技术特征:
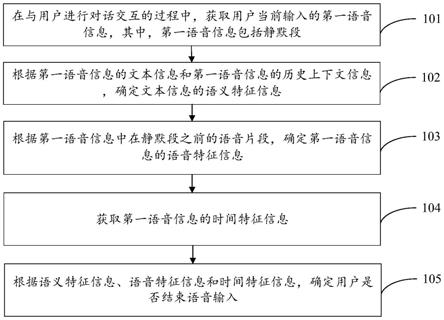
1.一种基于多模态特征的语音对话处理方法,其特征在于,所述方法包括:在与用户进行对话交互的过程中,获取用户当前输入的第一语音信息,其中,所述第一语音信息包括静默段;根据所述第一语音信息的文本信息和所述第一语音信息的历史上下文信息,确定所述文本信息的语义特征信息;根据所述第一语音信息中在所述静默段之前的语音片段,确定所述第一语音信息的语音特征信息;获取所述第一语音信息的时间特征信息;根据所述语义特征信息、所述语音特征信息和所述时间特征信息,确定所述用户是否结束语音输入。2.如权利要求1所述的方法,其特征在于,所述根据所述第一语音信息的文本信息和所述第一语音信息的历史上下文信息,确定所述文本信息的语义特征信息,包括:对所述第一语音信息进行语音识别,以得到所述第一语音信息的文本信息;获取所述第一语音信息的历史上下文信息;将所述文本信息和所述历史上下文信息输入到语义表示模型中,以得到所述文本信息的语义特征信息。3.如权利要求1所述的方法,其特征在于,所述根据所述第一语音信息中在所述静默段之前的语音片段,确定所述第一语音信息的语音特征信息,包括:获取所述第一语音信息中在所述静默段之前的第一预设时间长度的语音片段;按照第二预设时间长度,对所述语音片段进行分段,以得到多段语音片段;提取所述多段语音片段各自对应的声学特征信息,并分别对所述多段语音片段各自对应的声学特征信息进行拼接,以得到所述多段语音频段各自对应的拼接特征;将所述拼接特征输入到深度残差网络中,以得到所述第一语音信息的语音特征信息。4.如权利要求1所述的方法,其特征在于,所述获取所述第一语音信息的时间特征信息,包括:获取所述第一语音信息的语音时长、语速和文本长度;将所述语音时长、所述语速和文本长度输入到预先训练好的多层感知机mlp模型,以得到所述第一语音信息的时间特征信息。5.如权利要求1所述的方法,其特征在于,所述根据所述语义特征信息、所述语音特征信息和所述时间特征信息,确定所述用户是否结束语音输入,包括:将所述语义特征信息、所述语音特征信息和所述时间特征信息输入到多模态融合模型中;根据所述多模态融合模型的输出结果,确定所述用户是否结束语音输入。6.如权利要求1-5任一项所述的方法,其特征在于,还包括:在确定所述用户结束语音输入的情况下,确定所述第一语音信息所对应的第一回复语音信息,并输出所述第一回复语音信息。7.如权利要求1-5任一项所述的方法,其特征在于,还包括:在确定所述用户未结束语音输入的情况下,获取所述用户再次输入的第二语音信息;根据所述第一语音信息和所述第二语音信息,确定对应的第二回复语音信息,并输出
所述第二回复语音信息。8.一种基于多模态特征的语音交互处理装置,其特征在于,所述装置包括:第一获取模块,用于在与用户进行对话交互的过程中,获取用户当前输入的第一语音信息,其中,所述第一语音信息包括静默段;第一确定模块,用于根据所述第一语音信息的文本信息和所述第一语音信息的历史上下文信息,确定所述文本信息的语义特征信息;第二确定模块,用于根据所述第一语音信息中在所述静默段之前的语音片段,确定所述第一语音信息的语音特征信息;第二获取模块,用于获取所述第一语音信息的时间特征信息;第三确定模块,用于根据所述语义特征信息、所述语音特征信息和所述时间特征信息,确定所述用户是否结束语音输入。9.如权利要求8所述的装置,其特征在于,所述第一确定模块,具体用于:对所述第一语音信息进行语音识别,以得到所述第一语音信息的文本信息;获取所述第一语音信息的历史上下文信息;将所述文本信息和所述历史上下文信息输入到语义表示模型中,以得到所述文本信息的语义特征信息。10.如权利要求8所述的装置,其特征在于,所述第二确定模块,具体用于:获取所述第一语音信息中在所述静默段之前的第一预设时间长度的语音片段;按照第二预设时间长度,对所述语音片段进行分段,以得到多段语音片段;提取所述多段语音片段各自对应的声学特征信息,并分别对所述多段语音片段各自对应的声学特征信息进行拼接,以得到所述多段语音频段各自对应的拼接特征;将所述拼接特征输入到深度残差网络中,以得到所述第一语音信息的语音特征信息。11.如权利要求8所述的装置,其特征在于,所述第二获取模块,具体用于:获取所述第一语音信息的语音时长、语速和文本长度;将所述语音时长、所述语速和文本长度输入到预先训练好的多层感知机mlp模型,以得到所述第一语音信息的时间特征信息。12.如权利要求8所述的装置,其特征在于,所述第三确定模块,包括:多模态处理单元,用于将所述语义特征信息、所述语音特征信息和所述时间特征信息输入到多模态融合模型中;确定单元,用于根据所述多模态融合模型的输出结果,确定所述用户是否结束语音输入。13.如权利要求8-12任一项所述的装置,其特征在于,还包括:第一处理模块,用于在确定所述用户结束语音输入的情况下,确定所述第一语音信息所对应的第一回复语音信息,并输出所述第一回复语音信息。14.如权利要求8-12任一项所述的装置,其特征在于,还包括:第三获取模块,用于在确定所述用户未结束语音输入的情况下,获取所述用户再次输入的第二语音信息;第二处理模块,用于根据所述第一语音信息和所述第二语音信息,确定对应的第二回复语音信息,并输出所述第二回复语音信息。
15.一种电子设备,包括:存储器,处理器;所述存储器中存储有计算机指令,当所述计算机指令被所述处理器执行时,实现如权利要求1-7中任一项所述的基于多模态特征的语音对话处理方法。16.一种存储有计算机指令的非瞬时计算机可读存储介质,其特征在于,所述计算机指令用于使所述计算机执行权利要求1-7中任一项所述的基于多模态特征的语音对话处理方法。
技术总结
本申请提出一种基于多模态特征的语音对话处理方法、装置和电子设备,其中,该方法包括:在与用户进行对话交互的过程中,结合用户当前输入的语音信息的文本信息和第一语音信息的历史上下文信息,确定文本信息的语义特征信息,根据第一语音信息中在静默段之前的语音片段,确定第一语音信息的语音特征信息,获取第一语音信息的时间特征信息;根据语义特征信息、语音特征信息和时间特征信息,确定所述用户是否结束语音输入。由此,在与用户进行对话交互的过程中,结合语义特征信息、语音特征信息和时间特征信息,准确确定所述用户是否结束语音输入。语音输入。语音输入。
技术研发人员:王培英 杨久东 陈蒙
受保护的技术使用者:京东科技信息技术有限公司
技术研发日:2021.11.09
技术公布日:2022/2/23
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。