,减少了信息的传输量。的传输量。的传输量。
技术研发人员:苏健 周佳林 庄伟 谈玲
受保护的技术使用者:南京信息工程大学
技术研发日:2021.11.08
技术公布日:2022/3/15
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。