技术特征:
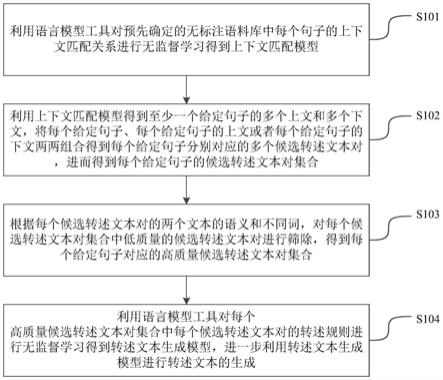
1.一种转述文本生成方法,其特征在于,包括,利用语言模型工具对预先确定的无标注语料库中每个句子的上下文匹配关系进行无监督学习得到上下文匹配模型;利用所述上下文匹配模型得到至少一个给定句子的多个上文和多个下文,将每个所述给定句子、每个所述给定句子的上文或者每个所述给定句子的下文两两组合得到每个所述给定句子分别对应的多个候选转述文本对,进而得到每个所述给定句子的候选转述文本对集合;根据每个所述候选转述文本对的两个文本的语义和不同词,对每个所述候选转述文本对集合中低质量的所述候选转述文本对进行筛除,得到每个所述给定句子对应的高质量候选转述文本对集合;以及,利用所述语言模型工具对每个所述高质量候选转述文本对集合中每个候选转述文本对的转述规则进行无监督学习得到转述文本生成模型,进一步利用所述转述文本生成模型进行所述转述文本的生成。2.如权利要求1所述的转述文本生成方法,其特征在于,在得到所述高质量候选转述文本对集合之后,利用所述语言模型工具对所述高质量候选转述文本对集合以及已标注转述文本对集合中每个文本对的转述规则进行学习得到所述转述文本生成模型,进一步利用所述转述文本生成模型进行所述转述文本的生成。3.如权利要求1所述的转述文本生成方法,其特征在于,所述根据每个所述候选转述文本对的两个文本的语义和不同词,对每个所述候选转述文本对集合中低质量的所述候选转述文本对进行筛除,得到每个所述给定句子对应的高质量候选转述文本对集合的过程包括,利用打分函数根据所述候选转述文本对的两个文本的语义对所述候选转述文本对的匹配性得分以及相似性得分进行打分,并且根据所述候选转述文本对的两个文本中的不同词的个数对所述候选转述文本对的多样性得分进行打分;以及,根据所述匹配性得分、所述相似性得分以及所述多样性得分对每个所述候选转述文本对集合中低质量的所述候选转述文本对进行筛除,得到每个所述给定句子对应的高质量候选转述文本对集合;其中,所述匹配性得分为将所述候选转述文本对对应的所述给定句子作为其上下文时,所述候选转述文本对与其对应的所述给定句子之间的匹配程度得分;所述相似性得分为所述候选转述文本对的两个文本的语义相似程度得分;所述多样性得分为所述候选转述文本对的两个文本的形式差异程度得分。4.如权利要求3所述的转述文本生成方法,其特征在于,所述根据所述匹配性得分、所述相似性得分以及所述多样性得分对每个所述候选转述文本对集合中低质量的所述候选转述文本对进行筛除的过程包括,计算所述匹配性得分、所述相似性得分以及所述多样性得分之和得到所述候选转述文本对的句对得分,若所述句对得分小于预设的得分阈值,则将所述候选转述文本对进行筛除,得到每个所述给定句子对应的高质量候选转述文本对集合。5.如权利要求1所述的转述文本生成方法,其特征在于,
所述无标注语料库包括通过互联网爬取的无标注数据。6.一种转述文本生成装置,其特征在于,包括,上下文匹配模型生成模块,用于利用语言模型工具对预先确定的无标注语料库中每个句子的上下文匹配关系进行无监督学习得到上下文匹配模型的模块;候选转述文本对集合生成模块,用于利用所述上下文匹配模型得到至少一个给定句子的多个上文和多个下文,将每个所述给定句子、每个所述给定句子的上文或者每个所述给定句子的下文两两组合得到每个所述给定句子分别对应的多个候选转述文本对,进而得到每个所述给定句子的候选转述文本对集合的模块;高质量候选转述文本对集合生成模块,用于根据每个所述候选转述文本对的两个文本的语义和不同词,对每个所述候选转述文本对集合中低质量的所述候选转述文本对进行筛除,得到每个所述给定句子对应的高质量候选转述文本对集合的模块;以及,转述文本生成模块,用于利用所述语言模型工具对每个所述高质量候选转述文本对集合中每个候选转述文本对的转述规则进行无监督学习得到转述文本生成模型,进一步利用所述转述文本生成模型进行所述转述文本的生成的模块。7.如权利要求6所述的转述文本生成装置,其特征在于,所述转述文本生成模块,用于利用所述语言模型工具对每个所述高质量候选转述文本对集合以及已标注转述文本对集合中每个文本对的转述规则进行学习得到所述转述文本生成模型,进一步利用所述转述文本生成模型进行所述转述文本的生成的模块。8.一种计算机可读存储介质,其存储有计算机指令,其特征在于,所述计算机指令被操作以执行权利要求1~5中任一项所述的转述文本生成方法。9.一种计算机设备,其包括处理器和存储器,所述存储器存储有计算机指令,其中,所述处理器操作所述计算机指令以执行权利要求1~5任一项所述的转述文本生成方法。
技术总结
本发明公开了一种转述文本生成方法、装置、介质及设备,属于语言处理技术领域,其主要包括包括:对无标注语料库进行无监督学习得到上下文匹配模型;利用上下文匹配模型得到至少一个给定句子的多个候选转述文本对,进而得到每个给定句子的候选转述文本对集合;根据每个候选转述文本对的两个文本的语义和不同词,得到高质量候选转述文本对集合;以及对每个高质量候选转述文本对集合进行无监督学习得到转述文本生成模型,进一步进行转述文本的生成。本发明的应用完全不需要标注数据即可得到高质量的转述文本,减少了对标注数据的依赖,缩短了生成标注数据所需的耗时,减少工作量。减少工作量。减少工作量。
技术研发人员:李晓雅 卢辰鑫 何豪杰 王思宽 王铎
受保护的技术使用者:浙江香侬慧语科技有限责任公司
技术研发日:2021.10.18
技术公布日:2022/3/4
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。